=======================
=======================
=======================
출처: http://lafirr.tistory.com/23
MS Visual Studio 2005 에서 fopen 과 sprintf 함수 사용시 다음과 같은 warning message 가 뜬다.
warning C4996: 'fopen' was declared deprecated
C:\Program Files\Microsoft Visual Studio 8\VC\include\stdio.h(234) : see declaration of 'fopen'
Message: 'This function or variable may be unsafe. Consider using fopen_s instead. To disable deprecation, use _CRT_SECURE_NO_DEPRECATE. See online help for details.'
warning C4996: 'sprintf' was declared deprecated
C:\Program Files\Microsoft Visual Studio 8\VC\include\stdio.h(345) : see declaration of 'sprintf'
Message: 'This function or variable may be unsafe. Consider using sprintf_s instead. To disable deprecation, use _CRT_SECURE_NO_DEPRECATE. See online help for details.'
해석하자면,
'님아 그 함수 불안전함. _s 붙여서 사용해보삼. 자세한 내용은 검색해보던가.' 가 되겠다.
대체 함수가 안전한지 어떤지 당최 뭔 말인지 모르겠지만...
좌튼 안전 (또는 보안) 상의 이유로 secure 를 뜻하는 _s 가 붙은 함수를 사용하라고 하니...
컴파일 시 1개의 warning 도 용납이 안되는 성격인지라,
어쩔 수 없이 fopen_s 와 sprintf_s 를 사용해야겠다.
(물론 warning 은 개 무시하고 그냥 fopen 과 sprintf 를 사용해도 무방하다.)
fopen 의 사용이 아래의 예문과 같다면,
FILE *fp = fopen("test.file", "rb");
fopen_s 의 사용은 다음과 같이 이루어져야 한다.
FILE *fp;
fopen_s(&fp, "test.file", "rb");
주의점 : 1. FILE 선언과 fopen 을 one line 으로 할 수 없다.
2. fopen_s 의 첫번째 인자, 파일 포인터를 전달할때 꼭 & 를 붙여야 한다.
sprintf 의 사용이 아래의 예문과 같다면,
sprintf(cOut, "%s", cIn);
sprintf_s 의 사용은 아래와 같이 이루어져야 한다.
/* 수정합니다.
과객 DEMIAN 님의 댓글처럼 sprintf_s 의 두번째 인자는 buffer 의 최대 크기를 의미합니다.
*/
sprintf_s( char *_DstBuf, size_t_SizeInBytes, const char *_Format, ... )
ex)
char cOut[256];
sprintf_s( cOut, 256, "%s", cIn );
sprintf_s(cOut, string_length, "%s", cIn);
주의점 : string_length 는 문자열의 길이를 나타내는데,
예를 들어서 'abc' 일 경우 string_length = 3 이 아니라, string_length = 4 가 된다.
이 때, 숫자가 1 이라도 다를 경우 error 가 발생하고 문자열이 뭔지도 모를 경우가 태반이라
편하게 사용하기 위해서는 아래와 같은 방법을 사용하면 된다.
sprintf_s(cOut, strlen(cIn)+1, "%s", cIn);
아 물론, "%s_ver.1" 과 같은 경우,
sprintf_s(cOut, strlen(cIn)+1+6, "%s_ver.1", cIn);
과 같이 고정 문자열 길이를 더해주면 ... 될까? (안해봤다...)
되겠지 -_-;
warning 없는 코딩을 추구하는 것,
쓸데 없는 것일려나....( -.-)y~~~ 휴우....
=======================
=======================
=======================
출처: http://argc.tistory.com/60
error C4996: 'fopen': This function or variable may be unsafe. Consider using fopen_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
위와같은 에러 발생 시,
include 전에 아래와 같은 코드 한줄 추가
#define _CRT_SECURE_NO_DEPRECATE
예)
#define _CRT_SECURE_NO_DEPRECATE #include #include #include
혹은,
fopen이나 scanf등 비슷한 함수 사용시 fopen_s, scaf_s등 s 함수를 써주면 해결.
출처: http://argc.tistory.com/60 [SPRING :: NOTE]
=======================
=======================
=======================
출처: https://kldp.org/node/149231
오류는
1>------ 빌드 시작: 프로젝트: 연습, 구성: Debug Win32 ------
1> dasjd.c
1>c:\users\1-생활실206\documents\visual studio 2010\projects\연습\dasjd.c(30): warning C4996: 'fopen': This function or variable may be unsafe. Consider using fopen_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
1> c:\program files\microsoft visual studio 10.0\vc\include\stdio.h(234) : 'fopen' 선언을 참조하십시오.
1>LINK : fatal error LNK1123: COFF로 변환하는 동안 오류가 발생했습니다. 파일이 잘못되었거나 손상되었습니다.
========== 빌드: 성공 0, 실패 1, 최신 0, 생략 0 ==========
이거네요... vc++6.0 에서도 잘 돌아가는걸로 알고있습니다.. 여기서만 안되는건지... 뭐가 문젠지 모르겠씁니다 ㅜㅜ
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
open 함수가 안전하지 않을 수 있으니 fopen_s를 대신 사용하라는 경고입니다. 경고를 무시하려면 _CRT_SECURE_NO_WARNINGS 옵션을 사용하라는데
코드를 보니 그냥 매크로로 _CRT_SECURE_NO_WARNINGS를 정의하셨군요. 아래 링크 참조하세요. VS2013으로 테스트했는데 잘 됩니다.
http://blog.naver.com/ambidext/220161992052
http://blog.naver.com/nawoo/220185206383
저는 이렇게 생각했습니다.
=======================
=======================
=======================
헤더 파일
[언어 자료구조 알고리즘/C11 표준 라이브러리 함수] - STDIO.H
errno_t fopen_s(FILE **pfp, const char *path,const char *mode); 파일 스트림을 여는 함수
입력 매개 변수 리스트
pfp 연 파일 스트림을 설정할 FILE *형식 변수의 주소
path 절대 경로 혹은 상대 경로
mode rwba+의 조합 문자열, fopen과 같습니다.
반환 값
성공하면 0, 실패하면 에러 값
C11 표준에서는 FILE 구조체인 struct _iobuf의 내부 멤버를 숨기고 있습니다.
개발자에 의해 직접 멤버에 접근하는 것을 방지하여 안전성을 도모하고 있습니다.
그리고 fopen 함수의 반환 값을 첫 번째 입력 인자로 FILE 포인터 변수의 주소(FILE 포인터의 포인터)를 받아 설정하는 fopen_s 함수를 제공합니다.
사용 예
//C언어 표준 라이브러리 함수 사용법 가이드
//errno_t fopen_s(FILE **pfp, const char *path,const char *mode); 파일 스트림을 여는 함수
//원본 파일을 복사하여 복사한 파일 내용을 type 명령어로 콘솔 화면에 출력
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv)
{
FILE * sfp, *dfp;
if (argc != 3)//command line에서 인자를 잘못 사용
{
printf("사용법: %s [출력 파일명] [원본 파일명]", argv[0]);
return;
}
//원본 파일 읽기 모드로 열기
fopen_s(&sfp,argv[2], "r");
if (sfp == NULL)//열기 실패일 때
{
perror("fopen 실패");//에러 메시지 출력
return;
}
//출력 파일 쓰기 모드로 열기
fopen_s(&dfp,argv[1], "w");
while (!feof(sfp)) //원본 파일 스트림이 EOF를 만나지 않았다면 반복
{
putc(getc(sfp), dfp);//원본 파일에서 하나의 문자을 읽어온 후 출력 파일에 쓰기
}
//파일 스트림 닫기
fclose(sfp);
fclose(dfp);
printf("파일 복사 성공\n");
{//확인을 위하여 출력 파일 내용을 콘솔 화면에 출력
char cmd[256];
sprintf_s(cmd, sizeof(cmd), "type %s", argv[1]);
system(cmd);
}
printf("\n");
return 0;
}
명령줄
>ex_fopen output.txt input.txt
input.txt 내용
이 책에서는 C99와 C11 표준을 포함하여 다양한 표준 라이브러리 함수들의 사용법을 소개할 것입니다.
이 책은 단순한 문법을 전달하기 보다는 표준 라이브러리 함수가 어떠한 역할을 하고 어떻게 사용하는지에 초점을 맞출 것입니다.
