=======================
=======================
=======================
아이디로 로그인할수 있게 해둔다.

----------------------------------------------------------------------------------------------------------------------------------------

----------------------------------------------------------------------------------------------------------------------------------



String url = "jdbc:sqlserver://서버아이피주소:1533;DatabaseName=OroLiveWeb;";
String id = "godpsj";
String pas = "12345678";
String MSSQL_DRIVER = "com.microsoft.sqlserver.jdbc.SQLServerDriver";
public void test() {
Connection con = null;
con = makeConnection(url, id, pas, MSSQL_DRIVER);
}
public Connection makeConnection(String url, String userId, String userPw,
String driverNm) throws SQLException {
Connection conn = null;
try
{
// 1. JDBC 드라이버 로드
Class.forName(driverNm);
// 2. DriverManager.getConnection()를 이용하여 Connection 인스턴스 생성
conn = DriverManager.getConnection(url, userId, userPw);
if (conn != null)
{
System.out.println("Connection Successful!!!");
}
} catch (ClassNotFoundException e)
{
e.printStackTrace();
} catch (SQLException sq)
{
sq.printStackTrace();
}
return conn;
}
=======================
=======================
=======================
[Java]MS-SQL접속하기
프로그램을 하다보면 DB를 연결해야 할때가 있습니다.
보통 DB하면 오라클, MySQL, MS-SQL등이 일반적으로 많이 사용 될꺼라 생각 됩니다.
오라클, MySQL은 Java와 연결해 본적이 있는데..... MS-SQL은 아직 해본적이 없었습니다.
이번에 MS-SQL과도 연결해야 할일이 생겨 샘플을 한번 만들어 봤습니다.
MS-SQL의 JDBC드라이버는 아래의 URL에서 받으세요.
[다운로드]http://www.microsoft.com/ko-kr/download/details.aspx?id=11774
저는 언어를 한국어로하여 sqljdbc_4.0.2206.100_kor.tar.gz압축 파일을 다운로드 하였습니다.
압축을 풀어보니 sqljdbc_4.0안에 kor폴더가 있더군요. 아마도 언어 별로 뭔가를 관리 하는게 아닐까 생각해봅니다.
역시나, install.txt와 license.txt파일을 열어보니 한국어로 되어있네요.
jar파일은 sqljdbc.jar과 sqljdbc4.jar 두가지가 있더군요.
뭘 사용해야 하나 찾아보니..... 아래의 url에 설명이 되어 있습니다. 참고하세요.
[링크]http://www.sysnet.pe.kr/Default.aspx?mode=2&sub=0&detail=1&pageno=0&wid=1116&rssMode=1&wtype=0
샘플소스는 MS-SQL에 접속해 데이터베이스 정보를 표시하는 소스입니다.
[샘플 소스]
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
public class MsSQLConnect {
/**
*
* DB프로퍼티 표시
* @param url
* @param userId
* @param userPw
* @param driverNm
*/
public void displayDbProperties(String url, String userId, String userPw,
String driverNm) {
Connection con = null;
DatabaseMetaData dm = null;
ResultSet rs = null;
try {
con = this.makeConnection(url, userId, userPw, driverNm);
if (con != null) {
dm = con.getMetaData();
System.out.println("Driver Information");
System.out.println("\tDriver Name: " + dm.getDriverName());
System.out
.println("\tDriver Version: " + dm.getDriverVersion());
System.out.println("\nDatabase Information ");
System.out.println("\tDatabase Name: " +
dm.getDatabaseProductName());
System.out.println("\tDatabase Version: " +
dm.getDatabaseProductVersion());
System.out.println("Avalilable Catalogs ");
rs = dm.getCatalogs();
while (rs.next()) {
System.out.println("\tcatalog: " + rs.getString(1));
}
rs.close();
rs = null;
} else
System.out.println("Error: No active Connection");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (con != null)
con.close();
con = null;
} catch (Exception e) {
e.printStackTrace();
}
}
dm = null;
}
/**
* 커넥션을 취득해 반환 DB커넥션 취득
*
* @param url
* @param userId
* @param userPw
* @param driverNm
* @return
* @throws SQLException
*/
public Connection makeConnection(String url, String userId, String userPw,
String driverNm) throws SQLException {
Connection conn = null;
try {
// 1. JDBC 드라이버 로드
Class.forName(driverNm);
// 2. DriverManager.getConnection()를 이용하여 Connection 인스턴스 생성
conn = DriverManager.getConnection(url, userId, userPw);
if (conn != null) {
System.out.println("Connection Successful!!!");
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException sq) {
sq.printStackTrace();
}
return conn;
}
public static void main(String[] args) throws Exception {
// 유저ID
String userId = "sa";
// 유저 패스워드
String userPw = "testtest";
// 드라이버명
String MSSQL_DRIVER = "com.microsoft.sqlserver.jdbc.SQLServerDriver";
MsSQLConnect myDbTest = new MsSQLConnect();
myDbTest.displayDbProperties(getMsSQLJDBCUrl(), userId, userPw,
MSSQL_DRIVER);
}
/**
* MS-SQL JDBC url만들기
* @return
*/
public static String getMsSQLJDBCUrl() {
StringBuilder url = new StringBuilder();
url.append("jdbc:sqlserver://");
url.append("localhost"); // 접속호스트
url.append(":");
url.append("1433"); // 포트번호
url.append(";");
url.append("databaseName=");
url.append("TEST"); // DB명
url.append(";");
url.append("selectMethod=");
url.append("cursor");
url.append(";");
return url.toString();
}
}
[결과]
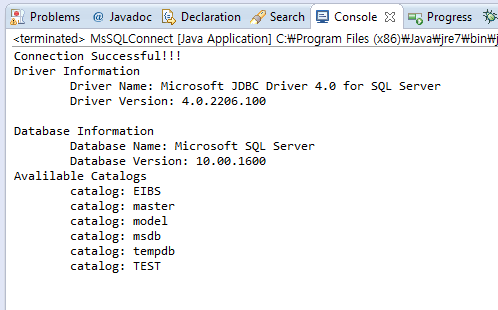
위에서도 잠깐 얘기해는데... jar파일은 sqljdbc.jar과 sqljdbc4.jar 두가지가 있습니다.
jdbc url과 드라이버명이 조금 틀리기 때문에 링크걸린곳을 꼭들러 차이점을 확인하신후 사용하시길 바랍니다.
감사합니다.
=======================
=======================
=======================
출처: http://www.yunsobi.com/blog/514
sqljdbc.jar
sqljdbc.jar 클래스 라이브러리는 JDBC 3.0을 지원합니다.
sqljdbc.jar 클래스 라이브러리에는 JRE(Java Runtime Environment) 버전 5.0이 필요합니다.
JRE 6.0에서 sqljdbc.jar을 사용하면 데이터베이스에 연결할 때 예외가 발생합니다.
참고: JDBC 드라이버 버전 2.0은 JRE 1.4를 지원하지 않습니다. JDBC 드라이버 버전 2.0을
사용하려면 JRE 1.4를 JRE 5.0 이상으로 업그레이드해야 합니다.
응용 프로그램이 JDK 5.0 이상과 호환되지 않아 다시 컴파일해야 하는 경우도 있습니다.
sqljdbc4.jar
sqljdbc4.jar 클래스 라이브러리는 JDBC 4.0을 지원합니다.
이 라이브러리에는 sqljdbc.jar의 모든 기능과 함께 새로운 JDBC 4.0 메서드가 포함되어 있습니다.
sqljdbc4.jar 클래스 라이브러리에는 JRE(Java Runtime Environment) 버전 6.0 이상이 필요합니다.
JRE 1.4 또는 5.0에서 sqljdbc4.jar을 사용하면 예외가 발생합니다.
참고: 응용 프로그램을 JRE 6.0에서 실행해야 하는 경우에는 JDBC 4.0 기능을 사용하지 않더라도
sqljdbc4.jar을 사용하십시오.
http://msdn.microsoft.com/ko-kr/library/ms378422.aspx
=======================
=======================
=======================
출처: http://hackhyun.tistory.com/42
1. MS SQL Server JDBC Driver 설치
http://www.microsoft.com/downloads/details.aspx?displaylang=ko&FamilyID=99b21b65-e98f-4a61-b811-19912601fdc9

2. 다운로드 받은 파일(sqljdbc_2.0.1803.100_kor.exe)의 압축을 풀면 sqljdbc4.jar, sqljdbc.jar 파일이 있는데
이를 jdk\jre\lib\ext 폴더에 복사 한다.
3. 환경설정에서 CLASSPATH를 추가한다.
sqljdbc.jar 파일의 경로를 포함한 전체 이름을 지정한다.
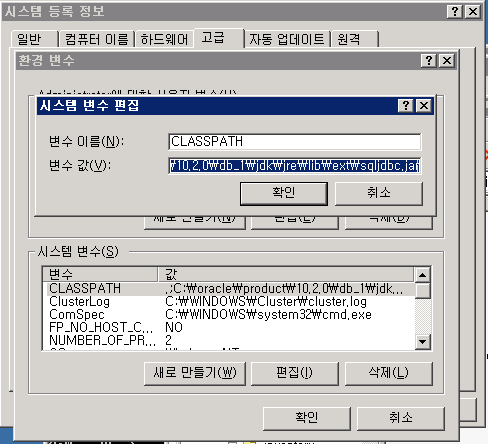
4. 테스트용 java 소스
import java.sql.*;
import java.sql.SQLException;
import java.io.*;
public class test {
public static void main(String[] args) throws Exception {
String url = "jdbc:sqlserver://서버IP주소:1433;DatabaseName=데이터베이스명";
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
conn = DriverManager.getConnection(url, "계정", "패스워드");
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT * FROM 테이블명");
while (rs.next()) {
String field1 = rs.getString("필드명1");
String field2 = rs.getString("필드명2");
System.out.println(field1);
System.out.println(field2);
}
rs.close();
stmt.close();
conn.close();
}
}
5. 컴파일 및 실행
| javac test.java java test |
[2014.02.10] 추가
최신 버전인 JDBC 4.0 드라이버 주소는 다음과 같다
SQL Server용 Microsoft JDBC Driver 4.0
=======================
=======================
=======================
출처: http://egloos.zum.com/Esunny/v/4202028
일단 내 PC에 설치되어 있는게 MSSQL이니까
MS로 연동을 해보겠다.
