=======================
=======================
=======================

출처: http://asdf18.tistory.com/3
winapi.co.kr(현 http://www.soen.kr/)의 강좌를 보다보면 코드에 자주 오류가 뜨곤 한다.
그 이유는 강좌 제작 당시 사용되었던 Visual Studio 6.0은 유니코드는 지원하지 않고, 멀티바이트만 지원하였고 Visual Studio 2005 이후로는 기본적으로 UNICODE를 지원하기때문인데 윈도우 2000 이상에서는 유니코드를 지원하고, 윈도우98은 유니코드를 지원하지 않았기때문이다.
멀티바이트는 한 문자에 할당되는 공간이 일정하지 않은데 영어는 1바이트, 다국어 2바이트 공간을 확보하고 유니코드는 항상 문자 하나에 2바이트 공간을 확보한다.
문자집합 부분 설정을 멀티바이트로 바꿔주게되면 오류는 발생하지는 않지만,
유니코드로 프로그래밍을 하게되면 외국어 윈도우에서도 한글이 깨지지 않고, 다국어 버전이 많들기 쉽다는 장점들이 있어서 유니코드로 프로그래밍 하는 것이 좋다고들 한다.
그래도 호환성을 위해 환경에 맞게 유니코드, 멀티바이트 변환되는 TCHAR타입을 사용하는 것이 좋다.
문자열같은경우에도 멀티바이트에서는 char str = "문자열"; 이렇게 입력했다면 유니코드에서는 wchar_t = L"문자열"; 이런 형식으로 입력해줘야 한다. TCHAR str = TEXT("문자열"); 이렇게 입력하면 컴파일 환경에 따라 바뀌게 된다.
함수들 같은경우에는 다음과같다. TCHAR타입을 사용하기 위해서는 #include<tchar.h>를 입력해줘야한다.
| 멀티바이트(MBCS) | 유니코드(WBCS) | TCHAR타입 |
| strlen | wcslen | _tcslen |
| strcpy | wcscpy | _tcscpy |
| strncpy | wcsncpy | _tcsncpy |
| strcat | wcscat | _tcscat |
| strncat | wcsncat | _tcsncat |
| strcmp | wcscmp | _tcscmp |
| strncmp | wcsncmp | _tcsncmp |
| printf | wprintf | _tprintf |
| scanf | wscanf | _tscanf |
출처: http://asdf18.tistory.com/3 [asdf18]
=======================
=======================
=======================
출처: http://sanaigon.tistory.com/47
오늘 울 회사 과장님께서 나에게 VC++ 에서 프로젝트 기본값 -> 문자 집합을 멀티바이트로 하는지 물어보셨다.
난 당연히 멀티바이트로 쓴다고 말씀드렸다.
그리고 왜 물어보시냐고 여쭤보니깐 문자 집합을 멀티 바이트로 해놓으면 나중에 ANSI -> 유니코드, 유니코드 -> ANSI로 변환할 때 문제가 없기 때문이라고 말씀하셨다.
과장님께서 클라이언트에서 다국어 처리를 할 때 입력은 ANSI로 받고, ANSI로 받은 것을 내부에서 유니코드로 변경하고, 이것을 출력할 때나 서버로 전송할 때는 다시 ANSI로 변경한다고 하셨다.
왜 그렇게 하냐고 여쭤보니.. ANSI로 다국어 문자를 받으면 처리하기가 애매한 경우가 많은데 이것을 유니코드로 변경해서 필터링이나 짤라주기 등을 해주고, 이것을 다시 ANSI로 변경하면 괜찮다는 것이다.
음.. 듣고보니 그런거 같다.
ANSI로는 다국어 처리를 하기란 상당히 까다로울 거 같은데.. 어떤 나라는 글자 하나가 1BYTE고, 어떤 나라는 글자 하나가 2, 3, 4, 5, 6 이렇게 다양한데 이런걸 다 ANSI로 1BYTE씩 파씽해서 처리하기가 상당히 까다로운거 같다. 유니코드로 변경하면 글자가 몇 바이트인지 신경 쓸 필요가 없으니깐 좋은거 같다.
퍼옴 : http://blog.daum.net/ohkuetai/5993663
비슷한듯하면서 헷갈릴수 있는데..
유니코드는 분명 모든 문자에 대해 동일한 코드체계로 가져간다는 것이다.