이를 통해 보다 효과적으로 C언어로 프로그래밍할 수 있기를 기대합니다.
출력
파일 복사 성공
이 책에서는 C99와 C11 표준을 포함하여 다양한 표준 라이브러리 함수들의 사용법을 소개할 것입니다.
이 책은 단순한 문법을 전달하기 보다는 표준 라이브러리 함수가 어떠한 역할을 하고
어떻게 사용하는지에 초점을 맞출 것입니다.
이를 통해 보다 효과적으로 C언어로 프로그래밍할 수 있기를 기대합니다.
새로 만들어진 output.txt 내용
이 책에서는 C99와 C11 표준을 포함하여 다양한 표준 라이브러리 함수들의 사용법을 소개할 것입니다.
이 책은 단순한 문법을 전달하기 보다는 표준 라이브러리 함수가 어떠한 역할을 하고 어떻게 사용하는지에 초점을 맞출 것입니다.
이를 통해 보다 효과적으로 C언어로 프로그래밍할 수 있기를 기대합니다.
출처: http://ehclub.co.kr/770 [언제나 휴일]
=======================
=======================
=======================
출처: http://mooyou.tistory.com/33
fopen_s 함수를 이용하여 파일을 읽는 코드와 저장하는 코드입니다.
//
// fopen_s 파일읽기
//
errno_t err;
FILE *fp;
if( (err = fopen_s(&fp, "file_path", "rt")) != 0 )
{
AfxMessageBox(_T("File open error!"));
return false;
}
fscanf_s(fp,"format", ...); // 사용법은 c의 scanf함수와 동일
fclose(fp)
//
// fopen_s 파일저장
//
errno_t err;
FILE *fp;
if( (err = fopen_s(&fp, "file_path", "wt")) != 0 )
{
AfxMessageBox(_T("File open error!"));
return ;
}
fprintf_s(fp,"format", ...); // 사용법은 c의 printf함수와 동일
fclose(fp)
특히 fscanf_s 함수를 사용하여 문자열을 읽어올때 c의 scanf함수 사용법과 동일하지 않습니다.
이와 관련하여 다음 링크를 참조하세요.
출처: http://mooyou.tistory.com/33 [무유 블로그]
=======================
=======================
=======================
출처: http://shaeod.tistory.com/278
※요약
fgets : 개방된 파일에서 텍스트 문자열을 한 줄씩 읽습니다.
※특징
- 파일 끝이나 개행 문자까지 읽는다.
- 라인 끝(CR/LF)을 읽으면 개행 문자 '\n'으로 변환한다.
- string 끝에 NULL문자를 추가한다.
※함수 원형 및 설명
| 1 2 3 4 5 |
char *fgets( char *string, int n, FILE *stream ); //string : 파일 데이터를 읽어서 저장할 버퍼의 포인터 //n : 읽을 최대 문자의 수 +1, 읽은 문자열의 끝에 NULL이 추가 //stream : 개방된 FILE 구조체의 포인터 //반환값 : 읽은 string의 포인터, 더 읽을 파일이 없거나 에러 시 NULL 포인터 |
※예제
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#include <stdio.h> int main( ) { FILE *pFile = NULL; pFile = fopen( "d:\\Text.txt", "r" ); if( pFile != NULL ) { char strTemp[255]; char *pStr; while( !feof( pFile ) ) { pStr = fgets( strTemp, sizeof(strTemp), pFile ); printf( "%s", strTemp ); printf( "%s", pStr ); } fclose( pFile ); } else { //에러 처리 } return 0; } |
※txt파일 내용
첫 번째줄입니다.
두 번째줄입니다.
세 번째줄입니다.
=======================
=======================
=======================
출처: http://ra2kstar.tistory.com/147
C++에서 파일 입출력 하는 방법이다.
C 에서는 주로 FILE을 이용해서 파일 입출력을 하지만, C++에서는 fstream의 ofstream 과 ifstream 클래스를 이용하면 쉽게 구현이 가능하다.
사용방법
파일 쓰기
ofstream 객체명("파일명");
파일 읽기
ifstream 객체명("파일명");
또는
ifstream 객체명
객체명.open("파일명"); or 객체명.open("파일명" , open모드|open모드);
open 모드 열거형 상수
| ios::in | 읽기만 가능한 형태로 파일 오픈 |
| ios::ate | 파일을 오픈하면서 파일포인터를 끝부분으로 옮김 |
| ios::app | 출력하는 데이터가 항상 파일의 끝에 기록 |
| ios::trunc | 오픈하고자 하는 파일이 이미 있는경우, 기존의 파일을 삭제하고 다시 만듬 |
| ios::nocreate | file open 을 시도하지 않고 file의 존재 여부만 판단. file이 존재하지 않을 경우 에 러를 발생 (파일을 생성하지 않음) |
| ios::noreplace | nocreate 와 반대. file이 존재하면 에러를 발생 |
| ios::binary | 바이너리 파일 모드로 오픈 |
ex)
ifstream fileopen;
fileopen.open("open.txt" , ios::in|ios::binary);
다음 소스는 간단하게 0-9 까지의 숫자를 쓴 파일을 생성하고, 그 파일을 읽어들이는 소스이다.
여기서 파일을 읽어들일때는 getline() 한수를 사용했는데, getline()은 계행문자를 입력의 끝으로 인식하여 정해진 길이만큼 한줄 전체를 읽어들인다.
소스코드
#include <fstream>
#include <iostream>
using namespace std;
#define MAX_SIZE 1000
char inputString[MAX_SIZE];
int main(){
// 파일 입력 (쓰기)
ofstream outFile("output.txt");
for(int i = 0 ; i < 10 ; i++){
outFile << i << endl;
}
outFile.close();
//파일 출력 (읽기)
ifstream inFile("output.txt");
while(!inFile.eof()){
inFile.getline(inputString, 100);
cout << inputString << endl;
}
inFile.close();
return 0;
}
출력화면
출처: http://ra2kstar.tistory.com/147 [초보개발자 이야기.]
=======================
=======================
=======================
출처: http://wer3799.tistory.com/43
파일 입출력을 할때는 스트림 파일이라는 표준화된 형태를 만들어서 입출력을 수행하게 된다.
스트림만들어서 사용하는 이유는 1.여러 입출력 장치들이 있기때문에 표준적인 방법을 만든다는 것과.
2.프로그램에서 데이터를 처리하는 속도,입출력장치에서의 속도의 차이가 있는데 이것을 조정하기 위해서 라고 한다.
우선 파일을 읽기 위해서는 스트림 파일을 만들어야 한다.
스트림 파일을 만들기 위해서는 fopen함수를 사용하면 된다.
FILE* fp; //파일구조체 포인터를 하나 만듬
fopen_s(&fp, "Map.obj", "r"); //파일구조체 포인터 fp에 Map.obj의 내용을 집어넣는다. 맨뒤에 "r"은 읽기모드를 뜻한다. (쓰기모드도 있다.)
이렇게 하면 파일구조체 fp에 텍스트 파일의 정보가 저장된다. 그리고 fopen함수 호출 후 파일을 읽지 못했을 경우에 fp에는 NULL이 들어가게 된다.
이를 통해서 파일 읽기를 성공했는지 실패했는지 판별 할 수 있다.
사용이 끝난 파일은 fclose함수를 이용해 스트림파일을 제거한다. (안정성을 위해서..)
fclose(fp);
파일 개방이 끝나면 이제 해당파일을 이용해 입출력을 하면 된다.
문자를 가져오는 함수들 :
int fgetc(FILE* ); 는 파일에서 하나의 문자를 가져온다.
예를들어 Game.txt 라는 텍스트 파일이 있고 텍스트 파일 안에는 Shooting 이라고 적혀있다. 여기서 문자를 읽으려면 다음과 같이 하면 된다.
FILE* fp;
char buff;
fopen_s(&fp, "Game.txt", "r"); //읽기모드
if(fp==NULL) //정상적으로 파일을 읽었는지 검사
{
cout<<"파일 개방 실패"<<endl;
return ;
}
buff = fgetc(fp);
cout<<buff<<endl;
fclose(fp);
이렇게 하면 S가 정상적으로 출력된다.