1. 테이블 생성
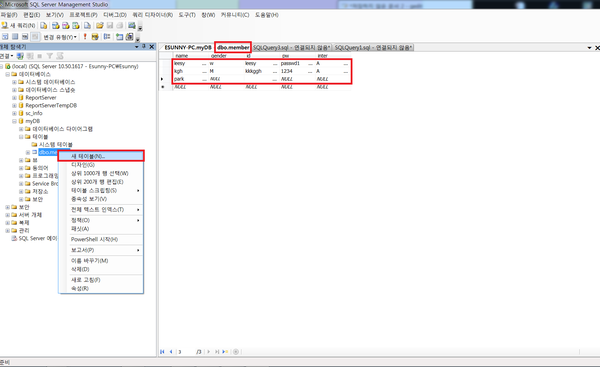
2. insert/select
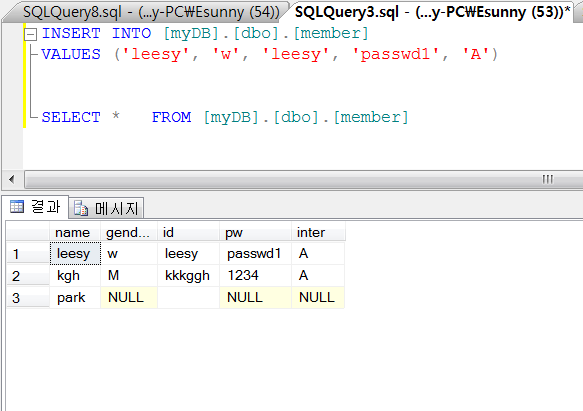
. 3. JDBC 드라이버 다운로드
http://www.microsoft.com/ko-kr/download/details.aspx?id=11774

4.다운로드가 완료된 파일을 압축 푼다.
D:\설치파일\Microsoft JDBC Driver 4.1 for SQL Server\sqljdbc_4.1\kor
아래에 sqljdbc4.jar 복사해서
D:\Program Files\Java\jdk1.8.0_45\lib\ext
경로로 복사 해놓기 .
5.eclipse 에서 연동하기. jar추가
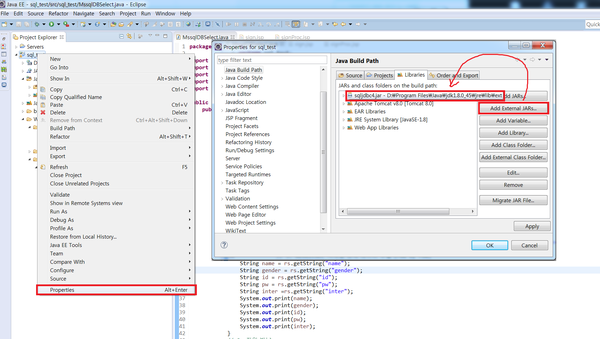
6. 데이터베이스에 접근할 수 있는 계정 만들기

7.jsp파일 test
package sql_test;
import java.sql.*;
public class MssqlDBSelect {
public static void main(String[] args) {
String driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver";
String url = "jdbc:sqlserver://localhost:1433";
String user = "vUser";
String password = "1234";
// 1. JDBC Driver 로딩
try {
Class.forName(driver);
// 2. 데이터베이스 연결 (by url with username and password)
Connection con = DriverManager.getConnection(url, user, password);
// 3. Statement 객체 생성
Statement stmt = con.createStatement();
// 4. Query 실행 (using Statement, receive the ResultSet)
String qry = "use myDB; " + "select * from member ";
ResultSet rs = stmt.executeQuery(qry);
System.out.println("Name\t Sex\t ID \t PassWord \tHobby");
System.out.println("===========================================================================");
// 5. ResultSet 객체를 통해 데이터 추출 (row by row)
while (rs.next()) {
String name = rs.getString("name");
String gender = rs.getString("gender");
String id = rs.getString("id");
String pw = rs.getString("pw");
String inter = rs.getString("inter");
System.out.print(name);
System.out.print(gender);
System.out.print(id);
System.out.print(pw);
System.out.print(inter);
}
// 6. 자원 반납
rs.close();
stmt.close();
con.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
8. MSSQL에서 만들었던 테이블 출력
MSSQL과 JAVA가 성공적으로 연동이 끝났다,
9.문법에 대해서는 다시 확인한 후에 예제로 가겠다.
=======================
=======================
=======================
출처: http://www.sysnet.pe.kr/Default.aspx?mode=2&sub=0&detail=1&pageno=0&wid=1116&rssMode=1&wtype=0
자바에서 "Microsoft SQL Server JDBC Driver" 사용하는 방법
요즘 제가 ^^ 자바 진영을 이해하기 위해서 고군분투하고 있습니다. 나름 자바와 닷넷이 비슷한 면도 있고, 언어적인 면에서도 때로는 자바가 나은 면도 있고 반대인 경우도 있더군요.
어쨌든... ^^ 이번에는 자바에서 DB 연결하는 방법을 살펴보기 위해 가장 친숙한 MS-SQL 서버 먼저 접속을 해보았습니다. 관련해서 검색해 보니, 한글로 된 블로그 게시물도 꽤 되는군요. ^^
MSSQL jdbc 드라이버 sqljdbc.jar 와 sqljdbc4.jar 의 차이점 ; http://www.yunsobi.com/blog/514 HOWTO: Microsoft JDBC 시작하기 ; http://support.microsoft.com/kb/313100/ko JDBC(MS SQL) 드라이버 사용 ; http://angelprogramming.tistory.com/28
현재, "Microsoft SQL Server JDBC Driver" 버전이 3.0 까지 나와 있으니 다음의 링크에서 다운로드 받고,
Microsoft SQL Server JDBC Driver 3.0 ; http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=21599
압축을 해제하면 sqljdbc.jar, sqljdbc4.jar 파일을 얻을 수 있는데, 어느 것을 사용할 지는 "MSSQL jdbc 드라이버 sqljdbc.jar 와 sqljdbc4.jar 의 차이점" 글을 보시면 쉽게 결정하실 수 있을 것입니다. (이 글에서는, 제가 구성한 테스트 환경이 JRE 1.6을 사용할 것이므로 sqljdbc4.jar 를 선택했습니다.)
예제 실습을 하기 전에, 여기서 잠시 닷넷과 자바의 차이점을 이해해야 할 부분이 있는데, 바로 모듈을 찾는 규칙입니다. 닷넷의 경우에는 EXE 와 동일한 폴더(또는, 웹 App의 경우 /bin)이거나 GAC(Global Assembly Cache) 가 대표적인데, 자바는 여러 환경을 지원하다 보니 제각각입니다. 자세한 내용은 "Microsoft SQL Server JDBC Driver 3.0" 설치 후 "\sqljdbc_3.0\enu\help\default.htm" 문서의 "Overview of the JDBC Driver" / "Using the JDBC Driver" 에 언급되어 있으니 생략하고, 여기서는 지난 번에 실습해 보았던 Servlet 내용에서 했던 데로 다음과 같이 구성했습니다.
- sqljdbc4.jar 를 '[톰캣 설치폴더]\lib' 폴더에 복사 (실행을 위해!)
- Eclipse IDE 에서 Java Build Path / Libraries / Add External JARs 를 통해 sqljdbc4.jar를 지정 (컴파일을 위해!)
(만약, sqljdbc4.jar 내부의 클래스를 직접 사용하는 경우가 아니라면 참조 생략 가능)
예제 코드는, 지난 번 서블릿 코드를 재사용해서 다음과 같이 DB 관련 코드만 넣어보았습니다. (아래의 예제 코드는 "\sqljdbc_3.0\enu\help\default.htm" 문서의 "Sample JDBC Driver Applications" / "Connecting and Retrieving Data" / "Connection URL Sample" 을 가져온 것입니다.)
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.sql.*;
public class HelloWorld extends HttpServlet
{
private static final long serialVersionUID = 1L;
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException
{
res.setContentType("text/html");
PrintWriter out = res.getWriter();
String connectionString = "jdbc:sqlserver://mydb2:1433;" +
"databaseName=TestDB;user=testdbuser;password=testdbuser2008";
Connection con = null;
Statement stmt = null;
ResultSet rs = null;
try {
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
con = DriverManager.getConnection(connectionString);
String SQL = "SELECT * FROM TestTable";
stmt = con.createStatement();
rs = stmt.executeQuery(SQL);
while (rs.next()) {
out.println(rs.getInt(1));
}
}
catch (Exception e) {
e.printStackTrace();
}
finally {
if (rs != null) try { rs.close(); } catch(Exception e) {}
if (stmt != null) try { stmt.close(); } catch(Exception e) {}
if (con != null) try { con.close(); } catch(Exception e) {}
}
}
}
DB 접근에 대한 추상화는 자바가 더 나은 것 같습니다. 왜냐하면 닷넷의 경우에는 물론 인터페이스가 있다고는 하지만 대부분의 경우에 DB 제공자마다 다르게 사용하기 때문입니다. (예를 들어, SQL Server - SqlConnection, Oracle - OracleConnection, Postgre - NpgsqlConnection, ...)