멀티바이트는 일반적으로 안시코드(1바이트 문자셋)로 표기되지 않는 문자셋을 표기하기 위해 2개이상의 바이트를 사용한거를 말하는 것이다. .. 그래서 1바이트문자와 2바이트문자가 같이 등장하게 된다.
VISUAL C++같은데서는 _MBCS, _UNICODE 정의와 T-매크로로 두가지 버전에 대해 코드레벨에서 호환되도록 작성할 수 있게 해준다.
그렇지만! 분명 멀티바이트/유니코드는 그 차이를 분명히 알고 써야 한다!!!
최근엔 유니코드로만 해서 _MBCS 처리를 별로 할일이 없긴 하지만, 그래도 멀티바이트 처리를 할땐 그 차이를 알고 조심해야 된다는 것을 강조하고 싶다.
암생각없이 strlen("한글abc") 이라고 하는데.. 이게, _mbstrlen("한글abc")하고, _wcslen(L"한글abc") 하고..3가지 버전이 어떤 값을 뱉어낼지 알아야 한다는 것이다.
assert(strlen("한글abc") == 7); // 7 bytes
assert(_mbstrlen("한글abc") == 5); // 7 bytes
assert(_wcslen(L"한글abc") == 5); // 10 bytes
그나마 _tcslen 이 있긴하지만, 내가 지금 필요한게 byte인지, 글자개수 인지를 정확히 알아야지 제대로 쓸수 있다. (안그럼?? 뻑나겠지. ^^)
..
이제 멀티바이트 사용할 때 유용한 함수들(그래서 여기저기 잘/많이 사용하게 되는)을 보면..
int _ismbbtrail( unsigned int c );
int _ismbblead( unsigned int c );
같은게 있다.. 텍스트편집기를 직접 만드는데, 안시빌드를 한다! 그러면 위의 두 함수 없이 어떻게 backspace/delete 키를 처리할까~ ^^
퍼옴 : http://blog.naver.com/jooyunghan?Redirect=Log&logNo=100004007609
VS 2005 부터는 프로젝트 생성시 기본적으로 유니코드 문자집합을 선택하게 되어 있습니다.
처음엔 속성에서 일일이 멀티 바이트 문자집합으로 바꿔주기도 했지만 곧 그것도
귀찮더군요. 그래서 현재는 그냥 유니코드에 맞는 코딩을 하고 있습니다.
윈도우 프로그래밍에선 유니코드나 멀티바이트나 별 차이는 없습니다.
단지 문자나 문자열 앞에 L 또는 TEXT() 매크로를 사용해주는 것만으로도 충분합니다.
그 외엔 운영체제에서 자체 지원하는
lstrcpy(strcpy)
lstrcmp(strcmp)
lstrcat(strcat)
lstrlen(strlen)
정도만 기억하시면 충분합니다.
제 경우는 문자열엔 TEXT()를 문자엔 L을 붙여서 코딩하고 있습니다.
둘의 차이는 거의 없기에 어떻게 사용하든 본인의 자유겠죠.
(int 를 제외한 변수를 선언할때도 주의해주셔야 합니다만...
주의할 거래봐야 char 를 TCHAR로 선언해주는 것 정도죠)
하지만 콘솔 프로그래밍으로 넘어가면 이건 그렇게 만만치가 않습니다.
VS 2005 이전에 유니코드를 지원하던 앞에 w가 붙는 함수가
2005로 넘어오면서 w..._s 형으로 다시 바뀐 겁니다.
_s 형으로 바뀐 건 좋은데 가끔은 받아들이는 인수의 수조차 바뀐 것들이
있어서 사람을 미치게 합니다.
예를 들면
wstrcat_s
예전엔 2개의 인수만을 받던 strcat 함수가 3개의 인수를 받도록 바껴버린거죠.
물론 여전히 2개의 인수를 받고 유니코드를 지원하는 lstrcat을 사용하면 그만이죠
하지만 어딘가 제가 모르는 저런 식의 함수가 분명 있을 겁니다.
(콘솔 프로그램의 의미가 거의 바닥을 치는데 이런 예기는 사실 별 의미가 없죠.)
그래도 혹시나 콘솔 프로그램을 작성하시다가 유니코드를 지원하는 함수를
알 필요가 있을 땐 MSDN을 이용해 보십시오. 영어를 몰라도
대충보면 어떤 함수를 사용해야 하는지 찾으실 수 있으실 겁니다.