한번 fgets함수를 호출하고 그 이후에 호출되는 fgets함수는 버퍼에 데이터가 없을때까지 읽게된다. 따라서
buff = fgetc(fp);
cout<<buff<<endl; 를 한번 더 호출하면 S다음글자인 h가 호출 될 것이다.
그리고 버퍼의 끝에 도달하면 fgetc함수는 -1을 리턴한다 (EOF) 이를통해 다음과 같이 전문을 출력할 수 있다.
while(1)
{
buff = fgetc(fp);
cout << buff << endl;
if (buff == EOF)break;
}
fgetc 함수가 문자를 문자단위로 입력받는 함수라면
fgets함수는 문자를 줄 단위로 입력받는 함수이다.
FILE* fp;
char buff[10];
open_s(&fp, "Game.txt", "r"); //읽기모드
if (fp == NULL) //정상적으로 파일을 읽었는지 검사
{
cout << "파일 개방 실패" << endl; return;
}
fgets(buff, sizeof(buff), fp);
cout << buff << endl;
이런식으로 사용하면 한줄의 내용인 Shooting이 출력된다.
마찬가지로 한번 더 호출하면 두번째 줄의 내용이 출력될 것이다.
이함수들과 더불어 문자열 자르는 함수나(strtok)
sscanf_s같은 함수를 이용하면 buff에 들어있는 원하는 방법으로 활용 할 수 있게된다.
간단한 예를 들자면
character.txt라는 파일이 있다. 내용은
HP 30
MP 50
여기서 HP값 30과 MP값 50를 int 값으로 얻어 오려면 다음과 같이 하면 될 것이다.
FILE* fp;
char buff[10];
int Hp;
int Mp;
fopen_s(&fp, "character.txt", "r"); //읽기모드
if (fp == NULL) //정상적으로 파일을 읽었는지 검사
{
cout << "파일 개방 실패" << endl;
return;
}
while (!feof(fp)) //한줄씩 읽어내려감
{
fgets(buff, sizeof(buff), fp);
char* Data;
if(buff[0]=='H'&&buff[1]=='P')
{
Data = strtok(buff, " ");
while (Data = strtok(NULL, " "))
{
Hp = atoi(Data);
}
}
if (buff[0] == 'M'&&buff[1] == 'P')
{
Data = strtok(buff, " ");
while (Data = strtok(NULL, " "))
{
Mp = atoi(Data);
}
}
}
cout << Hp << endl;
cout << Mp << endl;
출처: http://wer3799.tistory.com/43 [개인공부,기록]
=======================
=======================
=======================
출처: http://2gotto.tistory.com/28
How to Read Big File in C++
C++ 대용량 파일 읽기
레퍼런스를 찾으면 보통 다음과 같이 코드를 작성할 것을 권한다.
void fileread(const char* _path){
pFile = fopen(_path, "rb");
//read size of file
fseek(pFile, 0, SEEK_END);
long lSize = ftell(pFile);
fseek(pFile, 0, SEEK_SET);
char *buff = (char*)malloc(sizeof(char)*lSize);
unsigned int result;
//read all
result = fread(&buff[totnum],sizeof(char),lSize,pFile);
if (result != lSize) {
cout << "not read all file" << endl;
}
//처리
free(buff)
}
그러나 이번에 진행했던 프로젝트는 검색 엔진을 만드는 것인데 55만 개의 문서를 인덱싱한 파일의 크기는 2.4GB였다. 이렇게 파일 용량이 큰 경우 fread로 한 번에 읽는 것은 불가능하다. fread는 얼만큼 읽었는지 return하므로 read가 끊긴 부분부터 다시 읽기 시작하면 다음과 같이 대용량 파일을 한 번에 읽을 수 있다.
void fileread(const char* _path){
pFile = fopen(_path, "rb");
//read size of file
fseek(pFile, 0, SEEK_END);
long lSize = ftell(pFile);
fseek(pFile, 0, SEEK_SET);
char *buff = (char*)malloc(sizeof(char)*lSize);
unsigned int totnum = 0;
unsigned int curnum = 0;
//read all big file
while ((curnum = fread(&buff[totnum], sizeof(char), lSize - totnum, pFile)) > 0) {
totnum += curnum;
}
if (totnum != lSize) {
cout << "not read all file" << endl;
}
}
그렇다면 왜 파일을 한 번에 읽어야 할까?
이유는 간단한데, 파일 입출력을 하는 것은 매우 느려서 한 글자씩, 한 줄씩 읽도록 프로그램을 짤 경우 비효율적인 프로그램을 만들게 되기 때문이다.
출처: http://2gotto.tistory.com/28 [생각하는 일상]
=======================
=======================
=======================
츌처: https://www.npteam.net/442
출처 : http://blog.naver.com/muggae/50009557767
파일내용을 그대로 메모리에 올려서 메모리에 올려진 파일내용을 수정하고 수정된 내용을 디스크 파일에 쓴다. 순서는 다음과 같다.
- 파일 오픈 hF=CreateFile("test.txt")
- 파일 내용을 메모리에 올린다 hMapF=CreateFileMapping(hF)
- 메모리에 올려진 첫번째 주소를 얻는다. pF=MapViewOfFile(hMapF)
- 첫번째 주소로 메모리 내용을 조작한다.
- 중간중간에 변경된 내용을 강제로 디스크에 쓰게만든다. FlushViewOfFile(pF)
- 해제. UnmapViewOfFile(pF);
- 해제. CloseHandle(hMapF);
- 파일 닫기. CloseHandle(hF);
<예제>
#include <windows.h>
#include <stdio.h>
int main(int argc, char **argv)
{
HANDLE hFile, hMapFile;
DWORD dwFileSize;
char *pFile, *pFileTemp;
hFile = CreateFile( "test.txt", GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);
// hFile = CreateFile( "test.txt", GENERIC_READ, FILESHARE_READ, NULL, OPEN_EXISTING, 0, NULL); // 읽기
dwFileSize = GetFileSize( hFile, NULL );
hMapFile = CreateFileMapping( hFile, NULL, PAGE_READWRITE, 0, 0, NULL );
// hMapFile = CreateFileMapping( hFile, NULL, PAGE_READONLY, 0, 0, NULL ); // 읽기
if( hMapFile == NULL )
{
printf( "CreateFileMapping() fail" );
CloseHandle( hFile );
return 1;
}
pFile = (char*)MapViewOfFile( hMapFile, FILE_MAP_ALL_ACCESS, 0, 0, 0 );
//pFile = (char*)MapViewOfFile( hMapFile, FILE_MAP_READ, 0, 0, 0 );
// Do SomeThing...
pFileTemp = pFile;
for(UINT i = 0; i < dwFileSize; i++ )
{
*pFileTemp = (*pFileTemp + 1);
pFileTemp++;
}
// SomeThing End..
//메모리 내용을 강제로 파일에 쓴다.
FlushViewOfFile( pFile, 0 );
UnmapViewOfFile( pFile );
CloseHandle( hMapFile );
CloseHandle( hFile );
return 0;
}
=======================
=======================
=======================
출처: https://www.npteam.net/440
대용량의 파일 순식간에 읽기
1.요약
10M 이상이 되는 파일을 빠르게 읽는 방법을 알아보기로 합니다.
2.본문
<대용량 파일 읽기 (빠르게...)>
v 파일 읽기는 자주 사용하실 것인데.. CFile::Read를 사용하면.. 10MB정도 되는 파일을 읽으면 무진장 오래 걸려서.. 메모리 맵 파일을 이용한 파일 읽기 방법을 올려 들립니다..
많은 예제가 나온것으로 알지만.. 혹시... 도 몰라서..
BOOL OpenFiles(LPCSTR lpszPathName)
{
DWORD dwFileSize;
HANDLE hFile, hFileMap;
LPVOID lpvFile;
hFile = ::CreateFile( lpszPathName, GENERIC_READ , 0, NULL
OPEN_EXISTING, FILE_ATTRIBUTTE_NORMAL, NULL );
if( hFile == INVALID_HANDLE_VALUE )
{
// 여기에서 에러 메세지 처리..
}
dwFileSize = ::GetFileSize(hFile, NULL);
hFileMap = CreateFileMapping( hFile, NULL, PAGE_WRITECOPY, 0,
dwFileSize, NULL );
if( hFileMap == NULL )
{
CloseHandle(hFile);
//여기에서 에러 메세지 처리..