RDB라는 것이 SQL 쿼리로 인해 정형화되어 있는 접근 방식을 제공하므로, 닷넷에서 DB를 다루던 경험이 있다면 자바의 DB 접근 방법을 배우는 것이 그다지 어려운 문제는 아니더군요. ^^
참고로, 딱 한가지... 닷넷 개발자 입장에서 주의해야 할 점이 있다면 ResultSet의 get... 메서드에 전달되는 인덱스가 0 이 아닌 1 부터 시작한다는 예외(?) 사항이 존재합니다. 만약 rs.getInt(0) 처럼 접근한다면 다음과 같은 예외가 발생합니다.
com.microsoft.sqlserver.jdbc.SQLServerException: Index 0 is out of range (인덱스 0이(가) 범위를 벗어났습니다.)
at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDriverError(SQLServerException.java:171)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.verifyValidColumnIndex(SQLServerResultSet.java:504)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getterGetColumn(SQLServerResultSet.java:1948)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getValue(SQLServerResultSet.java:1981)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getValue(SQLServerResultSet.java:1966)
at com.microsoft.sqlserver.jdbc.SQLServerResultSet.getInt(SQLServerResultSet.java:2209)
at HelloWorld.doGet(HelloWorld.java:36)
...[생략]...
at java.lang.Thread.run(Thread.java:619)
=======================
=======================
=======================
출처: http://m.blog.naver.com/softservant7/110125839581
저는 현재 이클립스 Eclipse Java EE IDE를 설치했고,
자바 jdk버젼은 "1.7.0_01" 입니다.
자바 배치(batch) 프로그램을 만드느라 인터넷셔핑에 열심이 삽질하고 있습니다.
다른 db서버(ms-sql)에 있는 데이타를, my-sql에 가져오는 배치프로그램인데요,
자바로 만들려고 해요.
그런데 제가 자바는 처음이거든요. 그래서 인터넷에서 자료를 찾아가면서
마음은 급한데 더디게 프로그램 짜고 있습니다.
오늘은 먼저 다른 db서버(ms-sql)에 있는 자료를 잘읽어오는지 테스트해 보았습니다.
어쨌든 약간 헤맷지만 지금은 잘 읽어오네요. (mysql과 거의 같습니다)
저처럼 초보들이 헤매지 말고 쉽게 연동하도록 자료 올립니다.
이클립스에서 ms-sql JDBC(Java Database Connectivity) 연결하는 순서를 보면,
1. 먼저 MS-SQL 드라이버를 다운로드 받아 설치해야 합니다
- 드라이버 다운로드: http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=21599
- 아니면 제가 올린 파일 다운받아 설치하세요.(sqljdbc.jar, sqljdbc4.jar)
sqljdbc.jar와 sqljdbc4.jar 차이는 여기를 http://www.yunsobi.com/blog/514 참조하세요.
- 다운로드한 jar 파일을 자바설치 폴더:\Java\jre\lib\ext' 폴더에 붙여(복사해) 넣으면 됩니다.
저의 경우는 'C:\Program Files\Java\jdk1.7.0_01\jre\lib\ext' 폴더에 붙여 넣었습니다.
2. 이클립스에서 해당 프로젝트명을 선택하고 마우스 오른쪽 단추를 클릭하여 맨밑에 [Properties]를 선택합니다.
- Properties 창의 왼쪽 메뉴에서 [Java Build Path]를 선택합니다
- 오른쪽 화면에서 [Libraries] 탭을 선택하고 [Add External JARs] 단추를 클릭합니다.
- 1번에서 복사한 jar파일 선택하고 [열기] 클릭합니다.
. '자바설치드라이:\Java\jdk\lib\sqljdbc4.jar' 파일을 선택, 열기
. 저의 경우는 'C:\Program Files\Java\jdk1.7.0_01\jre\lib\ext\sqljdbc4.jar' 선택해서 열기했습니다.
- [Libraries] 탭의 메뉴에 'sqljdbc4.jar'가 등록된 것을 확인하고 [OK] 단추를 클릭합니다.
3. 그러면 왼쪽의 해당 프로젝트 밑으로 Referenced Libraries가 생기죠. 이거 열어보변 'sqljdbc4.jar' 나옵니다.
4. 설정은 끝났습니다. 프로그램 테스트 해볼까요.
- 밑의 소스는 이클립스에서 ms-sql 연동 테스트한 소스입니다.
- 다른 db서버(ms-sql)에 연결하여 자료를 select해서 보여줍니다.
import java.sql.*;
public class MssqlDBSelect {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
Connection conn = null;
Statement stmt = null;
try {
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
String connectionString = "jdbc:sqlserver://서버ip 넣으세요:1433;" +
"databaseName=연결한 DB명;user=사용자id;password=비밀번호";
conn = DriverManager.getConnection(connectionString);
stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery
("select id, name, first from testinfo;");
System.out.println("id name \t\t\t first");
System.out.println("ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ");
while (rs.next()) {
String bookid = rs.getString("id");
String bookname = rs.getString("name");
String publishing = rs.getString("first");
System.out.printf("%s %s %s %n", id, name, first);
}
} catch (ClassNotFoundException cnfe) {
System.out.println("해당 클래스를 찾을 수 없습니다." + cnfe.getMessage());
} catch (SQLException se) {
System.out.println(se.getMessage());
} finally {
try {
stmt.close();
} catch (Exception ignored) {
}
try {
conn.close();
} catch (Exception ignored) {
}
}
}
}
=======================
=======================
=======================
출처: https://msdn.microsoft.com/ko-kr/library/ms378371(v=sql.110).aspx
반환 상태가 있는 저장 프로시저 사용
게시 날짜: 2016년 4월

호출할 수 있는 SQL Server 저장 프로시저는 상태 또는 결과 및 매개 변수를 반환하는 프로시저입니다. 이러한 매개 변수는 대개 저장 프로시저의 성공 또는 실패를 나타내는 데 사용됩니다. SQL Server용 Microsoft JDBC Driver는 이러한 종류의 저장 프로시저를 호출하여 반환되는 데이터를 처리하는 데 사용할 수 있는 SQLServerCallableStatement 클래스를 제공합니다.
JDBC 드라이버를 사용하여 이러한 종류의 저장 프로시저를 호출하는 경우에는 call SQL 이스케이프 시퀀스와 함께 SQLServerConnection 클래스의 prepareCall 메서드를 사용해야 합니다. 반환 상태 매개 변수가 있는 call 이스케이프 시퀀스의 구문은 다음과 같습니다.
{[?=]call procedure-name[([parameter][,[parameter]]...)]}
참고
SQL 이스케이프 시퀀스에 대한 자세한 내용은 SQL 이스케이프 시퀀스 사용을 참조하십시오. |
call 이스케이프 시퀀스를 만드는 경우 물음표(?) 문자를 사용하여 반환 상태 매개 변수를 지정합니다. 이 문자는 저장 프로시저에서 반환될 매개 변수 값에 대한 자리 표시자로 사용됩니다. 반환 상태 매개 변수에 대한 값을 지정하려면 저장 프로시저를 실행하기 전에 SQLServerCallableStatement 클래스의 registerOutParameter 메서드를 사용하여 매개 변수의 데이터 형식을 지정해야 합니다.
참고
SQL Server 데이터베이스에서 JDBC 드라이버를 사용하는 경우 registerOutParameter 메서드의 반환 상태 매개 변수에 대해 지정하는 값은 항상 정수이며, 이는 java.sql.Types.INTEGER 데이터 형식을 사용하여 지정할 수 있습니다. |
또한 반환 상태 매개 변수에 대한 registerOutParameter 메서드에 값을 전달하는 경우 해당 매개 변수에 사용할 데이터 형식은 물론 저장 프로시저 호출에서 매개 변수의 서수 위치도 지정해야 합니다. 반환 상태 매개 변수인 경우, 항상 저장 프로시저 호출에서 첫 번째 매개 변수이므로 해당 서수 위치는 항상 1입니다. SQLServerCallableStatement 클래스가 특정 매개 변수를 나타내기 위해 매개 변수의 이름 사용을 지원하더라도 반환 상태 매개 변수에 대한 매개 변수의 서수 위치 번호만 사용할 수 있습니다.
이에 대한 예로 SQL Server 2005 AdventureWorks 샘플 데이터베이스에 다음 저장 프로시저를 만듭니다.
CREATE PROCEDURE CheckContactCity
(@cityName CHAR(50))
AS
BEGIN
IF ((SELECT COUNT(*)
FROM Person.Address
WHERE City = @cityName) > 1)
RETURN 1
ELSE
RETURN 0
END
이 저장 프로시저에서는 cityName 매개 변수에 지정된 도시가 Person.Address 테이블에 있는지 여부에 따라 1 또는 0의 상태 값을 반환합니다.