서론은 여기까지 하고 이 글을 적는 본론으로 들어가죠
제가 콘솔 프로그램을 하나 만들었습니다. 물론, 유니코드를 사용했죠.
그런데 막상 실행해보니 도스창에 한글이 찍히지 않는 겁니다.
에러 경고 하나도 뜨지 않는데 한글을 안 찍히니 미칠 지경이더군요.
미친듯이 찾아 본 결과 답을 찾았습니다. 물론, 어째서 그런지는 모릅니다.
전혀요;
_wsetlocale(LC_ALL,TEXT("Korean"));
이걸 적어줘야 하더군요. 함수 이름만으로는 지역변경 - 한국 쯤 되는군요;
위 함수의 정의는 locale.h 안에 들어 있습니다.
위 함수를 적어주고 컴파일 하니 한글 출력이 되더군요.
(망할 유니코드...)
그 외에 이런 경우도 있습니다. 멀티바이트 유니코드 안 따지는 함수들이
가끔 있습니다. 그 형태 그대로 유지해서 어느 쪽에나 적응가능하죠.
그런데 가끔 이 함수들이 인수로 받아들이는 데이타형이 유니코드에 맞지 않을때가 있습니다.
예를 들면 소켓 프로그래밍의 send,recv 함수 같은 게 있죠
send,recv 함수는 두번째 인수로 (const char*) 형을 받습니다.
이 경우
TCHAR a[10];
send(socket,(char*)a,......);
//에러
send(socket,(char FAR*)a,......);
//성공
이런 식으로 적어주어야 합니다. recv 역시 마찬가지로 char FAR*
형으로 캐스팅해주면 유니코드 문자열을 넘겨줄 수 있습니다.
지금까지 제가 유니코드를 사용해 코딩하면서 겪은 문제점은 이걸로 대충 다 적었습니다.
아... 마지막으로 강조해야 할 부분 유니코드는 한 문자가 1바이트가 아니라 2바이트란 거죠.
(멀티바이트는 1바이트 문자셋과 2바이트 문자셋이 섞여 있죠)
유니코드에선 심지어 영어도 2바이트를 차지합니다.
크게 중요해 보이지 않는 거 같지만 이걸 깜박하면 자신도 모르게 에러를
내 버릴 수가 있습니다. (특히 메모리 활당 부분)
그럼, 별 의미 없는 글이나마 읽어주셔서 감사합니다.
p.s : wprintf 함수의 경우 유니코드 문자열을 출력할때는 %s 가 아니라 %S를 써야 합니다
안 그럼 알 수 없는 외계어가 출력되죠.
퍼옴 : http://cafe.naver.com/teacheryun.cafe?iframe_url=/ArticleRead.nhn%3Farticleid=289
[출처] 멀티바이트 유니코드|작성자 seaboy41
출처: http://sanaigon.tistory.com/47 [Double Dragon]
=======================
=======================
=======================
출처: http://klkl0.tistory.com/87
일반적으로 우리는 책에서 본거 그대로~ 잘 코딩했는데 문자관련해서 에러가 발생한다면 프로젝트 - 속성 - 구성속성 - 일반 - 문자집합에서 유니코드 또는 멀티바이트를 수정하면 해결된다.
그렇다면~ 이 유니코드와 멀티바이트란 뭘까?
멀티바이트를 이해하기 위해선 아스키 코드에 대해서도 알아야한다.
컴퓨터는 문자를 인식하지못함(0, 1만 인식) 그래서 개발자가 숫자와 문자를 매치시켜둠. 예를 들면 숫자가 73이면 16진수로는 0x4C고 문자는 L 이 된다. 이 모든걸 결정한 나라는 미국~ 즉 미국에서 ASCII CODE(American Standard Code for Information Interchange)를 만들어 사용했다. 이 아스키코드는 1byte, 즉 8bit로 이루어져(0~127까지 128개의 글자를 표현가능)
자, 이제 ASCII CODE란 걸 왠만큼 알았으니 멀티바이트로 넘어가 보자. 그럼 멀티 바이트란 무엇인가?
바로 이 ASCII CODE는 잘 해봐야 1Byte 인데 왜 싱글 바이트가 아닌 멀티 바이트인가?
즉슨, 위 에서 언급했던대로 Signed 1byte안에는 only english다. 뭐, 숫자나 뭐그런거 말고 다른 나라의 언어는 없다는 이야기이다. 그리고 unsigned는 그외 프랑스, 스페인, 따깔, 더치어등 잉글리시와 비슷한 언어들만 확장형으로 넣어두고 나머지는 표그리기나 그림그리용으로 채워 넣었다.