}
lpFile = MapViewOfFile( hFileMap, FILE_MAP_COPY, 0, 0, 0 );
if( lpFile == NULL )
{
CloseHandle( hFile );
CloseHandle( hFileMap );
//여기에서 에러 처리
}
}
이렇게 하면.. 대용량의 파일을 빠르게 읽을 수 있습니다..
제가 시간을 한번 제어 봤는데.. 4초 안에 끊나더군요..
흠.. 그리고 여기에 나온 함수는 Help에서 정확한 내용을 보세요.
.
<대용량 파일 빠르게 읽기 2>
메모리 맵파일을 이용한 방법외에 간단한 방법이 있어서 말씀드려볼까 합니다.
어려운 루틴은 아니고요, 그냥 도스용 시절에 사용했던 fread함수를 사용한 것입니다.
물론 fread대신 다른 파일 읽기 함수를 사용해도 됩니다.
다만 사용자 편의를 위해서 추가로 만들어진 파일함수들은(파일함수뿐만 아니라 다른 것들도 마찬가지...) 사용하긴 편하겠지만, 속도가 무척 느린 문제가 있습니다.
char *ReadFile( char *FileName )
{
FILE *fp;
int FileSize;
char *buffer;
try
{
fp = fopen( FileName, "rb" );
if( !fp ) throw "File Not Found!";
FileSize = filelength( fileno(fp) );
buffer = new char [FileSize+1];
fread( buffer, FileSize, 1, fp );
*(buffer + FileSize) = 0;
fclose( fp );
return buffer;
}
catch( char *msg )
{
printf( msg );
return NULL;
}
}
위의 try ~ catch구분은 중요한것은 아니고요, 대부분의 프로그래머분들이 예외처리를 함에 있어서 일반적인 C스타일로 일일히 에러메시지를 코딩하더군요.
그래서 혹시나 도움이 될까 해서 try ~ catch구분을 사용해보았습니다. 어려운건 아니니깐 try ~ catch를 사용하면 코딩이 훨씬 간단해질꺼예요. ^^
그리고 위의 파일읽기 함수를 fopen/fread등을 사용했는데, 이건 C를 시작하는 분들 께 조금이나마 이해가 쉽도록 도스에서 사용하던 함수를 사용했습니다. 물론 이 함수들은 윈도우즈에서도 그대로 사용할수 있습니다.
원래 도스에서 fread는 한블럭최대크기가 64k로 제한됩니다.
따라서 64k씩 나누어서 파일을 읽어들여야 하는데, 윈도우즈에서는 그냥 한번에 읽을 수 있더군요. ^^
10메가 정도 읽어들이는데 있어서, 펜133의 컴에서 약 3초미만으로 걸리는 것 같습니다.
=======================
=======================
=======================
binary/text 파일을 안전하고 빠르게 복사하는 방법을 찾아보고 있는데요 제가 이때까지 찾아낸 것 외에 다른 분들은 어떻게 쓰는지 궁금합니다
또 제 코드에 문제가 있으면 알려주세요
ANSI-C
#include <iostream> #include <cstdio> // fopen, fclose, fread, fwrite, BUFSIZ #include <ctime> using namespace std; int main() { clock_t start, end; start = clock(); // 기본 BUFSIZE는 8192 bytes // 1024의 배수는 blocksize에 딱 들어맞고, 큰 값일수록 system call을 줄여 속도가 빨라집니다. // size_t BUFFER_SIZE = 4096 char buf[BUFSIZ]; size_t size; FILE* source = fopen("from.ogv", "rb"); FILE* dest = fopen("to.ogv", "wb"); while (size = fread(buf, 1, BUFSIZ, source)) { fwrite(buf, 1, size, dest); } fclose(source); fclose(dest); end = clock(); cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n"; cout << "CPU-TIME START " << start << "\n"; cout << "CPU-TIME END " << end << "\n"; cout << "CPU-TIME END - START " << end - start << "\n"; cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n"; return 0; }
POSIX ("The C programming language"에서 K&R이 썼던 방법)
#include <iostream> #include <fcntl.h> // open #include <unistd.h> // read, write, close #include <cstdio> // BUFSIZ #include <ctime> using namespace std; int main() { clock_t start, end; start = clock(); // BUFSIZE defaults to 8192 // 1024의 배수는 blocksize에 딱 들어맞고, 큰 값일수록 system call을 줄여 속도가 빨라집니다. // size_t BUFFER_SIZE = 4096 char buf[BUFSIZ]; size_t size; int source = open("from.ogv", O_RDONLY, 0); int dest = open("to.ogv", O_WRONLY | O_CREAT /*| O_TRUNC/**/, 0644); while ((size = read(source, buf, BUFSIZ)) > 0) { write(dest, buf, size); } close(source); close(dest); end = clock(); cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n"; cout << "CPU-TIME START " << start << "\n"; cout << "CPU-TIME END " << end << "\n"; cout << "CPU-TIME END - START " << end - start << "\n"; cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n"; return 0; }
KISS-C++-Streambuffer
#include <iostream> #include <fstream> #include <ctime> using namespace std; int main() { clock_t start, end; start = clock(); ifstream source("from.ogv", ios::binary); ofstream dest("to.ogv", ios::binary); dest << source.rdbuf(); source.close(); dest.close(); end = clock(); cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n"; cout << "CPU-TIME START " << start << "\n"; cout << "CPU-TIME END " << end << "\n"; cout << "CPU-TIME END - START " << end - start << "\n"; cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n"; return 0; }
C++ copy 알고리즘
#include <iostream> #include <fstream> #include <ctime> #include <algorithm> #include <iterator> using namespace std; int main() { clock_t start, end; start = clock(); ifstream source("from.ogv", ios::binary); ofstream dest("to.ogv", ios::binary); istreambuf_iterator<char> begin_source(source); istreambuf_iterator<char> end_source; ostreambuf_iterator<char> begin_dest(dest); copy(begin_source, end_source, begin_dest); source.close(); dest.close(); end = clock(); cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n"; cout << "CPU-TIME START " << start << "\n"; cout << "CPU-TIME END " << end << "\n"; cout << "CPU-TIME END - START " << end - start << "\n"; cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n"; return 0; }
OWN-BUFFER-C++
#include <iostream> #include <fstream> #include <ctime> using namespace std; int main() { clock_t start, end; start = clock(); ifstream source("from.ogv", ios::binary); ofstream dest("to.ogv", ios::binary); // file size source.seekg(0, ios::end); ifstream::pos_type size = source.tellg(); source.seekg(0); // allocate memory for buffer char* buffer = new char[size]; // copy file source.read(buffer, size); dest.write(buffer, size); // clean up delete[] buffer; source.close(); dest.close(); end = clock(); cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n"; cout << "CPU-TIME START " << start << "\n"; cout << "CPU-TIME END " << end << "\n"; cout << "CPU-TIME END - START " << end - start << "\n"; cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n"; return 0; }
LINUX (커널 2.6.33이상)
#include <iostream> #include <sys/sendfile.h> // sendfile #include <fcntl.h> // open #include <unistd.h> // close #include <sys/stat.h> // fstat #include <sys/types.h> // fstat #include <ctime> using namespace std; int main() { clock_t start, end; start = clock(); int source = open("from.ogv", O_RDONLY, 0); int dest = open("to.ogv", O_WRONLY | O_CREAT /*| O_TRUNC/**/, 0644); sendfile(dest, source, 0, stat_source.st_size); close(source); close(dest); end = clock(); cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n"; cout << "CPU-TIME START " << start << "\n"; cout << "CPU-TIME END " << end << "\n"; cout << "CPU-TIME END - START " << end - start << "\n"; cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n"; return 0; }
실행 환경:
GNU/LINUX (Archlinux) Kernel 3.3 GLIBC-2.15, LIBSTDC++ 4.7 (GCC-LIBS), GCC 4.7, Coreutils 8.16 RUN LEVEL 3 사용 (멀티유저, 네트워크, 터미널, gui는 없음) INTEL SSD-Postville 80 GB, 50%사용 중
Program설명UNBUFFEREDBUFFERED
| ANSI C | fread/frwite | 490,000 | 260,000 |
| POSIX | K&R, read/write | 450,000 | 230,000 |
| FSTREAM | KISS, Streambuffer | 500,000 | 270,000 |
| FSTREAM | Algorithm, copy | 500,000 | 270,000 |
| FSTREAM | OWN-BUFFER | 500,000 | 340,000 |
| SENDFILE | native LINUX, sendfile | 410,000 | 200,000 |
=======================
=======================
=======================
출처: http://blog.daum.net/andro_java/799
C++ 파일 복사, BUFSIZ - 안전하고 빠르게 복사
/ 2016.11.24. 최초 작성
1) 출처 :
파일을 안전하고 빠르게 복사하는 방법 http://hashcode.co.kr/questions/762/%ED%8C%8C%EC%9D%BC%EC%9D%84-%EC%95%88%EC%A0%84%ED%95%98%EA%B3%A0-%EB%B9%A0%EB%A5%B4%EA%B2%8C-%EB%B3%B5%EC%82%AC%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
위 페이지에 여러 개의 소스가 있다.