다음 예제에서는 AdventureWorks 샘플 데이터베이스에 대해 열린 연결을 함수로 전달하고 execute 메서드를 사용하여 CheckContactCity 저장 프로시저를 호출합니다.
public static void executeStoredProcedure(Connection con) {
try {
CallableStatement cstmt = con.prepareCall("{? = call dbo.CheckContactCity(?)}");
cstmt.registerOutParameter(1, java.sql.Types.INTEGER);
cstmt.setString(2, "Atlanta");
cstmt.execute();
System.out.println("RETURN STATUS: " + cstmt.getInt(1));
cstmt.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
----------------------------------------------------------------------------------------------------------------------------------
출처: https://msdn.microsoft.com/ko-kr/library/ms378108(v=sql.110).aspx
출력 매개 변수가 있는 저장 프로시저 사용
게시 날짜: 2016년 4월

호출할 수 있는 SQL Server 저장 프로시저는 출력 매개 변수를 하나 이상 반환하는 저장 프로시저입니다. 여기서 매개 변수는 저장 프로시저에서 데이터를 호출 응용 프로그램으로 다시 반환하는 데 사용됩니다. SQL Server용 Microsoft JDBC Driver는 이러한 종류의 저장 프로시저를 호출하여 반환되는 데이터를 처리하는 데 사용할 수 있는 SQLServerCallableStatement 클래스를 제공합니다.
JDBC 드라이버를 사용하여 이러한 종류의 저장 프로시저를 호출하는 경우에는 SQLServerConnection 클래스의 prepareCall 메서드와 함께 callSQL 이스케이프 시퀀스를 사용해야 합니다. 출력 매개 변수가 있는 call 이스케이프 시퀀스의 구문은 다음과 같습니다.
{call procedure-name[([parameter][,[parameter]]...)]}
참고
SQL 이스케이프 시퀀스에 대한 자세한 내용은 SQL 이스케이프 시퀀스 사용을 참조하십시오. |
call 이스케이프 시퀀스를 만드는 경우 물음표(?) 문자를 사용하여 출력 매개 변수를 지정합니다. 이 문자는 저장 프로시저에서 반환될 매개 변수 값에 대한 자리 표시자로 사용됩니다. 출력 매개 변수에 대한 값을 지정하려면 저장 프로시저를 실행하기 전에 SQLServerCallableStatement 클래스의 registerOutParameter 메서드를 사용하여 각 매개 변수의 데이터 형식을 지정해야 합니다.
registerOutParameter 메서드에서 출력 매개 변수에 대해 지정하는 값은 java.sql.Types에 들어 있는 JDBC 데이터 형식 중 하나여야 합니다. 또한 이 값은 네이티브 SQL Server 데이터 형식 중 하나에 매핑됩니다. JDBC 및 SQL Server 데이터 형식에 대한 자세한 내용은 JDBC 드라이버 데이터 형식 이해를 참조하십시오.
OUT 매개 변수에 대한 registerOutParameter 메서드에 값을 전달하는 경우 해당 매개 변수에 사용할 데이터 형식은 물론 저장 프로시저 호출에서 매개 변수의 서수 위치 또는 매개 변수의 이름도 지정해야 합니다. 예를 들어, 저장 프로시저에 하나의 출력 매개 변수가 들어 있는 경우 서수 값은 1이 됩니다. 또한 저장 프로시저에 출력 매개 변수가 두 개이면 첫 번째 서수 값은 1이고 두 번째 서수 값은 2가 됩니다.
참고
JDBC 드라이버에서는 출력 매개 변수로 CURSOR, SQLVARIANT, TABLE 및 TIMESTAMP와 같은 SQL Server 데이터 형식을 사용할 수 없습니다. |
이에 대한 예로 SQL Server 2005 AdventureWorks 샘플 데이터베이스에 다음 저장 프로시저를 만듭니다.
CREATE PROCEDURE GetImmediateManager
@employeeID INT,
@managerID INT OUTPUT
AS
BEGIN
SELECT @managerID = ManagerID
FROM HumanResources.Employee
WHERE EmployeeID = @employeeID
END
이 저장 프로시저에서는 정수인 지정한 입력 매개 변수(employeeID)를 토대로 하여 마찬가지로 정수인 단일 출력 매개 변수(managerID)를 반환합니다. 출력 매개 변수에 반환되는 값은 HumanResources.Employee 테이블에 들어 있는 EmployeeID를 토대로 한 ManagerID입니다.
다음 예제에서는 AdventureWorks 샘플 데이터베이스에 대해 열린 연결을 함수로 전달하고 execute 메서드를 사용하여 GetImmediateManager 저장 프로시저를 호출합니다.
public static void executeStoredProcedure(Connection con) {
try {
CallableStatement cstmt = con.prepareCall("{call dbo.GetImmediateManager(?, ?)}");
cstmt.setInt(1, 5);
cstmt.registerOutParameter(2, java.sql.Types.INTEGER);
cstmt.execute();
System.out.println("MANAGER ID: " + cstmt.getInt(2));
}
catch (Exception e) {
e.printStackTrace();
}
}
다음 예에서는 서수 위치를 사용하여 매개 변수를 식별합니다. 서수 위치 대신 이름을 사용하여 매개 변수를 식별할 수도 있습니다. 다음 코드 예에서는 이전 예를 수정하여 Java 응용 프로그램에서 명명된 매개 변수를 사용하는 방법을 설명합니다. 매개 변수 이름은 저장 프로시저의 정의에 있는 매개 변수 이름에 해당합니다.
public static void executeStoredProcedure(Connection con) {
try {
CallableStatement cstmt = con.prepareCall("{call dbo.GetImmediateManager(?, ?)}");
cstmt.setInt("employeeID", 5);
cstmt.registerOutParameter("managerID", java.sql.Types.INTEGER);
cstmt.execute();
System.out.println("MANAGER ID: " + cstmt.getInt("managerID"));
cstmt.close();
}
catch (Exception e) {
e.printStackTrace();
}
}
참고
이러한 예에서는 SQLServerCallableStatement 클래스의 execute 메서드를 사용하여 저장 프로시저를 실행합니다. 이 메서드를 사용하는 이유는 저장 프로시저에서 결과 집합을 반환하지 않았기 때문입니다. 저장 프로시저에서 결과 집합을 반환한 경우에는 executeQuery 메서드를 사용합니다. |
저장 프로시저는 업데이트 횟수 및 다중 결과 집합을 반환할 수 있습니다. SQL Server용 Microsoft JDBC Driver는 OUT 매개 변수를 검색하기 전에 다중 결과 집합 및 업데이트 횟수를 검색해야 한다는 JDBC 3.0 사양을 따릅니다. 즉, 응용 프로그램은 CallableStatement.getter 메서드를 사용하여 OUT 매개 변수를 검색하기 전에 모든 ResultSet 개체 및 업데이트 회수를 검색해야 합니다. 그렇지 않으면 이미 검색되지 않은 ResultSet 개체와 업데이트 회수는 OUT 매개 변수를 검색할 때 손실됩니다. 업데이트 회수 및 다중 결과 집합에 대한 자세한 내용은 업데이트 횟수가 있는 저장 프로시저 사용 및 다중 결과 집합 사용을 참조하십시오.
=======================
=======================
=======================
출처: http://dualist.tistory.com/92
JAVA에서 MS-SQL 스토어드 프로시저 사용하기에 관한 글을 일전에 정리해서 올린적이 있다.
그 내용과 병행해서 보면 더욱 좋다.
이번에 쓸 내용은 프로시저내에서 output 변수로 선언된 값을 JAVA 에서 출력해주는 부분이다.
출처 : http://pcguy7.springnote.com/pages/1044536
CallableStatement
: SQL의 스토어드프로시저(Stored Procedure)를 실행시키기 위해 사용되는 인터페이스 이다.
스토어드프로시저란
: query문을 하나의 파일 형태로 만들거나 데이터베이스에 저장해 놓고 함수처럼 호출해서 사용하는 것임.
이것을 이용하면 연속되는 query문에 대해서 매우 빠른 성능을 보인다.
보안적인 장점 역시 가지고 있음.
스토어드프로시저로 값을 받아오려면,
호출하기에 앞서 반드시 CallableStatement인터페이스의 registerOutParameter()메서드를 호출해야 함.
이 인터페이스는 PreparedStatement 인터페이스로부터 상속 받았기 때문에 setXXX()메서드를 사용할 수 있다.
(CallableStatement 예제)
CallableStatementTest.java
import java.sql.*;
public class CallableStatementTest{
public static void main(String[] args){
try{
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection con = DriverManager.getConnection("jdbc:odbc:dbdsn", "id", "password");
CallableStatement cs = con.prepareCall("{call myStoredProcedure(?,?,?)}");
cs.setInt(1,2);
cs.registerOutParameter(2, java.sql.Types.VARCHAR);
cs.registerOutParameter(3, java.sql.Types.INTEGER);
cs.execute();
System.out.println("*name : "+ cs.getString(2) +"*age : "+ cs.getInt(3));
cs.close();
con.close();
}catch(Exception e){System.out.println(e);}
}
}
C:\JavaExample\19>javac CallableStatementTest.java
C:\JavaExample\19>java CallableStatementTest
*name : Jabook *age : 2
MS-SQL에서의 스토어드프로시저 myStoredProcedure 작성구문
CREATE PROCEDURE myStoredProcedure
@age int
, @na varchar(20) OUTPUT
, @ageo int OUTPUT
AS
SELECT @na = name, @ageo = age FROM mytest
Where age = @age
주의 1. Java의 코드에는 SQL의 query문이 들어가 있지 않았음.
그리고 위에 정리해 놓은 것처럼, SQL서버 자체에 스토어드프로시저를 작성하여 query를 작성해 놓음.
위에서 골뱅이(@)가 붙은 것들이 매개변수이고 그 중에서도 뒤에 OUTPUT이라고 붙은 것들이 리턴 될 값.
CallableStatement객체 cs를 생성하여 프로시저를 호출하기 위한 prepareCall()메서드를 사용한다.
여기서 물음표(?)가 프로시저로 전달되고 받아올 매개변수인 것입니다.