그럼 이제 비주얼스튜디오에서 멀티바이트로 하고 hello world 코딩을 해보자. 아, 영어말고 printf("헬로 월드"); 요롷게 당당하게 한국어로 해보자. 출력은 어떻게 나오는가? 한국어로 나오지 않는가?! 와우. 분명 ASCII CODE에는 영어 밖에 없다. 미국 표준이므로. 하지만 어떻게 한글이 나오지? 물론 개중에는 한글이 지원하지 않아 이상한 상형문자들이 나오는 경우가 있다. 그 이유는 나중에 점차점차 알아가도록 하고. 어찌되었든 한국어가 나온다. 그 이유가 멀티바이트에 있다. 이 문자를 인식할때 싱글바이트, 즉 1Byte로만 인식을 하면 영어만 인식을 한다. 왜냐? 1Byte안에 영어, 한국어, 중국어, 일본어 같은 것들을 모두 넣다보면 그 옛날 꼬물 컴퓨터를 쓸때 만들어진 표준으로써는 그당시 현실에 너무 안맞기 때문이다. 그렇게 몇년을 쓰다가 그걸 또 2Byte로 넘기기엔 표준이 송두리채 바뀌기가 쉽지 않았다. 따라서 하나의 대안을 제시한다.
1Byte를 두개 해서 문자를 표현하자고!!!
영어를 할땐 1Byte만 하면 되고 만약 영어이외의 한국어나 일어, 한자를 표현할때는 1Byte 여러개를 붙여 문자를 표현하기로 한다. 그 것이 ISO-2200(ISO-2200-KR, ISO-2200-JP, ISO-2200-CN) 에 정의 되어 있는 멀티바이트 문자열이다. 뭐 조금 자세히 들여다 본다면 그 1byte의 21-7E를 2개 이어붙여 94*94=8836개의 글자를 표현할수 있다. 좀더 자세히들어가 유닉스쪽 얘기를 한다면 유닉스에서는 그 표준이 약간다른데(EUC:Extended Unix Code로 EUC-KR, EUC-JP, EUC-CN으로 표기한다.) 두개의 바이트를 이어붙이는게 A1-FE 까지라는것을 제외하면 표현할수 있는 글자수도 같아 뭐 비슷비슷하게 사용할수 있다.
자, 이제 멀티바이트에 대해 약간이나마 감이 좀 잡히나? 간단히 말해 ASCII CODE 1Byte를 두개이상 붙여만들었기떄문에 멀티바이트라고 한다.
그렇다면 유니코드란 무엇인가?
ASCII는 영어일경우는 1Byte, 다른나라 언어는 +a를 하게된다. 그렇다면 어떤 일이 벌어지는가?
다른 나라 언어에 +a를 한다고 해도, 만약 한국어로 된 문장을 일본어로 해석하게 되면 어떻게 되겠는가? 이런 연유로 가끔씩 페이지를 돌아다닐때 홈페이지 전체가 상형문자로 덮혀있는 페이지를 발견하게 되는것이다. 즉, 글자가 깨진다고 하는것이다.
자, 이것을 위해 유니코드가 태어났다. 이 American놈들의 지저분한 Standard를 꺠고 Universial한 Code를 만들어 냈다. 그것이 바로 유니코드다. 이 유니코드는 두개를 이어 붙이는게 아니라 처음부터 2Byte를 할당하여 파일 하나에 컴퓨터로 표현하는 세상 모든 문자를 담았다. 하지만 아직은 인터넷계의 주류를 담고 있는 영어에 뭔가 불리하지 않겠는가? 쓰지도 않을 일본어때문에 굳이 용량을 키우면 뭔가 좀 거시기 하지 않겠는가?라는 생각이 들어 이 유니코드도 3가지로 나눠져 있다. 그거슨 UTF-8, UTF-16, UTF-32 로 나눈다.
UTF-8이 그 ASCII CODE와 같이 8비트만을 이용한 글자. UTF-16은 16비트를 사용하고 UTF-32는 32비트를 사용하여 글자를 나타낸다. 하지만 이것은 말했듯이 ASCII CODE처럼 두개의 1 Byte를 이어붙이는 것이 아니라 순수하게 1byte면 1byte, 2byte면 2 byte를 사용한다. 그래서 인터넷보면 UTF-8 인터넷 주소만 이용 뭐 이런게 있는데 즉, 한글주소나 뭐그런거 다 빼고 영어만 쓰겠음. 뭐 그런거다.