2) ANSI-C
그 중 ANSI-C 소스를 가져다가 수정한 것이다.
3) 수정
- stdafx : Visual Studio 2015 권장
- fopen > fopen_s : Visual Studio 2015에서 fopen 에러
- TIME(SEC) > TIME(MILISEC)
4) 테스트
24,441바이트 파일 복사(0~15 밀리초)
264,092바이트 파일 복사(0~2 밀리초)
처음 테스트할 때 15 나온 것이 내가 무엇을 잘못 본 것인가 싶을 정도이다.
반복 테스트에서 0~2 범위를 벗어나는 경우가 보이지 않는다.
5) BUFSIZ
참고 : http://jinsolkim.kr/220159184331
BUFSIZ Linux ETC / LINUX
2014.10.23. 11:01
BUFSIZ
/usr/include/stdio.h 에 있는 매크로이다.
적당히 큰 임의의 버퍼 사이즈를 제공한다.
?64bit 컴퓨터에서 8192 = 2^13 이다.
[출처] BUFSIZ|작성자 LEO JINSOL KIM
6) 수정된 소스
#include "stdafx.h"
#include <iostream>
#include <cstdio> // fopen, fclose, fread, fwrite, BUFSIZ
#include <ctime>
using namespace std;
int main() {
clock_t start, end;
start = clock();
// 기본 BUFSIZE는 8192 bytes
// 1024의 배수는 blocksize에 딱 들어맞고, 큰 값일수록 system call을 줄여 속도가 빨라집니다.
// size_t BUFFER_SIZE = 4096
char buf[BUFSIZ];
size_t size;
FILE* source;
fopen_s(&source, "D:\\chang.txt", "rb");
FILE* dest;
fopen_s(&dest, "D:\\chang2.txt", "wb");
while (size = fread(buf, 1, BUFSIZ, source)) {
fwrite(buf, 1, size, dest);
}
fclose(source);
fclose(dest);
end = clock();
// cout << "CLOCKS_PER_SEC " << CLOCKS_PER_SEC << "\n";
cout << "CPU-TIME START " << start << "\n";
cout << "CPU-TIME END " << end << "\n";
cout << "CPU-TIME END - START " << end - start << "\n";
// cout << "TIME(SEC) " << static_cast<double>(end - start) / CLOCKS_PER_SEC << "\n";
cout << "TIME(MILISEC) " << (end - start) << "\n";
return 0;
}
=======================
=======================
=======================
출처: http://genesis8.tistory.com/41
'파일'은 디스크에 '정보가 저장되는 단위'
프로그램은 실행에 필요한 코드를 가지지만.. '모든 데이터'를 가지는 것은 아니다.
실행 파일의 크기에는 제약이 존재하기 때문에 모든 정보를 다 가질 수 없으며,
때문에 큰 정보는 외부의 파일에 두고 실행 중에 읽어서 사용하는 방법을 쓴다.
ex) 게임 프로그램은 사운드나 이미지를 분리된 파일에 두고 필요할 때 읽어들여 출력한다.
또한 프로그램의 작업 결과를 영구히 저장하기 위해서도 파일을 사용한다.
메모리는 전원이 없으면 기억된 내용을 잃어 버리기 때문에, 정보 저장을 위해서는 하드디스크에 기록되어야한다.
파일은 CPU나 메모리에 존재하지 않으며, 하드 디스크나 CD-ROM등의 외부 미디어에 기록되어 있다.
응용 프로그램이 이런 기계적 장치를 움직여 파일에 액세스 하는 것은 비효율 적이며, 현실적으로 불가능하다 그래서 운영체제나 컴파일러가 파일을 액세스할 수 있는 함수를 제공. 프로그램은 이 함수를 호출해서 원하는 파일을 읽고 쓴다.
파일 액세스의 방법
1. 고수준 입출력 스트림 사용 : C 라이브러리가 제공하는 방식. 성능은 떨어지지만 사용하기 쉬움. 표준에 의해 형태가 고정되어 이식에 유리.
2. 저수준 파일 핸들 : C 라이브러리가 제공하는 파일 입출력 방법. 대규모의 데이터를 다루기 편리.
3. c++의 스트림 객체. ifstream , ofstream 등의 입출력 객체와 멤버 함수를 사용하여 파일을 액세스.
4. 운영 체제가 제공하는 API 함수. 디스크의 관리 주체가 운영체제이므로, 운영체제는 응용 프로그램을 위해 관련 API 함수를 제공한다. CreateFile , ReadFile등..
5. 클래스 라이브러리가 제공하는 파일 액세스 객체의 사용. MFC의 경우 CFile 클래스를 제공
1,2는 너무 오래되었고 기능이 떨어짐.
윈도우즈 환경에서는 API 함수가 제일 좋고, MFC라면 Cfile이 편리하다.
C언어의 파일 지원.
C에서 제공하는 것은 고수준과 저수준 두가지가 있다. 분류는 사람에게 가까운 (쓰기 쉬운) 것이 기준이다.
| 고수준 | 저수준 | |
| 버퍼 사용 | 사용 | 메모리로 직접 읽어들임 |
| 입출력 대상 | 스트림 | 파일 핸들 |
| 속도 | 느리다. | 빠르다. |
| 문자 단위 입출력 | 가능 | 가능하지만 비효율적이다. |
| 난이도 | 비교적 쉽다 | 조금 어렵다 |
| 세밀한 조작 | 어렵다. | 가능하다. |
고수준과 저수준의 가장 큰 차이점은 버퍼를 쓰는 가 그렇지 않은 가 하는 점이다.
나머지 차이점은 버퍼의 사용 유무에 따라 파생되는 특성이다.
버퍼는 파일로 부터 입출력 되는 데이터를 잠시 저장하는 메모리 영역이다.
하드 디스크는 메모리보다 느리기 때문에 하드 디스크에 액세스 하는 회수를 줄이기 위해 버퍼를 사용한다.
(물을 한바가지씩 옮기는 것과 양동이에 담아서 옮기는 차이)
고수준보다 저수준이 빠르긴 하지만 요즘은 성능이 좋아 차이를 느끼기 힘들다.
고수준 파일 입출력 -
스트림(stream)이란 흐름을 의미한다. 물이 흘러가듯이 바이트들이 순서대로 입출력 되는 논리적 장치를 스트림이라한다.
대부분의 운영체제가 화면(console) , 프린터 등을 스트림으로 다루며, 파일과 같은 방법으로 입출력한다. 각 장치들
서로 제어하는 방법이 다르지만 스트림이라는 논리적으로 동등한 장치로 표현되기 때문에 동일한 방법으로 입출력할 수 있다.
스트림의 현재 상태는 FILE 구조체에 기억된다. 이 구조체는 stdio.h에 다음과 같이 정의되어 있으며 구조체의 멤버들은 운영체제에 따라 조금씩 달라지기도 한다.
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
파일에 액세스 하려면 먼저 대상을 열어야(open)한다. open은 입출력 준비를 하는것
FILE *fopen(const char *filename, const char *mode);
이와 같이 사용하며, 경로가 생략 되거나 파일 이름 등만 전달하면.. 현재 디렉토리에서 찾는 상대경로가 된다.