CallableStatement cs = con.prepareCall("{call myStoredProcedure(?, ?, ?)}");
setXXX()메서드를 이용하여 프로시저에 사용할 인자값을 넣어주게 됨.
그리고 리턴되는 값들을 받아야 겠죠. 일반 메서드와 달리 여러 개의 인자값을 받을 수 있음.
이때 스토어드프로시저에서 넘어오는 값을 얻기 위해서 registerOutParameter()메서드를 이용하여
반환되는 값들을 셋팅하게 됩니다.
cs.setInt(1,2);
cs.registerOutParameter(2, java.sql.Types.VARCHAR);
cs.registerOutParameter(3, java.sql.Types.INTEGER);
반환되는 값을 얻기 위해서는 CallableStatement를 실행한 후 다음과 같이 반환값을 얻어 낼 수 있습니다.
cs.execute();
System.out.println("*name : "+ cs.getString(2) +"*age : "+ cs.getInt(3));
CallableStatement인터페이스는 데이터베이스의 스토어드프로시저를 호출하기 위해
prepareCall()메서드를 이용하여 CallableStatement객체를 생성한다.
그 prepareCall()메서드는 Connection인터페이스의 메서드.
스토어드프로시저를 실행하기 전에 받아올 값에 대비하기 위해서
registerOutParameter()메서드를 사용하는 주의 할점.
☞ Callable
Statement
데이터베이스의 스토어드프로시저를 실행시키기 위해 사용되는 메서드.
스토어드프로시저를 사용하면 속도, 코드의 독립성, 보안성등의 다양한 이점을 얻을 수 있다.
CallableStatement인터페이스 주요 메서드
public void registerOutParameter(int parameterIndex, int sqlType) throws SQLException
: 프로시저로 받아온 값을 JDBC타입으로 등록.
모든 받아온 값은 반드시 이 과정을 거쳐야 합니다.
대표적인 sqlType을 알아보면 NULL, FOLAT, INTEGER, DATE등이 있습니다.
*PreparedStatement클래스를 상속하므로 getXXX()등, PreparedStatement가 가지고 있는 메서드를 사할수 있음.
CallableStatement cs = con.prepareCall("{call myStoredProcedure(?,?,?)}");
cs.setInt(1, 2);
cs.registerOutParameter(2, java.sql.Types.VARCHAR);
cs.registerOutParameter(3, java.sql.Types.INTEGER);
cs.execute();
System.out.println("*name : " + cs.getString(2) + "*age : " + cs.getInt(3));
cs.close();registerOutParameter() 이 메소드는 프로시져에서 OUT으로 선언한 변수값
=======================
=======================
=======================
출처: http://pantarei.tistory.com/587
SQL Server에서 SELECT 결과를 리턴하는 경우

CallableStatement cs = null;
ResultSet rs = null;
try {
cs = con.prepareCall("{ ? = call PR_AUTH('TEAM', ?, 'emp_no', ?) }");
cs.registerOutParameter(1, Types.OTHER); //리턴값이 결과집합임.
cs.setString(2, "A");
cs.registerOutParameter(3, Types.INTEGER);
if (cs.execute()) {
rs = (ResultSet) cs.getResultSet();
while (rs.next()) {
out.println(rs.getString(1) + "\t" + rs.getString(2));
}
out.println("code:" + cs.getInt(3));
}
} finally {
close rs, cs, con;
}
getDatabaseProductName : Microsoft SQL Server
getDatabaseProductVersion : 9.00.1399
getDriverName : Microsoft SQL Server 2005 JDBC Driver
getDriverVersion : 1.2.2828.100
getDriverVersion(int) : 1.2
getJDBCVersion : 3.0
- 위와 동일한 환경에서 PreparedStatement로 프로시저 실행
PreparedStatement ps = null;
...
ps = con.prepareStatement("EXEC PR_AUTH 'TEAM', ?, 'emp_no', '' ");
ps.setString(1, "A"); //input인자는 가능하지만 마지막에 위치한 output인자는 지정할 수 없다(PreparedStatement에는 registerOutParameter()가 없다.)
ResultSet rs = ps.executeQuery();
while (rs.next()) {
out.println(rs.getString(1) + "===>" + rs.getString(2) + "<br />");
}
[todo] openquery로도 가능하지 않나?
=======================
=======================
=======================
출처: http://installed.tistory.com/entry/5-JDBC-CallableStatement-%EB%8F%99%EC%A0%81%EC%BB%A4%EC%84%9C
1. CallableStatement
- PreparedStatement를 상속받은 인터페이스로 저장프로시져를 호출하는 기능을 갖음.
2. 테스트
1) 프로시져 생성.
PROCEDURE MEMPROC
CREATE OR REPLACE PROCEDURE MEMPROC
(
ID MEMBERS.ID % TYPE,
PWD VARCHAR2,
EMAIL VARCHAR2,
PHONE VARCHAR2
)
IS
BEGIN
INSERT INTO MEMBERS
VALUES(ID, PWD, EMAIL, PHONE, SYSDATE);
COMMIT;
END;
/
EX> DB접속 CLASS
DBConnection.java
package test.db;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DBConnection {
public static Connection getCon() throws SQLException{
Connection con=null;
try{
Class.forName("oracle.jdbc.OracleDriver");
String url="jdbc:oracle:thin:@localhost:1521:XE";
con= DriverManager.getConnection(url,"scott","tiger");
return con;
}catch(ClassNotFoundException ce){
System.out.println(ce.getMessage());
return null;
}
}
}
EX> 프로시져 호출하기.
Test01.java
package test01.jdbc;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.SQLException;
import test.db.DBConnection;
class MyJdbc01 {
public MyJdbc01() {
Connection con = null;
CallableStatement cstmt = null;
try {
con = DBConnection.getCon();
System.out.println("db접속성공!");
//String sql="{call 프로시져명(파라미터,...)}";
String sql = "{call memproc(?,?,?,?)}";
cstmt = con.prepareCall(sql);
//?에 대응되는 파라미터값들 넣기
cstmt.setString(1, "yb");
cstmt.setString(2, "8765");
cstmt.setString(3, "yb@naver.com");
cstmt.setString(4, "010-111-1111");
//프로시져호출하기
cstmt.execute();
System.out.println("프로시져가 성공적으로 호출되었어요!");
} catch (SQLException se) {
System.out.println(se.getMessage());
} finally {
try {
if (cstmt != null) cstmt.close();
if (con != null) con.close();
} catch (SQLException se) {
System.out.println(se.getMessage());
}
}
}
}
public class Test01 {
public static void main(String[] args) {
new MyJdbc01();
}
}
3. 동적 커서
- 리졀트셋 커서를 앞뒤로 자유롭게 이동. 기본적으로 커서는 앞으로만 이동할수 있고 읽기전용으로 설정되어 있음.
- 설정방법
Statement stmt= con.createStatement(
ResultSet.TYPE_SCROLL_INSENSITIVE,//커서이동방법
ResultSet.CONCUR_UPDATABLE //수정가능한 모드
);
EX> Test02.java
package test01.jdbc;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import test.db.DBConnection;
class MyJdbc02 {
public MyJdbc02() {
Connection con = null;
Statement stmt = null;
ResultSet rs = null;
try {
con = DBConnection.getCon();
System.out.println("db접속성공!");
//Statement createStatement(int resultSetType,
//int resultSetConcurrency) throws SQLException
stmt = con.createStatement(
ResultSet.TYPE_SCROLL_INSENSITIVE, //커서앞뒤로이동가능
ResultSet.CONCUR_UPDATABLE //수정가능한 모드
);
String sql = "select id,pwd,email,phone,regdate " +
"from members " +
"order by regdate desc";
rs = stmt.executeQuery(sql);
System.out.println("<< 앞에서부터 출력 >>");
while (rs.next()) {
//문자열을 전체 10자리로 출력.출력방향은 왼쪽기준(왼쪽정렬)
System.out.printf("%-10s", rs.getString(1));
System.out.printf("%-10s", rs.getString(2));
System.out.printf("%-15s", rs.getString(3));
System.out.printf("%-15s", rs.getString(4));
System.out.printf("%-15s\n", rs.getString(5));
}
System.out.println("<< 뒤에서부터 출력 >>");
while (rs.previous()) {
//문자열을 전체 10자리로 출력.출력방향은 왼쪽기준(왼쪽정렬)
System.out.printf("%-10s", rs.getString(1));
System.out.printf("%-10s", rs.getString(2));
System.out.printf("%-15s", rs.getString(3));
System.out.printf("%-15s", rs.getString(4));
System.out.printf("%-15s\n", rs.getString(5));
}
rs.absolute(1); //맨첫번째 행으로 이동
rs.deleteRow(); //현재행을 삭제
System.out.println("첫번째 데이터가 삭제되었어요!!!");
} catch (SQLException se) {
System.out.println(se.getMessage());
} finally {
try {
if (rs != null) rs.close();
if (stmt != null) stmt.close();
if (con != null) con.close();
} catch (SQLException se) {}
}
}
}
public class Test02 {
public static void main(String[] args) {
new MyJdbc02();
}
}
=======================
=======================
=======================
출처: http://m.cafe.daum.net/smartsolution3/Re4N/8?q=D_CDCHocTi6vM0&
<
% @ page
import = "java.sql.*" % >
<
% @ page contentType = "text/html; charset=euc-kr" % >
<
% request.setCharacterEncoding("EUC-KR"); //한글 깨짐을 방지합니다.%>
<
%
Statement stmt = null;
ResultSet rs = null;
//JDBC 드라이브 연결
Class c = Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
String url = "jdbc:sqlserver://211.115.92.231:1433;DatabaseName=A_Basezone_co_kr_mall";
String id = "basezone001";
String pass = "bz001";
Connection conn = DriverManager.getConnection(url, id, pass);
stmt = conn.createStatement();
//쿼리 실행
rs = stmt.executeQuery("APP_MAP_ZONE_LIST '1','20','CAMP_NAME','중도유원지',' ',' '");
while (rs.next()) {
String str1 = rs.getString(1);
String str2 = rs.getString(2);
String str3 = rs.getString(3);
out.println(str1 + " : " + str2 + " : " + str3 + "<br>");
}
%
>
=======================
=======================
=======================
1.저장프로시저
(1)저장프로시저의 개요
<1>개념
-SQL서버에서 제공되는 프로그래밍 기능
-쿼리문의 집합으로 어떠한 동작을 일괄처리하기 위한 용도로 사용된다.
