=======================
=======================
=======================

출처: http://berry2.tistory.com/m/post/509
CJK 유니코드
Unicode#
- Unicode offical site - http://unicode.org
- Wikipedia - http://en.wikipedia.org/wiki/Summary_of_Unicode_character_assignments
- UTF-8 encoding table : http://www.utf8-chartable.de/unicode-utf8-table.pl
UTF-8 인코딩에서 각 언어별 표현 영역#UTF-8 인코딩에서 한글을 표현하는 영역#
BlockUnicode codeUTF-8 Hex 비 고
| Hangul Jamo | U+1100 ~ U+11FF | 0xE1 0x84 0x80 ~ 0xE1 0x87 0xBF | 한글자모 |
| Hangul Compatibility Jamo | U+3130 ~ U+318F | 0xE3 0x84 0xB0 ~ 0xE3 0x86 0x8F | 한글호환자모 |
| Hangul Syllables | U+AC00 ~ U+D7AF | 0xEA 0xB0 0x81 ~ 0xED 0x9E 0xA3 | 한글 |
UTF-8 인코딩에서 일본어를 표현하는 영역#
BlockUnicode codeUTF-8 Hex 비 고
| Hiragana | U+3040 ~ U+309F | 0xE3 0x81 0x81 ~ 0xE3 0x82 0x9F | 일본어 히라가나 |
| Katakana | U+30A0 ~ U+30FF | 0xE3 0x82 0xA0 ~ 0xE3 0x83 0xBF | 일본어 카타카나 |
UTF-8 인코딩에서 한중일 한자를 표현하는 영역#
BlockUnicode codeUTF-8 Hex 비 고
| CJK Unified Ideographs | U+4E00 ~ U+9FFF | 0xE4 0xB8 0x80 ~ 0xE9 0xBF 0xBF | 한중일 공통 한자 |
| CJK Unified Ideographs Extension A | U+3400 ~ U+4DBF | 0xE3 0x90 0x80 ~ 0xE4 0xB6 0xBF | 한자 확장 A |
| CJK Unified Ideographs Extension B | U+20000 ~ U+2A6DF | 0xF0 0xA0 0x80 0x80 ~ 0xF0 0xAA 0x9B 0x9F | 한자 확장 B |
| CJK Compatibility Ideographs | U+F900 ~ U+FAFF | 0xEF 0xA4 0x89 ~ 0xEF 0xAB 0xBF | 한중일 호환 한자 |
History
Last edited on Jun 16, 2009 22:09 by 휘슬
=======================
=======================
=======================
- 숫자
char_ASCII >= 48 && char_ASCII <= 57
- 영어
char_ASCII>=65 && char_ASCII<=90
char_ASCII>=97 && char_ASCII<=122
- 한글
char_ASCII >= 12592) || (char_ASCII <= 12687
- 특수기호
char_ASCII>=33 && char_ASCII<=47
char_ASCII>=58 && char_ASCII<=64
char_ASCII>=91 && char_ASCII<=96
char_ASCII>=123 && char_ASCII<=126
아이디나 뭐 그런거 체크할 때 쓸만할 듯;;
출처 : http://blog.naver.com/kismo75/40016813752
=======================
=======================
=======================
출처: http://blog.ggaman.com/896
내용에 대해서 책임지지 않습니다. ㅋㅋ
Unicode provides a unique number for every character,
no matter what the platform,
no matter what the program,
no matter what the language.
http://www.unicode.org/standard/WhatIsUnicode.html
위에 설명되어 있는대로다.
유니코드란?
unicode는 모든 문자에 index를 줘 놓은 것이다. 더 이상도 아니고, 더 이하도 아니다.
이 index를 code point라고 부르는데, 그냥 index라고 칭하도록 하자.
'A'라는 글자는 0x0041 이라는 index를 가진다.
'a'라는 글자는 0x0061 이라는 index를 가진다.
'가'라는 글자는 0xac00 이라는 index를 가진다.
( 더 많은 글자와 index를 보려면 http://www.unicode.org/charts/ 를 참고하자 )
표현방법
저렇게 정해져 있는 index를 표시하는 방법에는 UTF와 UCS두가지 종류가 있다.