절대경로는 "C:\\Data\\File.Ext" 와 같이 쓸 수 있으며 \는 확장 문자열 이므로 \\로 전달해야한다.
| 모드 | 설명 |
| r | 읽기 전용으로 파일을 연다. 이 모드로 연 파일은 읽을 수만 있으며 데이터를 기록하지는 못한다. 만약 파일이 없을 경우 에러가 리턴된다. |
| w | 쓰기 위해 파일을 연다. 이 모드로 연 파일은 쓰기만 가능하며 읽지는 못한다. 도스나 윈도우즈의 파일은 쓰기 전용 속성이 없지만 스트림은 쓰기 전용 상태로 열 수있다. 파일이 없으면 새로 만들고 이미 존재한다면 기존의 파일은 지워진다. |
| a | 추가를 위해 파일을 연다. 추가란 파일의 끝에 다른 정보를 더 써 넣는다는 뜻이다. 이 모드로 연 파일은 오픈 직후에 FP가 파일의 끝으로 이동한다. 파일이 없으면 새로 만든다. |
| r+ | 읽고 쓰기가 가능하도록 파일을 연다. 파일이 없을 경우 에러가 리턴된다. |
| w+ | 읽고 쓰기가 가능하도록 파일을 연다. 파일이 없을 경우 새로 만든다. |
| a+ | 읽기와 추가가 가능하도록 파일을 연다. 파일이 없으면 새로 만든다. |
이 외에도 텍스트 파일이면 t를 붙일 수 있고, ex) wt (텍스트 쓰기)
이진 파일이면 b를 붙인다. ex) wb
fopen은 에러가 발생하면 NULL 값을 리턴한다. 따라서 아래와 같이 에러 처리를 할 수 있다.
f=fopen("c:\\test","rb");
if (f == NULL) {
printf_s("파일이 존재하지 않습니다.");
}
int fclose(FILE *stream);
마지막으로, 다 사용한 후에는 반드시 닫아주어야한다.
char *fgets(char *string, int n, FILE *stream);
fgets는 파일에서 문자열을 읽어들이는데, fgets는 개행문자를 만날 때 까지 혹은 버퍼의 길이만큼 문자열을 읽어들이므로..
이 함수를 반복해서 호출하면 텍스트 파일을 '줄' 단위로 읽는 것이 가능하다. 읽는 도중에 에러가 발생하거나, 끝인 경우 NULL을 리턴한다.
int fputs(const char *string, FILE *stream);
fputs는 첫 번째 인수로 전달된 문자열을 파일로 출력하는데, 중간에 개행 문자가 있다해도 한꺼번에 출력한다.
만약 중간에 NULL 종료 문자를 만나면 그 앞까지만 출력한다.
임의 접근
스트림은 다음 입출력할 파일의 위치를 항상 기억하고 있는데. 이 위치를 FP(file position)이라고 한다.
최초로 열 때는 파일의 선두를 가리키다가, 읽거나 쓸 때는 액세스한 만큼 뒤로 이동한다. (순차접근)
그래서 fget만 계속 써도 끝까지 읽을 수 있는 것이다.
그렇지 않고 읽고 싶은 곳을 읽는 것이 임의접근이라 하는데, fp를 원하는 위치로 옮긴 후 액세스 함수를 호출하면 된다.
int fseek(FILE *stream, long offset, int origin);
대상 스트림 , 어디로 옮길 것인지 , 어디를 기준으로 옮기는 지? (기준은 아래와 같이 3가지가 있다.)
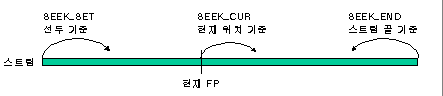
다음 두 함수는 현재 FP를 조사하거나 리셋한다.
long ftell(FILE *stream);
void rewind(FILE *stream);
ftell은 스트림의 현재 FP를 조사하는데 커서의 wherex, wherey 함수에 대응된다고 할 수 있다. rewind는 FP를 파일 선두로 보내는데 fseek(f,0,SEEK_SET)과 동일한 명령이다. 파일의 처음부터 다시 액세스하고 싶을 때 이 함수를 사용한다. fseek, ftell과 똑같은 동작을 하는 fgetpos, fsetpos라는 함수들도 있다.
기정의 스트림.
고수준 입출력 함수들은 스트림을 대상으로 입출력을 수행한다 스트림이란 파일뿐만 아니라 키보드나 모니터처럼 바이트를 연속적으로 입출력하는 물리적인 장치까지 다룰 수 있다.
키보드나 화면을 스트림으로 관리하고자 할 때 미리 정의되어 있는 표준 스트림을 사용한다.
| 이름 | 설명 | 버퍼 |
| stdin | 표준 입력 | 사용 |
| stdout | 표준 출력 | 미사용 |
| stderr | 표준 에러 | 미사용 |
파일 핸들
저수준 파일입출력 방법은 OS가 파일을 관리하는 방법과 같다. 고수준은 파일을 스트림으로 취급하는 반면, 저수준은 파일을 핸들로 관리하는 것이 특징이다. 좀 더 어렵지만 성능은 더 좋다. 저수준 파일 입출력에는 먼저 대상을 열어 핸들을 얻어야한다.
int _open(const char *filename, int oflag [,int pmode] );
int _close(int fd);
oflag 인수에는 파일을 어떤 모드로 열 것인지를 지정하는 다음과 같은 플래그들을 준다
| 플래그 | 설명 |
| _O_BINARY | 이진 모드로 연다. |
| _O_TEXT | 텍스트 모드로 연다. |
| _O_CREAT | 새로 파일을 만들며 파일이 이미 존재하면 아무 것도 하지 않는다. |
| _O_RDONLY | 읽기 전용으로 연다. |
| _O_RDWR | 읽기 쓰기가 가능하도록 연다. |
| _O_WRONLY | 쓰기 전용으로 연다. |
| _O_TRUNC | 파일을 열고 크기를 0으로 만든다. _O_CREAT와 함께 사용될 경우 새로 파일을 만든다. |
| _O_APPEND | FP를 파일 끝으로 보낸다. |
| _O_RANDOM | 캐시를 임의 접근 방식으로 최적화한다. |
| _O_SEQUENTIAL | 캐시를 순차 접근 방식으로 최적화한다. |
| _O_SHORT_LIVED | _O_CREAT 플래그와 함께 사용되며 임시 파일을 만든다. |
| _O_TEMPORARY | _O_CREAT 플래그와 함께 사용되며 파일을 닫을 때 삭제한다. |
| _O_EXCL | _O_CREAT 플래그와 함께 사용되며 파일이 이미 존재할 경우 에러를 리턴한다. |
저수준 파일 액세스에는 다음 함수를 사용한다.
int _read(int fd, void *buffer, unsigned int count);
int _write(int fd, const void *buffer, unsigned int count);
일에서 바이트를 읽은 후 FP는 읽은만큼 뒤로 자동으로 이동한다. 만약 파일 끝이거나 파일 핸들이 무효하다면 -1이 리턴된다.
저수준 입출력 함수도 고수준과 마찬가지로 다음 액세스할 위치를 FP로 가리키는데 FP를 옮기면 임의의 위치를 액세스할 수 있다. 다음 두 함수는 저수준 파일 입출력의 임의 접근 함수들이다.
long _lseek(int fd, long offset, int origin);
long _tell(int fd);
파일 관리.
파일 입출력 함수들은 파일에 저장된 데이터를 읽고 쓰는 역할이었지만, 파일 관리 함수들은 저장된 데이터를 대상으로 하는 것이 아니라, '파일 그 자체'를 대상으로 한다.
[파일 확인]
int _access(const char *path, int mode);
이 함수는 파일의 보안 상태. 쓰기가 가능한 지, 읽기 전용인지 등을 확인한다.
mode에 조사할 상태를 지정하는데 0은 존재, 2는 쓰기, 4는 읽기를 나타낸다. 청한 허가 상태를 가지면 이 함수는 0을 리턴. 그렇지 않으면 -1을 리턴한다.
[파일 삭제]
int remove(const char *path);
int _unlink(const char *filename);
둘 다 이름이 다를 뿐, 파일을 삭제한다.