<2>구문형식
//생성
CREATE PROCEDURE usp_users
AS
SELECT * FROM userTbl;
//실행
EXEC usp_user;
<3>수정과 삭제
수정은 ALTER PROCEDURE
삭제는 DROP PROCEDURE
<4>매개변수의 사용
[구문형식]
정의 : @입력매개벽수이름 데이터형식 [ = 디폴트값]
@출력매개변수이름 데이터형식 OUTPUT
실행
EXECUTE 프로시저이름 [전달값]
EXECUTE 프로시저이름 @변수명 OUTPUT
<5>프로그래밍 기능
프로그래밍 기능을 이용해 유연한 기능으로 확장 가능하다.
<6>리턴 값 사용
RETURN값을 사용해서 성공 및 실패 여부를 확인할 수 있다.
<7>저장프로시저 내 오류처리
@@ERROR 함수 및 TRY/CATCH문을 이용한다.
<8>임시저장프로시저
#(임시)또는 ##(전역)을 붙인다
TEMPDB에 저장된다.
(2)저장프로시저의 사용
USE master;
RESTORE DATABASE sqlDB FROM DISK = 'C:\sqlDB.bak' WITH REPLACE
USE sqlDB;
GO
CREATE PROCEDURE usp_users1
@userName NVARCHAR(10)
AS
SELECT * FROM userTbl WHERE name = @userName;
GO
EXEC usp_users1 '이천수';
//입력매개변수가 두 개인 경우
CREATE PROCEDURE usp_users2
@userBirth INT,
@userHeight INT
AS
SELECT * FROM userTbl
WHERE birthYear > @userBirth AND height > @userHeight;
GO
EXEC usp_users2 1980, 180;
//입력매개변수의 순서를 바꾸고 싶다면
EXEC usp_users2 @userHeight=180, @userBirth=1980 ;
//디폴트매개변수
CREATE PROCEDURE usp_users3
@userBirth INT = 1980,
@userHeight INT = 180
AS
SELECT * FROM userTbl
WHERE birthYear > @userBirth AND height > @userHeight;
GO
//아래와 같이 매개변수없이도 사용할 수 있다.
EXEC usp_users3;
//출력매개변수
//프로시저 내의 테이블이 없더라도 정의는 된다.
CREATE PROCEDURE usp_users4
@txtValue NCHAR(10),
@outValue INT OUTPUT
AS
INSERT INTO testTbl VALUES(@txtValue);
SELECT @outValue = IDENT_CURRENT('testTbl'); -- 테이블의 identity 값
GO
CREATE TABLE testTbl (id INT IDENTITY, txt NCHAR(10));
GO
//출력매개변수의 사용
DECLARE @myValue INT;
EXEC usp_users4 '테스트값1', @myValue OUTPUT;
PRINT '현재 입력된 ID 값 ==> ' + CAST(@myValue AS CHAR(5));
//SQL프로그래밍
//정의
CREATE PROC usp_ifElse
@userName nvarchar(10)
AS
DECLARE @bYear INT -- 생년을 저장할 변수
SELECT @bYear = birthYear FROM userTbl
WHERE name = @userName;
IF (@bYear >= 1980)
BEGIN
PRINT N'아직 젊군요..';
END
ELSE
BEGIN
PRINT N'나이가 지긋하네요..';
END
GO
//실행
EXEC usp_ifElse '박주영';
//CASE문
CREATE PROC usp_case
@userName nvarchar(10)
AS
DECLARE @bYear INT
DECLARE @tti NCHAR(3) -- 띠
SELECT @bYear = birthYear FROM userTbl
WHERE name = @userName;
SET @tti =
CASE
WHEN ( @bYear%12 = 0) THEN '원숭이'
WHEN ( @bYear%12 = 1) THEN '닭'
WHEN ( @bYear%12 = 2) THEN '개'
WHEN ( @bYear%12 = 3) THEN '돼지'
WHEN ( @bYear%12 = 4) THEN '쥐'
WHEN ( @bYear%12 = 5) THEN '소'
WHEN ( @bYear%12 = 6) THEN '호랑이'
WHEN ( @bYear%12 = 7) THEN '토끼'
WHEN ( @bYear%12 = 8) THEN '용'
WHEN ( @bYear%12 = 9) THEN '뱀'
WHEN ( @bYear%12 = 10) THEN '말'
ELSE '양'
END;
PRINT @userName + '의 띠==> ' + @tti;
GO
EXEC usp_case '송종국';
//CURSOR 사용
USE sqlDB;
GO
ALTER TABLE userTbl
ADD grade NVARCHAR(5); -- 고객등급 열 추가
GO
CREATE PROCEDURE usp_while
AS
DECLARE userCur CURSOR FOR-- 커서 선언
//데이터조회
SELECT U.userid,sum(price*amount)
FROM buyTbl B
RIGHT OUTER JOIN userTbl U
ON B.userid = U.userid
GROUP BY U.userid, U.name
OPEN userCur -- 커서열기
DECLARE @id NVARCHAR(10) -- 사용자아이디를 저장할 변수
DECLARE @sum BIGINT -- 총구매액을 저장할 변수
DECLARE @userGrade NCHAR(5) -- 고객 등급 변수
FETCH NEXT FROM userCur INTO @id, @sum -- 첫행 값을 대입
WHILE (@@FETCH_STATUS=0) -- 행이 없을 때까지 반복(즉, 모든 행 처리)
BEGIN
SET @userGrade =
CASE
WHEN (@sum >= 1500) THEN N'최우수고객'
WHEN (@sum >= 1000) THEN N'우수고객'
WHEN (@sum >= 1 ) THEN N'일반고객'
ELSE N'유령고객'
END
UPDATE userTbl SET grade = @userGrade WHERE userID = @id
FETCH NEXT FROM userCur INTO @id, @sum -- 다음행 값을 대입
END
CLOSE userCur -- 커서 닫기
DEALLOCATE userCur -- 커서 해제
GO
SELECT * FROM userTbl
EXEC usp_while;
SELECT * FROM userTbl;
CREATE PROC usp_return
@userName nvarchar(10)
AS
DECLARE @userGrade NVARCHAR(5);
SELECT @userGrade = grade FROM userTbl
WHERE name = @userName;
IF (@userGrade <> '')
RETURN 0; -- 성공일 경우, 그냥 RETURN만 써도 0을 돌려줌
ELSE
RETURN -1; -- 실패일 경우(즉, 해당 이름의 ID가 없을 경우)
GO
//CURSOR를 사용한 프로시저의 사용
DECLARE @retVal INT ;
EXEC @retVal=usp_return '안정환' ;
SELECT @retVAl;
DECLARE @retVal INT ;
EXEC @retVal=usp_return '우재남' ;
SELECT @retVAl;
//에러를 출력하는 프로시저
CREATE PROC usp_error
@userid nvarchar(10),
@name nvarchar(10),
@birthYear INT = 1900,
@addr NCHAR(4) = '서울',
@mobile1 NCHAR(3) = NULL,
@mobile2 NCHAR(8) = NULL,
@height smallInt = 180
AS
DECLARE @err INT;
INSERT INTO userTbl(userID,name,birthYear,addr,mobile1,mobile2,height)
VALUES (@userid,@name,@birthYear,@addr,@mobile1,@mobile2,@height);
SELECT @err = @@ERROR;
IF @err != 0
BEGIN
PRINT '###' + @name + '을(를) INSERT에실패했습니다. ###'
END;
RETURN @err; -- 오류번호를 돌려줌.
GO
DECLARE @errNum INT;
EXEC @errNum = usp_error 'WDT','우당탕' ;
IF (@errNum != 0)
SELECT @errNum;
//TRY...CATCH를 이용한 에러 프로시저
CREATE PROC usp_tryCatch
@userid nvarchar(10),
@name nvarchar(10),
@birthYear INT = 1900,
@addr NCHAR(4) = '서울',
@mobile1 NCHAR(3) = NULL,
@mobile2 NCHAR(8) = NULL,
@height smallInt = 180
AS
DECLARE @err INT;
BEGIN TRY
INSERT INTO
userTbl(userID,name,birthYear,addr,mobile1,mobile2,height)
VALUES (@userid, @name, @birthYear, @addr, @mobile1,
@mobile2, @height)
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER()
SELECT ERROR_MESSAGE()
END CATCH
GO
EXEC usp_tryCatch 'DRJY','따라쟁이' ;
USE sqlDB;
//현재 저장프로시저의 정보를 출력
SELECT o.name, m.definition
FROM sys.sql_modules m
JOIN sys.objects o
ON m.object_id = o.object_id AND o.TYPE = 'P';
//저장프로시저의 내용확인
EXECUTE sp_helptext usp_error;
//저장프로시저의 내용을 외부에서 볼 수 없도록 정의하기
CREATE PROC usp_Encrypt WITH ENCRYPTION
AS
SELECT SUBSTRING(name,1,1) + 'OO' as [이름],
birthYear as '출생년도', height as '신장' FROM userTbl;
GO
EXECUTE usp_Encrypt;
EXECUTE sp_helptext usp_Encrypt; //저장프로시저의 정의를 볼 수 없다.