( UTF - Unicode Transformation Format , UCS - Universal Character Set )
UCS
UCS는 몇바이트로 index를 표현할 수 있느냐를 나타낸다.
즉 UCS-2는 2byte로 index를 나타낼꺼고 UCS-4는 4byte를 이용해서 index를 나타낼거라는거다.
UTF
UTF는 몇 비트단위로사용해서 index를 나타낼것인가를 말한다.
UTF-8은 8bit씩 늘려가며 index를 나타낼꺼라는거고,
UTF-16은 16bit씩 index를 나타낼꺼고, UTF-32는 32bit씩 index를 나타낼꺼라는거다.
( 실상 UTF-16과 UCS-2는 같다고 볼 수 있다. 마찬가지로 UTF-32와 UCS-4도 마찬가지다. 하지만 unicode 3.1에 오면서 달라 졌다. )
UTF-16
원래 처음에 unicode의 index는 2byte로 나타낼 수 있었다.
그랬는데, unicode 가 버젼업되어 4.0이 나왔을때에는 0x10FFFF 까지의 index가 생겼다.
처음에는 UTF-16으로 모든 문자를 나타낼 수 있었으나,
( 2byte로 표현할 수 있는 index를 가진 문자 목록을 BMP Basic Multilingual Plane 라고 부른다. )
유니코드 4.0이 나오면서, 2byte로는 0x10FFFF 같은 값을 가리킬 수 없게 되었다.
그래서 UTF-16으로는 BMP에 있는 문자들은 2byte로 처리하고,
BMP보다 더 높은 index를 가지는 놈들은 4byte로 처리 한다.
문자 index 0x0000 부터 0xFFFF 까지는 2byte로 처리 하고
문자 index 0x10000 부터 0x1FFFF 까지는 4byte로 처리 된다.
UTF-32
UTF-32는 기본적으로 4byte를 사용하기 때문에, 위와 같은 짓을 하지 않아도 된다.
UTF-8
영어권에 있는 사람들은 UTF-16을 쓰면 손해다.
모든 영어는 1byte만 있으면 256개를 표현할 수 있으므로, 모든 문자를 넣을 수 있기 때문이다.
그래서 나온게 UTF-8이다.
영어권은 1byte로 표현하고, 그것보다 높은 index를 가지는것은 2byte 혹은 3byte 혹은 4byte ..
요렇게 늘려 가면서 쓰도록 되어 있다.
서로간의 변환
UTF-8, UTF-16, UTF-32, UCS-2, UCS-4 는
모두 unicode의 문자 index를 나타내기 위한 방법이기 때문에,
서로간의 변환은 당연히 잘 된다. ( UCS-2는 한계를 가지고 있다. )
글자처리
우리가 글자 "가"를 쓴다고 해 보자. 글자 "가"는 1글자이다.
그러므로 "가"를 나타내는 index가 있다. 물론 "나"를 나타내는 index도 있다.
한글로 표현할 수 있는 글자는 매우 많다.
그 많은 글자 모두에게 index를 줄 수가 없다.
현재 사용하고 있는 모든 글자에 index를 준다고 해도,
시간이 지나서 새로운 글자가 추가 되어 index가 모자르게 된다면 어떻게 할것인가?
그래서 유니코드는 완전한 글자를 제공해 주기도 하지만,
글자를 조립할 수 있도록 조립가능한 글자를 제공해 준다.
다시 "가"를 쓴다고 해 보다.
"가"라는 글자는 1개이지만, 실제로는 초성 "ㄱ"과 중성"ㅏ" 가 합쳐져서 만들어진 글자이다.
그러므로 "가"를 표현하는 방법은 완성된 글자 "가"0xAC00가 될 수도 있고,
초성"ㄱ"과 중성"ㅏ"를 조립한 "가"0x1100,0x1161 로 나타낼 수도 있다.
( 초성 "ㄱ"은 0x1100 - HANGUL CHOSEONG KIYEOK )
( 중성 "ㅏ"는 0x1161 - HANGUL JUNGSEON A )
이를 조합할 수 있게 해 주는 index는 1100 부터 있다.
( Hangul Jamo - Korean combining alphabet - http://www.unicode.org/charts/PDF/U1100.pdf )
이는 비단 한글뿐만 아니라,
일본어 역시 완성된 글자가 있기도 하고, 조합할 수 있게도 되어 있다.