[파일명 변경]
int rename(const char *oldname, const char *newname);
변경하고자 하는 파일의 이름과 새로 설정할 파일의 이름을 인수로 지정하면 된다
[파일 속성 변경]
int _chmod(const char *filename, int pmode);
파일의 속성을 바꾸는 함수로, 읽기 전용으로 만들 것인지 아니면 읽기 쓰기가 가능한 파일로 만들 것인지를 변경한다.
- 파일 검색 -
파일 검색 함수는 특정한 조건에 맞는 파일을 검색한다. ex) a로 시작하고 확장자가 txt인 모든 파일 (a*.txt)을 찾는다. 아래의 세 개의 함수가 있다.
long _findfirst( char *filespec, struct _finddata_t *fileinfo );
int _findnext( long handle, struct _finddata_t *fileinfo );
int _findclose( long handle );
findefirst 함수의 fliespec 인수로 검색식을 주면, 족너에 맞는 첫 번째 파일을 찾아 fileinfo 구조체에 검색된 파일의 정보를 채우고, 검색 핸들을 리턴한다. 조건에 맞는 파일이 하나도 없을 경우 -1을 리턴한다._finddata_t 구조체는 io.h 헤더 파일에 다음과 같이 정의되어 있다.
struct _finddata_t {
unsigned attrib;
time_t time_create; /* -1 for FAT file systems */
time_t time_access; /* -1 for FAT file systems */
time_t time_write;
_fsize_t size;
char name[260];
};
_findfirst 함수로 첫 번째 검색을 한 후 _findnext 함수로 조건이 일치하는 다음 파일을 계속 찾을 수 있으며 _findnext가 -1을 리턴할 때까지 반복하면 조건에 맞는 모든 파일을 다 찾게 된다. 검색이 끝나면 _findclose 함수로 검색 핸들을 닫아 검색을 종료한다.
즉 세 함수는 한 세트라고 봐야한다.
파일 디렉토리 관리
폴더라는 이름으로 더 친숙한 파일 디렉토리다. 파일을 담는 그릇의 역할을 한다.
int _chdir(const char *dirname);
_chdir 함수는 현재 디렉토리를 변경한다. 이 함수로 변경한 현재 디렉토리를 작업 디렉토리라고 하며 이후 사용되는 상대 경로들은 작업 디렉토리를 기준으로 한다.
int _mkdir(const char *dirname);
_mkdir은 디렉토리를 생성한다. make의 mk다.
int _rmdir(const char *dirname);
_rmdir은 디렉토리를 제거하되 비어있지 않은 디렉토리 (무언가 파일이 존재하는)는 삭제할 수 없다.
char *_getcwd(char *buffer, int maxlen);
현재 작업 디렉토리를 조사한다.
void _splitpath(const char *path, char *drive, char *dir, char *fname, char *ext);
void _makepath(char *path, const char *drive, const char *dir, const char *fname, const char *ext);
두 함수는 파일 경로를 각각의 요소로 분리한다. 파일 경로는 드라이브, 디렉토리, 파일명, 확장자로 구성되어 있는데 직접 문자열을 조작하는 것은 무척 번거로운 일이다. 디렉토리와 파일 이름에 공백이 들어갈 수 있고 파일명과 확장자를 구분하는 마침표도 임의의 개수만큼 들어갈 수 있기 때문에 생각보다 훨씬 더 까다롭다.
경로 관리 함수는 파일 시스템의 이름 규칙대로 정확하게 경로 요소를 분리하고 합쳐 주므로 간편하게 쓸 수 있다. 특히 윈도우즈에는 경로를 관리하는 대응되는 함수가 없기 때문에 이 두 함수가 무척 유용하게 사용된다.
_splitpath 함수는 한 개의 입력 경로를 받아들여 이 경로를 요소별로 분리하여 네 개의 문자열 버퍼에 각각 저장한다. 이 함수를 호출하려면 분리된 요소를 저장할 4개의 버퍼를 미리 준비해야 한다.
#include <Turboc.h>
void main()
{
char path[MAX_PATH];
char drive[_MAX_DRIVE];
char dir[_MAX_DIR];
char fname[_MAX_FNAME];
char ext[_MAX_EXT];
strcpy(path,"c:\\My Document\\Test\\Report 2.5.bak");
_splitpath(path,drive,dir,fname,ext);
printf("파일명 = %s\n",fname);
}

드라이브 명 / 디렉토리 경로 / 파일의 이름 / 확장자
함수 사용시 버퍼에 NULL 값을 주면 해당 값은 저장하지 않는다.
이렇게 분리된 경로는 _makepath나 sprintf로 다시 하나로 합칠 수 있다
- 디스크 관리 -
다음 두 함수는 작업 드라이브를 조사하거나 변경한다. 드라이브는 번호로 표현하는데 1이 A, 2가 B, 3이 C순이다.
int _getdrive(void);
int _chdrive(int drive);
다음 함수는 디스크의 총 용량 및 남은 용량을 조사한다.
unsigned _getdiskfree(unsigned drive, struct _diskfree_t * driveinfo);
조사하고자 하는 드라이브의 번호를 주면 이 드라이브의 용량에 대한 정보를 다음 구조체에 채운다.
struct _diskfree_t {
unsigned total_clusters;
unsigned avail_clusters;
unsigned sectors_per_cluster;
unsigned bytes_per_sector;
};
멤버의 이름에 의미가 잘 나타나 있으므로 별도의 설명은 필요치 않을 것 같다. 대용량의 디스크는 클러스터 단위로 파일을 기록하므로 모든 정보들도 클러스터 수로 되어 있다. 이 구조체의 멤버를 조사하면 디스크의 총 용량과 남은 용량을 알 수 있고 두 값의 차를 구하면 사용한 용량도 쉽게 계산할 수 있다.
출처: http://genesis8.tistory.com/41 [프로그래머의 블로그]
=======================
=======================
=======================
출처: http://ospace.tistory.com/239
파일 읽기 성능을 비교해본 자료이다.
테스트 환경은 Windows7 32bit에서 수행하였다.
읽어온 텍스트 파일 크기는 14,682,256 byte이다.
작성: http://ospace.tistory.com/,2011.12.28 (ospace114@empal.com)
결과
일단 결과를 말하면 암담하지만 c++의 std의 ifstream의 성능은 매우 안좋다.
아래가 수행결과 이미지이다.
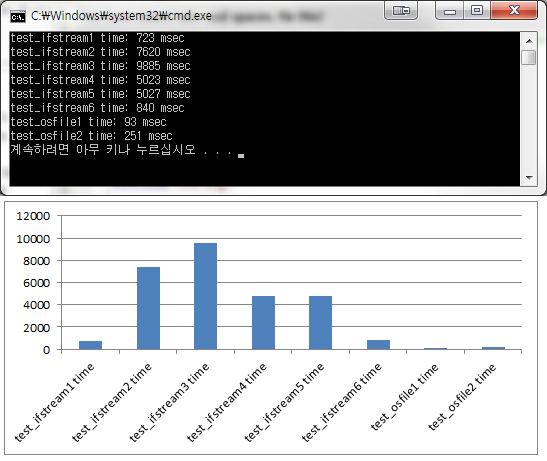
간단하게 설명을 하면 test_ifstream1에서 test_ifstream2까지가 한 줄의 문자열을 읽어오면서 반복적으로 모든 파일 내용을 읽어왔다. 그리고 test_ifstream3 ~ test_ifstream6까지가 모든 파일을 읽어오는 경우이다.
그리고, test_osfile1과 test_osfile2는 fopen()을 사용하여 읽어오는 경우이다.
test_ifstream1
ifstream에 있는 getline()를 사용하여 읽어 왔다. 직접 배열을 넘겨줘서 처리하였기에 ifstream 중에서 가장 성능이 좋았다.
void test_ifstream1() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); char buf[512]; while (!inFile.getline(buf, sizeof(buf)).eof()) { } }
test_ifstream2
이번에는 getline()이 ifstream의 메소드가 아니라 string 영역에 있는 std::getline()을 사용하였다. 일부러 string크기도 512로 해놓았는데도 성능은 좋지 않다. string을 사용한 방법이 그다지 좋지 않는다는 슬픈 결과가 나왔다. 즉, test_ifstream1에서 파일을 읽어오고, 다시 string으로 변환해서 처리하는게 성능이 더 좋다.
void test_ifstream2() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::string buf; buf.reserve(512); while (!inFile.eof()) { std::getline(inFile, buf); } }
test_ifstream3
이번에는 istreambuf_iterator를 사용하여 모든 파일을 읽어 들였다. 그리고 모든 내용은 vector<char>형태로 저장하였다. 나름 버퍼를 사용하는구나라고 생각이 들어서 성능이 좋겠구나라고 생각했지만, 정반대이다.
void test_ifstream3() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::istreambuf_iterator<char> begin(inFile); std::istreambuf_iterator<char> end; std::vector<char> contents(begin, end); }
test_ifstream4
test_ifstream3의 개선된 버전으로 vector의 공간을 미리 파일 크기만큼 지정한 방식이다.