자, 이렇게 ASCII CODE와 UNICODE는 그 근본적으로 차이가 있다. 따라서 개발자는 죽어나간다. 표준이 여러개라...
블로깅이 너무 길어 졌으므로 다음 내용은 다음 포스팅에 계~~ 속. (아마도 실질적인 첫, Windows Programming에서 기본적인 Windows Frame의 UNICODE 의 Code가 되지 않을까 싶다.
자, 저번시간에 멀티바이트와 유니코드의 차이를 알았아보았다. 사실 엄격히 말하면 유니코드 조차 멀티바이트긴 하지만 일반적으로 ASCII CODE를 멀티바이트, 유니코드를 유니코드라 한다.
그렇다면 아까의 그 비주얼 스튜디오 2010에서 유니코드로 윈도우즈 프로그래밍을 할수 있는 두번째 방법을 소개 하겠다. 개념은 그리 어렵지 않다.
그저 멀티바이트 즉, ASCII CODE가 아닌 UNICODE를 사용하면된다.
하지만 방법은 막 어렵지는 않지만 간단하지만은 않다. 왜냐하면, 이 C++이 만들어 질땐 ASCII CODE를 전제로 만들어져 기본적인 명령어는 대부분 ASCII CODE를 기반으로 만들어 졌기때문에 그것을 요리해서 UNICODE도 사용할 수 있도록 변경해야 한다. 문자열이 들어가는 곳이라면 대부분의 코드를 손을 보아야한다. 따라서 ASCII CODE, 즉 일반적인 C에 적응되어 있는 분들은 문자열이 나온다면 긴장을 해야 할것이다.
물론, C++에서 막 문법을 떄고 오신분들이라면 우선 여기에 먼저 적응해지면 되긴 하겠지만 그래도 윈도우즈 프로그래밍에서는 char 가 직접적으로는 절대 안쓰인다고 생각해야한다.
자, 그럼 어떤걸 쓰느냐?
char는 TCHAR로 사용한다. TCHAR의 정의를 보면
#ifdef UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
만약, UNICODE를 사용한다면, wchar_t형의 TCHAR를 사용하고 유니코드가 아니면 그냥 char를 사용할께용. 이라는 뜻이다. 그렇다면 wchar_t는 무엇인가? 음... int는 정수형을 담기위한 자료 저장 범위를 지정하기 위한 "자료형"이다. 그렇다면 UNICODE를 위한 저장 크기를 제한한 자료형정도가 되겠다. 정확히 말하면 저거슨 unsigned short로 정의 되어있다.(for UTF-16)
사실 일반 멀티바이트라면 char를 사용하고 유니코드라면 wchar_t의 자료형을 사용하면 된다. 하지만 xp이후 유니코드가 대세가 되어가고 있고 마소또한 유니코드를 권장하고 있다.
또 몇개의 자료형을 더 찾아보자면
TCHAR : char
LPSTR : char *
LPCSTR : const char*
LPWSTR : wchar_t*
LPCWSTR : const wchar_t*
LPCTSTR : const wchar_t * || const char*
이렇게 있겠는데 음.. 헝가리언 명명법이라고는 알고 있을란지... 아무튼 이름 붙이는 방법이다. 그 이름 붙이는 방법중 약어를 쓰는경우가 있는데 STR은 딱봐도 string이라는거 알겠고 다른 약어들을 대충 찾아본다면
W : Wide char (2바이트를 의미. 대충 유니코드따라잡기용 ASCII Code라 생각하면 됨)
T : unicode || ASCII
C : constant
LP : long pointer
STR : string자료형
그리고 이 유니코드를 지원하는 문자열함수도 따로 있으니 아래의 함수들을 이용하면 된다.
strlen lstrlen
strcpy lstrcpy
strcat lstrcat
strcmp lstrcmp
sprintf wsprintf
음.. 이제 코드만 짜보면 되겠구나 :)
자, 그렇다면 코드는... 다음 이시간에 계속!! 으흐흐흐흐
=======================
=======================
=======================
출처 :
http://blog.naver.com/wondo21c/30043174174
Visual Studio 2005 프로젝트 속성 ->구성속성을 보면
문자 집합으로 2가지를 사용할 수 있다.