영어 역시 그렇다. 영어에서 무슨 글자를 조합하냐 라고 말하겠지만,
이력서를 나타내는 Resume 의 경우에는 e 와 ' 의 조합으로 이루어 질 수도 있다.
=======================
=======================
=======================
출처: http://mejiro.tistory.com/8
일본어 문자 코드 종류와 범위
일본어 문자코드는 인코딩 방식에 따라 다양하지만 대표적인 인코딩 방식과 코드범위는 아래와 같다.
ASCII(American Standard Code for Information Interchange)
| 코드 범위(16진수) | 내용 |
| 0x00 ~ 0x1F | 제어문자(control characters) |
| 0x20 | 공백(space) |
| 0x21 ~ 0x7E | 도형문자(graphic characters) |
| 0x7F | 제어문자 DEL(delete) |
ISO-2022-JP(JIS)
| 코드 범위(16진수) | 내용 |
| 0x00 ~ 0x1F, 0x7F | 제어코드 |
| 0x20 ~ 0x7E | ASCII 문자 |
| 0x21 ~ 0x5F | 반각 가타가나 |
| 0x2121 ~ 0x7E7E | 한자 |
| 0x2121 ~ 0x7E7E | 보조한자 |
코드 범위가 중복되어 escape를 이용하여 전환한다.
| 기호 표기 | 16진수 | 의미 |
| ESC (B | 1B 28 42 | ASCII |
| ESC (J | 1B 28 4A | JIS X 0201-1976 Roman Set |
| ESC (I | 1B 28 49 | JIS X 0201-1976 katakana |
| ESC $ @ | 1B 24 40 | JIS X 0208-1978(구 JIS) |
| ESC $ B | 1B 24 42 | JIS X 0208-1983(신 JIS) |
| ESC & ESC$ B | 1B 26 40 1B 24 42 | JIS X 0208-1990 |
| ESC $ (D | 1B 24 28 44 | JIS X 00212-1990(보조한자) |
Shift_JIS
| 1번째 바이트 | 2번째 바이트 | 문자 유형 |
| 0x00 ~ 0x1F, 0x7F | 제어문자 | |
| 0x20 ~ 0x7E | ASCII 문자 | |
| 0xA1 ~ 0XDF | 반각 가타가나 | |
| 0x81 ~ 0x9F 0xE0 ~ 0xFC |
0x40 ~ 0x7E 0x80 ~ 0xFC |
한자 |
EUC-JP
| 1번째 바이트 | 2번째 바이트 | 3번째 바이트 | 문자 유형 |
| 0x00 ~ 0x1F, 0x7F | 제어문자 | ||
| 0x20 ~ 0X7E | ASCII 문자 | ||
| 0xA1 ~ 0xFE | 0xA1 ~ 0xFE | 한자 | |
| 0x8E | 0xA1 ~ 0xDF | 반각 가타가나 | |
| 0x8F | 0xA1 ~ 0xFE | 0xA1 ~ 0xFE | 보조 한자 |
UTF-8
| 1번째 바이트 | 2번째 바이트 | 3번째 바이트 | 4번째 바이트 | 문자 유형 |
| 0x00 ~ 0x7F | ASCII 문자 | |||
| 0xC0 ~ 0xDF | 0x80 ~ 0xBF | 문자 | ||
| 0xE0 ~ 0xEF | 0x80 ~ 0xBF | 0x80 ~ 0xBF | 문자 | |
| 0xF0 ~ 0xF7 | 0x80 ~ 0xBF | 0x80 ~ 0xBF | 0x80 ~ 0xBF | 문자 |
| 0xEF | 0xBB | 0xBF | BOM |
문자코드 판정 출처
http://www.geocities.jp/gakaibon/tips/csharp2008/charset-check.html
보충 설명 2
http://www.geocities.jp/gakaibon/tips/csharp2008/charset-check2.html
보충 설명 3
http://www.geocities.jp/gakaibon/tips/csharp2008/charset-check3.html
문자코드 판정 소스코드
http://www.geocities.jp/gakaibon/tips/csharp2008/charset-check-samplecode1.html
http://www.geocities.jp/gakaibon/tips/csharp2008/charset-check-samplecode2.html
http://www.geocities.jp/gakaibon/tips/csharp2008/charset-check-samplecode3.html
문자코드판정 C# 프로그램과 소스코드(gkbSingleTextViewer)
http://www.geocities.jp/gakaibon/software.html
JIS X 0213과 Unicode Mapping Table
http://x0213.org/codetable/index.en.html
JIS-UCS Mapping Table
http://wakaba-web.hp.infoseek.co.jp/table/jis-note.ja.html
일본어 JIS, SJIS,EUC Mapping Table
http://www.kiko-net.com/Foreigners/Japanese_Language/JapaneseCodeTable.html
http://www.kiko-net.com/Foreigners/Japanese_Language/Japanese_Language.php
JIS X 0208과 Unicode 문자코드표
http://ash.jp/code/index.htm
한자검색 - 독음,분류,수준,GL,GR,SJIS,UCS 코드 표시
http://x0213.org/searchkanji/
일본어한자표일람
http://www.aozora.gr.jp/kanji_table/
문자셋,인코딩 이야기
http://yescapri.egloos.com/1770669
more..