//임시저장프로시저
CREATE PROC #usp_temp
AS
SELECT * FROM userTbl;
GO
EXEC #usp_temp;
//아래의 구문도 임시저장프로시저다.
EXEC sp_executesql N'SELECT * FROM userTbl';
(3)저장프로시저의 특징
-SQL 서버의 성능을 향상시킬 수 있다.
(동일한 저장프로시저를 자주 사용하는 경우에는 일반쿼리를 반복적으로 실행하는 것보다 성능이 향상된다.)
-모듈식 프로그래밍이 가능하다
-보안을 강화할 수 있다(사용자별로 테이블에 접근권한을 주지 않고 , 저장프로시저에만 접근할 수 있는 권한을 주는 방식으로)
-네트워크전송량의 감소시킨다.(저장프로시저 이름 및 매개변수 등 몇 글자의 텍스트만 전송하면 된다)
(4)저장프로시저의 종류
<1>사용자 정의 저장프로시저
[T-SQL 저장프로시저]
사용자가 직접 CREATE PROCEDURE 문을 이용해서 생성한 프로시저
[CLR 저장프로시저]
.NET Framework 어셈블리의 클래스에 공용의 정적메소드로 구현한다.
<2>확장 저장프로시저
C언어 등을 이용하여 데이터베이스에서 구현하기 어려운 것들을 구현한 저장프로시저,
앞으로 없어질 예정이다. CLR 저장프로시저로 대체되고 있다.
<3>시스템 저장프로시저
시스템을 관리하기 위해서 SQL 서버가 제공하는 저장프로시저로 SQL 서버의 관리와 관련된 작업을 위해서 주로 사용된다.
주로 sp_ 접두어로 작성되어 있다. 사용자저장프로시저에는 sp_접두를 사용하지 않는 것이 혼동예방에 좋다.
2.저장프로시저의 작동
(1)일반 T-SQL의 작동
[1회 실행시]
일반T-SQL - 구문분석 - 개체이름확인 - 사용권한확인 - 최적화 - 컴파일 및 실행계획 등록 ---(메모리캐쉬) --- 실행
[2회이후의 실행시]
일반T-SQL - 메모리(캐쉬)확인 - 실행
//2회이후의 동일실행으로 인식하기 위해서는 대소문자,띄워쓰기 하나까지 똑같은 쿼리어야 한다.
//테스트
SET STATISTICS TIME ON ; //경과시간표시되도록
USE AdventureWorks;
SELECT P.ProductNumber, P.Name AS Product, V.Name AS Vendor, PV.LastReceiptCost
FROM Production.Product AS P
JOIN Purchasing.ProductVendor AS PV ON P.ProductID = PV.ProductID
JOIN Purchasing.Vendor AS V ON V.VendorID = PV.VendorID
ORDER BY P.Name ;
//1회 608ms걸렸다.
SELECT P.ProductNumber, P.Name AS Product, V.Name AS Vendor, PV.LastReceiptCost
FROM Production.Product AS P
JOIN Purchasing.ProductVendor AS PV ON P.ProductID = PV.ProductID
JOIN Purchasing.Vendor AS V ON V.VendorID = PV.VendorID
ORDER BY P.Name ;
//2회에서는 1ms걸렸다.
//아래는 쿼리의 문장을 약간 바꾸어서 실행을 해서 실행을 하면
sELECT P.ProductNumber, P.Name AS Product, V.Name AS Vendor, PV.LastReceiptCost
FROM Production.Product AS P
JOIN Purchasing.ProductVendor AS PV ON P.ProductID = PV.ProductID
JOIN Purchasing.Vendor AS V ON V.VendorID = PV.VendorID
ORDER BY P.Name ;
//처음의 실행은 아니지만 27ms걸렸다.
SELECT P.ProductNumber, P.Name AS Product, V.Name AS Vendor, PV.LastReceiptCost
FROM Production.Product AS P
JOIN Purchasing.ProductVendor AS PV ON P.ProductID = PV.ProductID
JOIN Purchasing.Vendor AS V ON V.VendorID = PV.VendorID
ORDER BY P.Name ;
(2)저장프로시저의 작동
[저장프로시저 정의시]
저장프로시저 정의 - 구문분석 - 지연된 이름확인 - 생성권한 확인 - 카탈로그 뷰에 등록
관련카탈로그 뷰로는 sys.objects와 sys.sqLmodules가 있다.
[저장프로시저 1회실행시]
저장프로시저 1회실행 - 카탈로그뷰로 부터 개체이름확인 - 사용권한확인 - 최적화 -
컴파일 및 실행계획등록 ---(메모리 캐쉬) --- 실행
[저장프로시저 2회이후실행시]
저장프로시저 2회실행 - 메모리캐쉬 - 실행
//테스트
SET STATISTICS TIME ON ;
USE AdventureWorks;
//프로시저정의 - 카탈로그 뷰에 등록
CREATE PROCEDURE usp_Prod
AS
SELECT P.ProductNumber, P.Name AS Product, V.Name AS Vendor, PV.LastReceiptCost
FROM Production.Product AS P
JOIN Purchasing.ProductVendor AS PV ON P.ProductID = PV.ProductID
JOIN Purchasing.Vendor AS V ON V.VendorID = PV.VendorID
ORDER BY P.Name ;
GO
//1회 실행
EXEC usp_Prod;
//34mms 걸렸다.
//2회실행시 1ms
SET STATISTICS TIME OFF;
-- 여기서 잠깐(P577)
SELECT * FROM userTbl WEHRE id = 'AJH';
SELECT * FROM userTbl WEHRE id = 'LCS';
SELECT * FROM userTbl WEHRE id = 'JJJ';
CREATE PROC usp_id
@id NVARCHAR(10)
AS
SELECT * FROM userTbl WHERE userID = @id
EXEC usp_id 'AJH';
EXEC usp_id 'LCS';
EXEC usp_id 'JJJ';
(3)WITH RECOMPILE옵션과 문제점
[저장 프로시저의 문제점과 해결책]
-처음 수행시에 최적화가 이루어지기 때문에
두번째 실행시에는 그 최적화가 더 안좋은 성능을 내더라도
이미 컴파일이 된 저장프로시저를 계속사용하게 된다.(인덱스관련해서 발생하는 경우가 많다)
-해결책은 재컴파일하는 방법이다.
[재컴파일하는 방법] - 4가지 방법
-실행시에 WITH RECOMPILE옵션을 사용하면 된다.
-항상 실행시마다 자동으로 재컴파일되도록 프로시저 생성
-sp_recompile '테이블이름 ' 시스템 저장프로시저를 사용한다.
-DBCC FREEPROCCACHE를 사용한다.(프로시저의 메모리를 비운다)
USE sqlDB;
Select * INTO spTbl from AdventureWorks.Sales.Customer ORDER BY rowguid; //2만건 정도 삽입CREATE NONCLUSTERED INDEX idx_spTbl_id on spTbl (CustomerID); //비클러스터형 인덱스 생성
//10건이하는 인덱스를 사용하는 거이 빠르다
SELECT * FROM spTbl WHERE CustomerID < 10;
//아래경우에는 비클러스터형인덱스를 사용하는 것보다 테이블스캔보다 느리다.
SELECT * FROM spTbl WHERE CustomerID < 5000;
//프로시저 생성
CREATE PROC usp_ID
@id INT
AS
SELECT * FROM spTbl WHERE CustomerID < @id;
GO
EXEC usp_ID 10;
//이미 인덱스를 쓰기로 결정되었기 때문에 시간이 더 많이 걸린다.
EXEC usp_ID 5000;
//위 문제의 해결 - 다시 컴파일해서 테이블스캔으로 최적화 시킨다.
//WITH RECOMPILE옵션은 메모리에 등록해주지 않는다. 지금하는 것만 최적화한다.
//WITH RECOMPILE옵션을 사용하지않으면 다시 메모리에 있는 데이터를 캐쉬해와서 최적화가 되지 않는다.
EXEC usp_ID 5000 WITH RECOMPILE;
//컴파일하고 메모리도 업데이트한다.
EXEC sp_recompile spTbl;
EXEC usp_ID 10;
EXEC usp_ID 10;
//메모리를 다 비운다.
DBCC FREEPROCCACHE;
EXEC usp_ID 5000;
DROP PROC usp_ID;
GO
//프로시저를 실행할 때마다 재컴파일한다.
CREATE PROC usp_ID
@id INT
WITH RECOMPILE
AS
SELECT * FROM spTbl WHERE CustomerID < @id;
GO
3.사용자정의 함수
(1)사용자정의 함수의 개요
저장프로시저와 조금 비슷해보이지만 ,
일반적인 프로그래밍 언어에서 사용되는 함수와 같이 복잡한 프로그래밍이 가능하다
함수는 RETURN문에 의해서 특정값을 되돌려 준다.
저장프로시저는 EXEC에 의해서 실행되지만 ,
함수는 주로 SELECT문에 포함되어 실행된다(예외도 있다)
(2)함수의 정의
USE sqlDB;
GO
CREATE FUNCTION ufn_getAge(@byear INT) -- 매개변수를 정수로 받음 //나이추출함수
RETURNS INT -- 리턴값은 정수형
AS
BEGIN
DECLARE @age INT
SET @age = YEAR(GETDATE()) - @byear
RETURN(@age)
END
GO
//함수호출
SELECT dbo.ufn_getAge(1979); -- 호출시 스키마명을 붙여줘야 함
//이렇게 함수호출할 수도 있지만 권장하지도 않는다.