1. 멀티바이트 문자 집합
2. 유니코드 문자 집합
아스키코드는 모든 문자 하나가 1byte를 차지한다.
하지만, 아스키 문자 코드 만으로는 한글이나 일어 등의 다른 문자를 표시할 수 없다.
그래서 아스키 문자 코드에다가 다른 문자(2byte)들을 포함한 문자 집합이 멀티바이트 문자 집합이다.
정확히는 모르겠지만, 한 문자가 2byte를 넘는 문자도 존재할 것이다.
그래서 용어 자체가 멀티바이트 문자 집합이 아닐까 생각한다.
그런데 멀티바이트 문자 집합은 특정 문자 집합마다의 코드페이지가 존재한다.
예를 들어, 같은 코드 번호 일지라도 한글 코드 페이지로 해석하면 한글이 나오지만,
일어 코드 페이지로 해석하면 일어가 나온다.
그래서 이상하게 깨지는 문자 등을 우리는 목격할 수 있다.
이것의 방안으로 탄생한 것이 유니코드!
유니코드는 아스키 문자 코드 뿐만 아니라, 한글, 일어 등등 어떠한 문자들을 총 망라하여
각 한 문자에 2byte씩으로 할당하여 만든 문자 집합이다.
그리하여 각각의 특정 문자는 고유의 유니코드값을 가진다.
우리의 문제는 코딩 시에, 어떻게 해야 하는가!
너무나도 초보인 나는 아직 ANSI 표준 문자열을 쓰는데도 익숙치 않다.
하지만 메모리를 다루는 프로그래머로써 1bit의 메모리라두 잘못된 경우에는
프로그램 전체를 뻑(Crash)하는 우려를 범하곤 한다.
나같은 게임 프로그래머로서는 게임 실컷 만들어 놓고, 유저들에게 버그 많다고 욕들어 먹는다. ^^;;
게임뿐만 아니라 어떤 프로그램도 요새는 세계화가 아닌가!
그래서 한글과 영어만으로는 완벽하다고 안심해서는 안된다.
대만어, 프랑스어 등등 어떠한 문자 앞에서도 굴하지 않아야 된다.
그렇다고 우리가 각각의 나라별로 게임을 개별적으로 만들어 줄 수는 없지 않은가!
그래서 소스 상에서 유연성이 필요한 것 같다.
일단, 나는 자주 쓰는 몇 개의 습관부터 고치고자 노력해야 겠다.
| char | TCHAR |
| strcat_s() | _tcscat_s() |
| strcpy_s(), strncpy_s() | _tcscpy_s() , _tcsncpy_s() |
| strlen() | _tcslen |
| sprintf_s() | _stprintf_s |
그리고 문자열을 바로 쓸 때,
"" 대신에 TEXT("")을 쓰자.
TEXT 매크로는 유니코드의 설정에 따라 상수의 타입을 달리 한다.
예를 들어 유니코드로 컴파일 할 경우, TEST("a")를 16bit(2byte) 문자로 인식하고,
아닐 경우, 8bit(1byte) ANSI 문자로 인식한다.
밑의 표는 인터넷에서 구한 것.
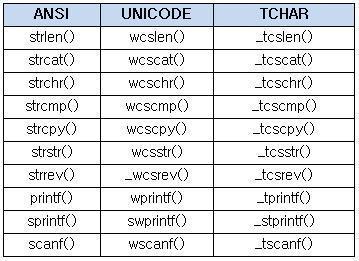
추가 :
char *, LPCSTR, TCHAR 차이
문자열을 처리하는 기본 자료형은 보통 char, wchar, TCHAR 를 사용한다.
char * 는 LPSTR 이며, (LP 는 Long Pointer)
const char * 는 LPCSTR 이다.
그럼 TCHAR 란?
한글을 포함한 다양한 나라의 독특한 언어 표현을 위해(영어제외) 최소 2바이트가 필요하다.
(영어는 1바이트)
MultiByte 를 사용하기도 하지만, 영어는 1바이트, 한글은 2바이트로 나눠지기 때문에
메모리 관리가 어려워 진다.
그래서 사용하는 것이 wchar 이다.
wchar 는 모든 문자를 2바이트로 구성한다.
(기존 자료형보다 메모리 2배 공간필요)
TCHAR 는 char 인지, wchar 인지 구별하지 않고 코딩 할 수 있게끔 해주기 위해 존재한다.