=======================
=======================
=======================
출처: http://blog.lael.be/post/77
배경
인터넷이 전세계적으로 보급되면서 전세계 모든 언어를 다룰 수 있는 “다국어”라는 언어셋을 이용하게 되었다.
같은 내용을 저장했을 때 “다국어 언어셋”으로 작성된 문서는 “한국어 언어셋”으로 작성된 문서보다 용량이 크다.
요즘에는 필수적으로 웹사이트에서 다국어 언어셋(UTF-8 charset)을 사용합니다.
이론
ASCII 코드표를 보고 ASCII 영역을 파악합니다.
ASCII 코드표는 다음과 같습니다.
코드표는 Microsoft Office 고객지원 페이지에서 찾아볼 수 있습니다. (http://office.microsoft.com/ko-kr/infopath-help/HA010167539.aspx)


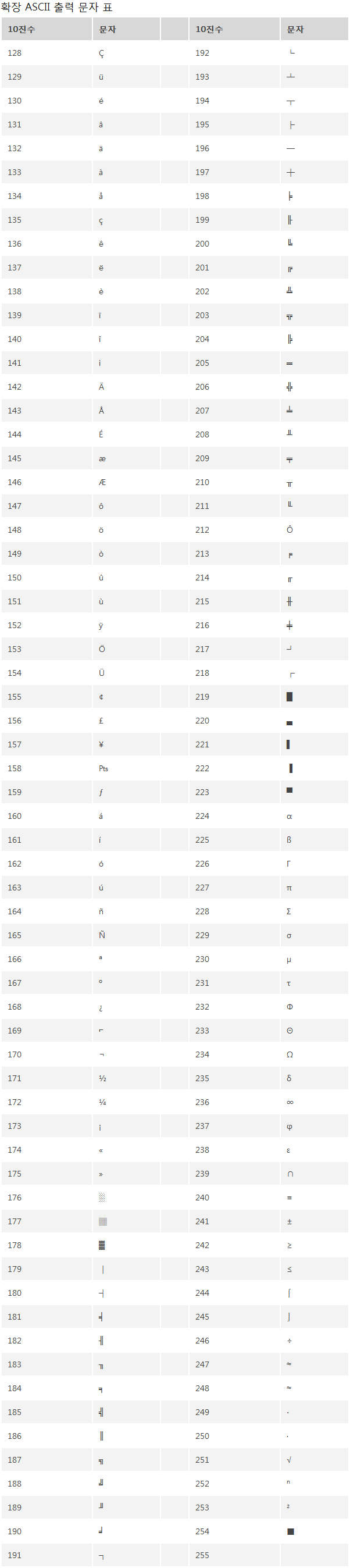
내용
글자 갯수를 체크하는 php내장함수 strlen을 이용합니다.