당연히 성능은 절반가까이 줄어들었다. 그래도 성능은 암울하다.
void test_ifstream4() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::vector<char> contents; std::istreambuf_iterator<char> begin(inFile); std::istreambuf_iterator<char> end; contents.reserve(std::distance(begin, end)); contents.assign(begin, end); }
test_ifstream5
혹시나 해서 vector을 사용하기에 성능이 떨어지나해서 string으로 변경한 형태이다. 그러나 결과를 변함이 없다. 좋은 것은 vector에서 string으로 타입만 변환하고 나머지는 변경이 없다는 점이다.
void test_ifstream5() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::string contents; std::istreambuf_iterator<char> begin(inFile); std::istreambuf_iterator<char> end; contents.reserve(std::distance(begin, end)); contents.assign(begin, end); }
test_ifstream6
이번 예제는 test_ifstream1을 변형한 형태로 한줄씩 읽어오는데 모든 파일 내용을 저장하는 형태이다. 앞의 예는 이전에 불러온 내용은 사라지지만, 이번예제는 모두 보관하도록 수정하였다. 성능은 test_ifstream1보다 조금 늘어났지만, 다른 예보다는 상당히 좋았다.
std::ostringstream& operator << (std::ostringstream& oss, std::ifstream& in) { char buf[512]; in.getline(buf, sizeof(buf)); oss << buf; return oss; } void test_ifstream6() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::ostringstream oss; char buf[512]; while (!inFile.eof()) { oss << inFile; } }
test_osfile1
fopen()을 이용한 예로서 파일 내용은 fread()을 사용하였다. 앞의 예제와 다른 것은 한꺼번에 512 byte을 읽어오며, 한줄씩 읽어오지는 않는다. 그 이유 때문인지 성능이 가장 좋았다. ifstream을 사용하여 가장 빠른 경우보다 약 7배 이상 성능이 좋았다. 이 경우는 한 줄씩 읽어서 처리할 경우 문자별 매칭을 수행해야하는 번거러움이 생긴다.
void test_osfile1() { FILE *fp = fopen(TEST_FILE, "r"); if (NULL == fp) exit(1); char buf[512]; size_t len = 0; while (!feof(fp)) { len = fread(buf, sizeof(buf[0]), sizeof(buf)/sizeof(buf[0]), fp); } fclose(fp); }
test_osfile2
fopen()을 사용한 예로 fgets()을 사용하여 한 줄씩 읽어오는 예제이다. test_osfile1보다 성능이 안좋지만, ifstream 보다 최소 약 3배 정도 좋다.
void test_osfile2() { FILE *fp = fopen(TEST_FILE, "r"); if (NULL == fp) exit(1); char buf[512]; while (NULL != fgets(buf, sizeof(buf), fp)) { } fclose(fp); }
결론
성능으로만 따지자면 ifstream 사용을 권장하지 않는다. 최적화해도 직접 API를 호출하는 것보다 좋을 수는 없지만, 유연성을 위해 너무 과정을 거치면서 너무 많은 성능하락이 커지는 문제점이 생긴다. 이 부분을 얼마나 줄이는지가 관건인데, 아직 멀었다고 본다.
여러 운영체제에 포팅하는 경우 이식성을 높이기 위해서 ifstream을 사용하는 것이 가장 좋은 방안이지만, 성능이 문제라면 다른 공통으로 사용할 수 있는 라이브러리를 찾는게 방안이지만, 이것 또한 안정성과 검증이 안되었기에 도입하는데 쉽지는 않다.
fopen()인 경우 공통 c 라이브러리이기 때문에 대부분 호환 가능하기에 이식성에 어려움은 없다. 그렇기에 fopen() 사용하는 것도 나쁘다고 보지 않는다. 문제는 기존 c++의 stl과 연동이 자연스럽지 않기에 이 부분을 어떻게 풀어가는가가 핵심이라고 볼 수 있다. 즉, 해야할 일들이 많이 생기게 된다.
그러나 성능이 큰 문제가 아니라면 ifstream을 쓰는것도 나쁘지는 않다. ifstream의 getline()을 사용하는 경우 성능은 좀 떨어지지만, 간단한 파일을 처리는데는 문제가 없다고 본다.
이 자료는 참고일뿐, 결정의 본인이 알아서...
모드 즐프~~~
ospace.
Source code
// test_ifstream.cpp : Defines the entry point for the console application. // by ospace (2011.12.28) #include <fstream> #include <sstream> #include <iostream> #include <windows.h> #include <vector> #include <cstdio> #include <string> #define TEST_FILE "Sample.txt" void test_ifstream1() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); char buf[512]; while (!inFile.getline(buf, sizeof(buf)).eof()) { } } void test_ifstream2() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::string buf; buf.reserve(512); while (!inFile.eof()) { std::getline(inFile, buf); } } void test_ifstream3() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::istreambuf_iterator<char> begin(inFile); std::istreambuf_iterator<char> end; std::vector<char> contents(begin, end); } void test_ifstream4() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::vector<char> contents; std::istreambuf_iterator<char> begin(inFile); std::istreambuf_iterator<char> end; contents.reserve(std::distance(begin, end)); contents.assign(begin, end); } void test_ifstream5() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::vector<char> contents; std::istreambuf_iterator<char> begin(inFile); std::istreambuf_iterator<char> end; contents.reserve(std::distance(begin, end)); contents.assign(begin, end); } std::ostringstream& operator << (std::ostringstream& oss, std::ifstream& in) { char buf[512]; in.getline(buf, sizeof(buf)); oss << buf; return oss; } void test_ifstream6() { std::ifstream inFile; inFile.open(TEST_FILE); if (!inFile.is_open()) exit(1); std::ostringstream oss; char buf[512]; while (!inFile.eof()) { oss << inFile; } } void test_osfile1() { FILE *fp = fopen(TEST_FILE, "r"); if (NULL == fp) exit(1); char buf[512]; size_t len = 0; while (!feof(fp)) { len = fread(buf, sizeof(buf[0]), sizeof(buf)/sizeof(buf[0]), fp); } fclose(fp); } void test_osfile2() { FILE *fp = fopen(TEST_FILE, "r"); if (NULL == fp) exit(1); char buf[512]; while (NULL != fgets(buf, sizeof(buf), fp)) { } fclose(fp); } #define CALL_TIME(f) do {\ DWORD start , end;\ start = timeGetTime();\ f();\ end = timeGetTime();\ std::cout << #f << " time: " << end - start << " msec" << std::endl;\ } while (0) int main(int argc, char* argv[]) { CALL_TIME(test_ifstream1); CALL_TIME(test_ifstream2); CALL_TIME(test_ifstream3); CALL_TIME(test_ifstream4); CALL_TIME(test_ifstream5); CALL_TIME(test_ifstream6); CALL_TIME(test_osfile1); CALL_TIME(test_osfile2); return 0; }
출처: http://ospace.tistory.com/239 [JaPa2]
=======================
=======================
=======================
'프로그래밍 관련 > 언어들의 코딩들 C++ JAVA C# 등..' 카테고리의 다른 글
| C, C++ 멀티스레드에서 shared_ptr 사용시 주의사항 (0) | 2020.09.10 |
|---|---|
| C, C++ Thread, 스레드, 쓰레드 _beginthreadex(멀티스레드적합), _beginthread (0) | 2020.09.10 |
| C/C++ STL의 문자열 string 사용법 검색 배치 자리 관련 (0) | 2020.09.10 |
| [C#] delegate 델리게이트 관련 (0) | 2020.09.10 |
| C# char, char[] 을 string 로 바꾸기 관련 (0) | 2019.09.19 |





댓글 영역