DECLARE @retVal INT;
EXEC @retVal = dbo.ufn_getAge 1979;
PRINT @retVal;
SELECT userID, name, dbo.ufn_getAge(birthYear) AS [만 나이] FROM userTbl;
//함수 정의 변경
ALTER FUNCTION ufn_getAge(@byear INT)
RETURNS INT
AS
BEGIN
DECLARE @age INT
SET @age = YEAR(GETDATE()) - @byear + 1
RETURN(@age)
END
GO
//함수 삭제
DROP FUNCTION ufn_getAge;
(3)함수의 종류
[시스템 함수]
SQL서버가 제공해주는 함수
[사용자정의 스칼라함수]
RETURN문에 의해서 하나의 값을 돌려주는 함수
[사용자정의 테이블값 함수]
<인라인 테이블 함수>
-간단히 테이블을 돌려주는 함수로 뷰와 비슷한 역할을 한다.
CREATE FUNCTION 함수이름 (매개변수)
RETURN TABLE
AS
RETURN( 단일 SELECT 문장;)
<다중문 테이블함수>
-BEGIN..END로 정의되며 그 내부에 일련의 T-SQL을 이용해서 반환될 테이블에 행 값을 인서트하는 형식을 가진다.
CREATE FUNCTION 함수이름(매개변수)
RETURNS @테이블변수 TABLE
AS
BEGIN
위(헤더)에서 정의한 테이블에 행을 INSERT시키는 작업들..
END
(4)함수의 사용
USE sqlDB;
GO
//인라인 테이블 함수의 정의
CREATE FUNCTION ufn_getUser(@ht INT)
RETURNS TABLE
AS
RETURN (
SELECT userID AS [아이디], name AS [이름], height AS [키]
FROM userTbl
WHERE height > @ht
)
GO
//인라인테이블함수의 사용 -뷰와 비슷한 역할을 한다.
SELECT * FROM dbo.ufn_getUser(180);
CREATE FUNCTION ufn_userGrade(@bYear INT)
-- 리턴할 테이블의 정의(@retTable은 BEGIN..END에서 사용될 테이블변수임)
//테이블변수와 임시테이블은 거의 동일하게 사용할 수 있다.
RETURNS @retTable TABLE
( userID NVARCHAR(10),
name NVARCHAR(10),
grade NVARCHAR(5) )
AS
BEGIN
DECLARE @rowCnt INT;
-- 행의 개수를 카운트
SELECT @rowCnt = COUNT(*) FROM userTbl WHERE birthYear >= @bYear;
-- 행이 하나도 없으면 '없음'이라고 입력하고 테이블을 리턴함.
IF @rowCnt <= 0
BEGIN
INSERT INTO @retTable VALUES('없음','없음','없음');//
RETURN;
END;
-- 행이 1개이상 있다면 아래를 수행하게됨
INSERT INTO @retTable
SELECT U.userid, U.name,
CASE
WHEN (sum(price*amount) >= 1500) THEN N'최우수고객'
WHEN (sum(price*amount) >= 1000) THEN N'우수고객'
WHEN (sum(price*amount) >= 1 ) THEN N'일반고객'
ELSE N'유령고객'
END
FROM buyTbl B
RIGHT OUTER JOIN userTbl U
ON B.userid = U.userid
WHERE birthYear >= @bYear
GROUP BY U.userid, U.name;
RETURN;
END;
SELECT * FROM dbo.ufn_userGrade(1980);
SELECT * FROM dbo.ufn_userGrade(1990);
USE master;
RESTORE DATABASE sqlDB FROM DISK = 'C:\sqlDB.bak' WITH REPLACE
//
CREATE FUNCTION ufn_discount(@id NVARCHAR(10))
RETURNS BIGINT
AS
BEGIN
DECLARE @totPrice BIGINT;
-- 입력된 사용자id의 총구매액
SELECT @totPrice = sum(price*amount)
FROM buyTbl
WHERE userID = @id
GROUP BY userID ;
-- 총구매액에 따라서 차등된 할인율을 적용
SET @totPrice =
CASE
WHEN (@totPrice >= 1500) THEN @totPrice*0.7
WHEN (@totPrice >= 1000) THEN @totPrice*0.8
WHEN (@totPrice >= 500) THEN @totPrice*0.9
ELSE @totPrice
END;
-- 구매기록이 없으면 0원
IF @totPrice IS NULL
SET @totPrice = 0;
RETURN @totPrice;
END
SELECT userID, name, dbo.ufn_discount(userID) AS [할인된총구매액] FROM userTbl;
EXEC sp_rename 'buyTbl.price', 'cost', 'COLUMN'
SELECT userID, name, dbo.ufn_discount(userID) AS [할인된총구매액] FROM userTbl;
EXEC sp_rename 'buyTbl.cost', 'price', 'COLUMN'
//스키마 바운드함수로 수정
//스키마 바운드함수에서 참조하는 열은 변경할 수 없다.
//스키마 바운드함수로 변경하면 개체이름에 스키마이름을 지정해야한다.
//아래쿼리는 오류가 발생한다.
ALTER FUNCTION ufn_discount(@id NVARCHAR(10))
RETURNS BIGINT
WITH SCHEMABINDING
AS
BEGIN
DECLARE @totPrice BIGINT;
SELECT @totPrice = sum(price*amount)
FROM buyTbl
WHERE userID = @id
GROUP BY userID ;
SET @totPrice =
CASE
WHEN (@totPrice >= 1500) THEN @totPrice*0.7
WHEN (@totPrice >= 1000) THEN @totPrice*0.8
WHEN (@totPrice >= 500) THEN @totPrice*0.9
ELSE @totPrice
END;
IF @totPrice IS NULL
SET @totPrice = 0;
RETURN @totPrice;
END
//아래와같이 해야 오류가 사라진다.
ALTER FUNCTION ufn_discount(@id NVARCHAR(10))
RETURNS BIGINT
WITH SCHEMABINDING
AS
BEGIN
DECLARE @totPrice BIGINT;
-- 입력된사용자id의총구매액
SELECT @totPrice = sum(price*amount)
FROM dbo.buyTbl //스키마함수에서는 스키마.테이블로 적어야 한다.
WHERE userID = @id
GROUP BY userID ;
SET @totPrice =
CASE
WHEN (@totPrice >= 1500) THEN @totPrice*0.7
WHEN (@totPrice >= 1000) THEN @totPrice*0.8
WHEN (@totPrice >= 500) THEN @totPrice*0.9
ELSE @totPrice
END;
IF @totPrice IS NULL
SET @totPrice = 0;
RETURN @totPrice;
END
EXEC sp_rename 'buyTbl.price', 'cost', 'COLUMN'
//테이블변수 사용
DECLARE @tblVar TABLE (id NVARCHAR(10), name NVARCHAR(10), addr NVARCHAR(5));
INSERT INTO @tblVar
SELECT userID, name , addr FROM userTbl WHERE birthYear >= 1980;
SELECT * FROM @tblVar;
//임시테이블을 이용해서 위와 동일한 쿼리
CREATE TABLE #tmpTbl
(id NVARCHAR(10), name NVARCHAR(10), addr NVARCHAR(5));
INSERT INTO #tmpTbl
SELECT userID, name , addr FROM userTbl WHERE birthYear >= 1980;
SELECT * FROM #tmpTbl;
//
언제 테이블변수를 쓰고 언제 임시테이블변수를 써야할 것인가
-시스템의 성능을 고려한다면 소량의 데이터를 임시로 사용할 때는 테이블 변수가 유리할 수 있고,
대용량의 데이터를 임시로 사용할 때는 임시테이블이 더 나을 수도 있다.
그 이유는 임시테이블은 일반테이블이 갖는 모든 성격을 갖게 되므로
대용량의 데이터의 경우 비클러스터형 인덱스를생성할 수 있으나 ,
테이블변수에는 비클러스터형 인덱스를 생성할 수 없기 때문이다.
-테이블 변수는 명시적 트랜잭션내부에 있더라도 영향을 받지 않는다.
DECLARE @tblVar TABLE (id INT);
BEGIN TRAN
INSERT INTO @tblVar VALUES (1);
INSERT INTO @tblVar VALUES (2);
ROLLBACK TRAN
SELECT * FROM @tblVar;//롤백을 하더라도 테이블변수의 명시적트랜잭션의 영향을 받지않는 특성상 데이터는 그대로 나타나게 된다.
(5)사용자정의 함수의 제약사항
사용자정의함수 내부에 TRY ...CATCH문을 사용할 수 없다
사용자정의 함수 내부에 CREATE/LATER/DROP문을 사용할 수 없다.
오류가 발생하면 즉시 함수의 실행이 멈추고 값을 반환하지 않는다.
[출처] [MSSQL - 뇌를자극하는MSSQL2005-정리노트]저장프로시저와 사용자정의함수|작성자 장미빛바다
[출처] [MSSQL] 저장프로시저와 사용자정의함수|작성자 여유로움
=======================
=======================
=======================
'JAVA' 카테고리의 다른 글
| [JAVA] Http 송수신 HttpClient (0) | 2020.09.17 |
|---|---|
| [Java] OpenGL 구현 관련. (0) | 2020.09.17 |
| 자바 애플리케이션의 Windows 메모리 사용 관리 방법 (0) | 2020.09.17 |
| [Java] 자바 더블 버퍼링 이미지 처리 관련 (0) | 2018.08.20 |
| 자바 (자바강좌) 스레드 관련 (0) | 2016.10.27 |





댓글 영역