| echo strlen("한글").PHP_EOL;// echo strlen("한글@").PHP_EOL;// "@" 문자는 ASCII 코드 범위내에 있음 echo strlen("한글★").PHP_EOL;// "★" 문자는 ASCII 코드 범위외에 있음 echo strlen("한글a").PHP_EOL;// "a" 문자는 ASCII 코드 범위외에 있음 echo strlen("한글날").PHP_EOL;// "날" 문자는 ASCII 코드 범위외에 있음 |
1) “한국어” 환경에서 글자 수 체크
ASCII 범위안 : 1개 (1byte) 로 인정
ASCII 범위밖 : 2개 (2byte) 로 인정

2) “UTF-8″ 환경에서 글자 수 체크
ASCII 범위안 : 1개 (1byte) 로 인정
확장 ASCII 문자(위의 표 참조) : 2개 (2byte) 로 인정
그외 문자(한글 및 다국어) : 3개 (3byte) 로 인정
아직 나오지 않았지만 미래에 사용될 문자 : 4Byte 처리
UTF-8 (Unicode Trans Formation 8) 은 4바이트까지 크기가 늘어날 수 있는 가변길이(dynamic length;길이가 변하는) 문자셋입니다.
자세한 설명은 다음을 참조하세요 : http://helloworld.naver.com/helloworld/19187

3) 문자열은 String 이며 배열 인덱스를 이용해서 접근할 수 있다.
예를 들어
| $str = 'abcd'; |
라면
| echo $str[2]; // 배열인덱스는 0부터 시작 |
의 출력은 c 이다.
4) “UTF-8″ 환경에서 배열인덱스를 이용하여 아스키코드를 알아보자.
| $mb_str = '한~글★@'; $mb_str_length = strlen($mb_str); for($i=0;$i<$mb_str_length;$i++){ echo var_dump(ord($mb_str[$i])).'<br />'; } |
ord 함수는 (http://www.php.net/manual/en/function.ord.php) 변수로 넘겨진 문자의 아스키코드를 반환하는 함수이며
var_dump 함수는 (http://kr2.php.net/manual/en/function.var-dump.php) 변수로 넘겨진 값의 정보를 출력해 주는 함수이다.
결과는 다음과 같다.

5) UTF-8로 글자수를 세는 함수를 짜보자.
아스키코드표를 바탕으로 범위를 나누어서 카운트한다.
| function utf8_length($str) { $len = strlen($str); for ($i = $length = 0; $i < $len; $length++) { $high = ord($str{$i}); if ($high < 0x80)//0<= code <128 범위의 문자(ASCII 문자)는 인덱스 1칸이동 $i += 1; else if ($high < 0xE0)//128 <= code < 224 범위의 문자(확장 ASCII 문자)는 인덱스 2칸이동 $i += 2; else if ($high < 0xF0)//224 <= code < 240 범위의 문자(유니코드 확장문자)는 인덱스 3칸이동 $i += 3; else//그외 4칸이동 (미래에 나올문자) $i += 4; } return $length; } |
6) UTF-8로 문자열을 자르는 함수를 짜보자.
| function utf8_strcut($str, $chars, $tail = '...') { if (utf8_length($str) <= $chars)//전체 길이를 불러올 수 있으면 tail을 제거한다. $tail = ''; else $chars -= utf8_length($tail);//글자가 잘리게 생겼다면 tail 문자열의 길이만큼 본문을 빼준다. $len = strlen($str); for ($i = $adapted = 0; $i < $len; $adapted = $i) { $high = ord($str{$i}); if ($high < 0x80) $i += 1; else if ($high < 0xE0) $i += 2; else if ($high < 0xF0) $i += 3; else $i += 4; if (--$chars < 0) break; } return trim(substr($str, 0, $adapted)) . $tail; } |
Demo
1. 입력한 단어의 글자수를 세어줍니다. http://datalink.lael.be/qdic.kr/PHP-utf8_length.php
2. 입력한 단어에서 앞 20글자만 자릅니다. http://datalink.lael.be/qdic.kr/PHP-utf8_strcut.php
=======================
=======================
=======================
출처: http://ncanis.tistory.com/19
* 이글은 조엘온소프트웨에서 유니코드와 문자집합에 대한 고찰이 나오길래 좀더 분석해서 써봐야겠다는
생각이 들어서 작성하였습니다. ^^
프로그래밍을 하면서 제일 많이 겪는게 글자가 깨지는 거다.
2byte 문자를 쓰는 한글의 비애일까.
1. ASCII 코드
다음은 잘못된 것입니다.
"일반 텍스트는 ASCII 이며 8비트 문자열이다."
이건 영어권이나 가능하다. 무수히 많은 조합이 필요한 한글일경우 , 1byte로 문자를 표현하는 것은 불가능하다. 웃긴일이지 ㅡ.ㅡ; 개늠들.
다음은 1byte로 표현하는 ASCII 코드 표이다.
아주 영어만 쓰라고 이렇게 만들어 놨다. 보면 0~127, 글자는 32~127로 표현한다.
1byte는 -127~127 까지 총 2의 8승, 256개 이니 1byte로 된다. 물론 영어만.
2의 보수면 0~255까지, 총 7비트로 표현 가능하니 마지막 비트는 다른나라 사람들이 알아서 써라
이얘긴가보다. 이 영어 문자를 제외하고 나머지 128~255를 맵핑하면서 문제는 시작된다.
| 10진수 | 16진수 | 문자 | 의미 | 10진수 | 16진수 | 문자 |
| 0 | 0×00 | NULL | 64 | 0×40 | @ | |
| 1 | 0×01 | SOH | start of heading | 65 | 0×41 | A |
| 2 | 0×02 | STX | start of text | 66 | 0×42 | B |
| 3 | 0×03 | ETX | end of text | 67 | 0×43 | C |
| 4 | 0×04 | EOT | end of transmission | 68 | 0×44 | D |
| 5 | 0×05 | ENQ | enquiry | 69 | 0×45 | E |
| 6 | 0×06 | ACK | acknowledge | 70 | 0×46 | F |
| 7 | 0×07 | BEL | bell | 71 | 0×47 | G |
| 8 | 0×08 | BS | backspace | 72 | 0×48 | H |
| 9 | 0×09 | HT | horizontal tab | 73 | 0×49 | I |
| 10 | 0×0A | LF | NL line feed, new line | 74 | 0×4A | J |
| 11 | 0×0B | VT | vertical tab | 75 | 0×4B | K |
| 12 | 0×0C | FF | NP form feed, new page | 76 | 0×4C | L |
| 13 | 0×0D | CR | carriage return | 77 | 0×4D | M |
| 14 | 0×0E | SO | shift out | 78 | 0×4E | N |
| 15 | 0×0F | SI | shift in | 79 | 0×4F | O |
| 16 | 0×10 | DLE | data link escape | 80 | 0×50 | P |
| 17 | 0×11 | DC1 | device control 1 | 81 | 0×51 | Q |
| 18 | 0×12 | DC2 | device control 2 | 82 | 0×52 | R |
| 19 | 0×13 | DC3 | device control 3 | 83 | 0×53 | S |
| 20 | 0×14 | DC4 | device control 4 | 84 | 0×54 | T |
| 21 | 0×15 | NAK | negative acknowledge | 85 | 0×55 | U |
| 22 | 0×16 | SYN | synchronous idle | 86 | 0×56 | V |
| 23 | 0×17 | ETB | end of trans. block | 87 | 0×57 | W |
| 24 | 0×18 | CAN | cancel | 88 | 0×58 | X |
| 25 | 0×19 | EM | end of medium | 89 | 0×59 | Y |
| 26 | 0×1A | SUB | substitute | 90 | 0×5A | Z |
| 27 | 0×1B | ESC | escape | 91 | 0×5B | [ |
| 28 | 0×1C | FS | file separator | 92 | 0×5C | |
| 29 | 0×1D | GS | group separator | 93 | 0×5D | ] |
| 30 | 0×1E | RS | record separator | 94 | 0×5E | ^ |
| 31 | 0×1F | US | unit separator | 95 | 0×5F | _ |
| 32 | 0×20 | SP | SPACE | 96 | 0×60 | . |
| 33 | 0×21 | ! | 97 | 0×61 | a | |
| 34 | 0×22 | " | 98 | 0×62 | b | |
| 35 | 0×23 | # | 99 | 0×63 | c | |
| 36 | 0×24 | $ | 100 | 0×64 | d | |
| 37 | 0×25 | % | 101 | 0×65 | e | |
| 38 | 0×26 | & | 102 | 0×66 | f | |
| 39 | 0×27 | ' | 103 | 0×67 | g | |
| 40 | 0×28 | ( | 104 | 0×68 | h | |
| 41 | 0×29 | ) | 105 | 0×69 | i | |
| 42 | 0×2A | * | 106 | 0×6A | j | |
| 43 | 0×2B | + | 107 | 0×6B | k | |
| 44 | 0×2C | ' | 108 | 0×6C | l | |
| 45 | 0×2D | - | 109 | 0×6D | m | |
| 46 | 0×2E | . | 110 | 0×6E | n | |
| 47 | 0×2F | / | 111 | 0×6F | o | |
| 48 | 0×30 | 0 | 112 | 0×70 | p | |
| 49 | 0×31 | 1 | 113 | 0×71 | q | |
| 50 | 0×32 | 2 | 114 | 0×72 | r | |
| 51 | 0×33 | 3 | 115 | 0×73 | s | |
| 52 | 0×34 | 4 | 116 | 0×74 | t | |
| 53 | 0×35 | 5 | 117 | 0×75 | u | |
| 54 | 0×36 | 6 | 118 | 0×76 | v | |
| 55 | 0×37 | 7 | 119 | 0×77 | w | |
| 56 | 0×38 | 8 | 120 | 0×78 | x | |
| 57 | 0×39 | 9 | 121 | 0×79 | y | |
| 58 | 0×3A | : | 122 | 0×7A | z | |
| 59 | 0×3B | ; | 123 | 0×7B | { | |
| 60 | 0×3C | < | 124 | 0×7C | | | |
| 61 | 0×3D | = | 125 | 0×7D | } | |
| 62 | 0×3E | > | 126 | 0×7E | ~ | |
| 63 | 0×3F | ? | 127 | 0×7F | DEL |
예를들어서, 미국에서의 pc는 128~255 bit값에 대한 맵핑과 이스라엘의 pc의 맵핑이 틀리면
메일을 보내면 resume => ?????? 같이 보여지게 될 것이다.
즉, 서로 제각각으로 이 1bit를 사용했다는 것임.
이런문제점을 통합해서 표준화 한것이 ANSI 이다. 128~256을 어떻게 사용할껀지에 대한 규약이다.
즉 이스라엘은 ANSI-862를 쓰고, 우리나라는 ANSI-949, 영어는 ANSI-437을 쓴다.
즉 코드페이지란 개념으로
코드페이지 949번은 128~255를 한글로 맵핑했다. 한글을 사용하는 사람들은 949로 맵핑해서 써라
이뜻이다.
윈도우에서는 chcp로 코드페이지를 변경할수 있단다.
chcp를 치니깐 949를 쓴다고 나온다.
===========
2. 유니코드
자아 다음은 아시아다.
아시아권의 글자(한글,일본어,중국어)는 1byte로는 택도 없다는것을 알죠?
그래서 나온게 DBCS 라네요
Dobule Bytes Character Set 즉 나머지 모자라는 문자는 두번째 byte에 저장해라 이얘기다. 욕나온다.
이제 유니코드다. 유니코드가 나옴으로써 위의 문제들이 모두 해결된 것이다. 물론 불만은 많다 ㅡ.ㅡ;
유니코드가 하나의 "문자"를 무조건 2bytes 표현한다고 생각은 오류다. 2bytes 면 2의 16이니 65536까지 표현 가능하네. 자바에서는 하나의 문자(char)를 4byte로 표시한다, 아 C++은 2byte로 처리한다.
유니코드에서 글자는 코드 포인트라는 단순히 이론적인 개념으로 사상한다.
즉 A가 0100 0001 1byte로 이렇게 표현되지만,
만약 폰트가 달라지면 어떻게 할까
A 와 a 와 이상한 a 등등 A를 의미하는 것은 같지만, 모두 다르다.
즉 관념적인 A 다.
즉 폰트가 달라져도, 유니코드 페이지 값은 동일하다.
윈도우에서 실행>charmap 을 치면 이게 나온다. 오오~


보면 H 를 선택했는데 문자코드가 0x48 이라고 나온다. 만약 폰트를 다른걸 선택해도 관념적인 H는 0x48 동일하다. 이런 관념적인 문자 코드 번호를 코드포인트라고 한다.
U+0048 이게 정확한 "H" 의 코드 포인트 인다.
이렇게 관념적으로 문자를 지정하니 폰트가 달라져도 모양만 바뀌게 되는것이다.
생각해보라. 우리가 사용하는 한글폰트들 얼마나 많은가. 그걸 몽땅 몇바이트에 넣어 사용한다면 ?
끔찍하다.
즉 H를 다른 폰트로 바꾸어도 코드포인트는 U+0048 동일하다.
여기서 문제가 있다. 이런 코드 포인트를 저장해야한다.
0048 이니 2byte에 저장하는 것이다.
즉 00(1byte), 48(1byte)
여기서 리틀 엔디안과 빅 엔디안의 개념이 나온다. 각 컴퓨터에서 좀더 빨리 돌리기 위해 이 순서를 바꾼것이다. 네떡하시는분들 아시죠?
* 리틀 엔디안과 빅 엔디안은 조나단 스위프트의 걸리버 여행기에 나오는 이야기로 삶은 달걀을 둥근쪽을 깨서 먹는 사람 Big Endian 과 뾰족한 쪽을 깨서 먹는 사람들 Little Endian 로 나누어 정치적 대립을 벌이는 소인국 이야기에서 유래 되었다.
즉 00 48 대신에 48 00 으로 쓰는 것이다. (리틀엔디안, 빅 엔디안)
그럼 이렇게 되면 무엇이 필요할까, 이 문자가 과연 리틀인지 빅인지 알아야 할꺼 아닌가
그래서 문자열 맨앞에 유니코드 바이트 순서표시를 붙였다. 그래야 서로 호환해서 바꾸던지 말던지 할꺼다.
3. UTF - 8
자아 여기서 문제다. 미국국적 즉 영어권 프로그래머들은 머가 불만일까
그들은 영어라(ㅡ.ㅡ;) 1byte면 표현 가능하다. 근데 매 문자 마다 2byte로 표현해야 하니 불만인거다. 저장공간 낭비라면서.. 아놔~
그래서 나온게 UTF-8 이다. UTF-8 은 0~127 사이에 존재하는 모든 코드 포인트들을 단일 바이트로 저장한다. 128이상인것은 2byte 째, 3byte째로 해서 최대 6byte 까지 확장해서 저장한단다. 이러면 기존 ASCII와 똑같이 맞아 떨어지니 굳이 바꿀필요 없다는 거다.
4. 인코딩
항상 이게 문제다. 왜 한글로 메일을 보냈는데, 받는쪽에서 깨져보일까.
=> 이건 보낼때 이 문자열이 어떤 인코딩방식인지 안알려줘서 그렇다.
(UTF-8, ASCII, ISO 8859-1(라틴), 윈도우1252(유럽) 도대체 어느것?)
이메일인경우 헤더에 "Content-Type: text/plain; charset="UTF-8" 같이 적어주면 된다.
HTML도 마찬가지다.
(근데 우낀게 태그선언을 안해도 한글로 보인다. 왜냐면, 윈도우가 자주쓰는 빈도를 파악해서 인코딩 해준단다.)
* 모든 문자를 표기하려면 UTF-8 을 써라. euc-kr로 표현 불가능한 문자 많다.
* euc-kr이나 ksc5601는 서로 같은 의미이다.
=======================
=======================
=======================
'프로그래밍 관련' 카테고리의 다른 글
| 자바 알림창, 다이얼로그창, alert() 창에 주소줄 보이지 않게 하기 관련 (ios, android 등등에도 적용) (0) | 2020.09.22 |
|---|---|
| 데브피아에 어느 3D 개발 관련 질답을 좋은 게시물^^ (0) | 2020.09.21 |
| 온라인 게임의 설치 및 실행을 ActiveX를 이용하지 않는 방법은 없을까요? (1) | 2020.09.21 |
| 이클립스, 플래시빌더 메모리 문제 GC overhead limit exceeded, unable to execute dex java heap space 빌드에러 해결 (0) | 2020.09.20 |
| 코드, 소스 정리 사이트 관련 (0) | 2020.09.15 |





댓글 영역