TCHAR 가 어떤건지에 대한 구별은 UNICODE 라는 precompile 상수를 이용해서 구분하며,
이는 project->settings 에 _DEBUG 등등이 선언되어 있는데 끝에 선언해 주면
TCHAR 는 wchar 로 변환해서 컴파일을 시도한다.
글로벌한 제품 개발을 위해서는 TCHAR 사용이 필수인듯 하다.
댓글1:
원래 영운은 1바이트잖아요.
그런데 한글이나 중국어 등 영문권이 아닌 제 3세계 문자를 표현하기 위해서는 2바이트가 필요하죠.
이를 위해서 멀티바이트를 사용하기도 하지만 멀티바이트는 어떤문자는 1바이트이고 어떤문자는 2바이트여서 메모리 관리가 어렵게 됩니다.
그래서 wchar 가 등장하는데 wchar 는 모든 문자(영문포함)가 2바이트로 구성이 되니까
당연히 wchar 는 일반 ascii 타입의 char 보다 메모리 공간이 2배 필요하게 되는거죠.
그럼 여기서 TCHAR 는?
그건 바로 acscii 타입의 일반 Char 또는 wchar 라는 의미예요.
TCHAR를 사용하면 char 인지 wchar 인지 구별하지 않고 그냥 코딩할수 있게 되죠.
댓글2:
한마디로 TCHAR 를 사용하고 컴파일러에 유니코드라고 알려주지 않으면 char로 동작하는거죠.
나중에 wchar로 사용하려면 컴파일러에 유니코드라고 해주면 소스코드는 손 안대도 되는거겠죠?
출처: http://klkl0.tistory.com/87 [살만한 세상 만들기]
=======================
=======================
=======================
Mfc를 사용할 때 afxMessageBox와 같은 함수를 사용할 때,
afxMessageBox(“안녕하세요”); 라고 한글이 포함된 경우 컴파일 에러가 발생하는 경우가 있습니다.
이럴 때 보통 유니코드 문자 집합을 멀티바이트 문자집합으로 변경해서 사용하는 것을 종종 볼 수 있습니다.

유니코드 문자 집합과 멀티 바이트 문자 집합의 차이
1. 처음 컴퓨터 문자 집합인 아스키(ASCII) 코드가 나왔을 때 영어 위주였기 때문에 한 글자당 1 바이트(8비트)로 글자를 표시하게 됩니다. 그런데 한글이나 일본어 등 다른 나라의 언어들은 1 바이트로는 표현할 수가 없게 되어 이러한 문제를 해결하기 위해 문자 코드 확장을 추진하게 되었습니다.
A. 그 결과 나오게 된 것이 현재의 유니코드 입니다.
한 글자당 2바이트씩 할당되게 통일되었습니다.
2. 멀티 바이트(Multi-Byte)는 말 그대로 문자에 따라서 바이트 수를 다르게 할당해 줍니다. 아스키 코드가 Single – Byte 문자 집합이고 한국어나 일본어 등에 대한 문자를 표현하기 위해서 만든 것이 Double – Byte 문자 집합입니다.
그리고 그 두 개를 합한 것이 바로 멀티 바이트 문자 집합 입니다.
ANSI(MBCS = Multi-Byte Character Set)라고 하더군요.
Single Byte 문자 집합+ Double Byte 문자 집합 = 멀티 바이트 문자 집합
영어는 1바이트, 한글은 2바이트로 다르게 할당을 해주는 방식입니다.
Visual studio 프로젝트에서는 유니코드가 기본값으로 설정되어있습니다.
그런데 유니코드를 사용했는데도 한글을 사용하면 컴파일 오류가 일어나는 경우가 있습니다.
1. 그 이유는 유니코드 정의에 따라 함수를 다르게 구분하고 있다고 합니다.
프로젝트 설정에서 유니코드 문자 집합을 설정해놓았는데 유니코드를 처리하는 함수를 사용할 때 ASCI(MBCS) 문자열을 사용하게 되면 컴파일 오류가 발생한다는 것입니다.
2. 그렇다면 반대로도 생각해 볼 수 있는 것입니다.
프로젝트의 문자 집합 설정은 프로젝트의 상황에 맞게 변경해야 하는데 매번 변경하기에는 번거롭게 되고 이 상황을 쉽게 해결해주기 위한 자료형을 설명하도록 하겠습니다.
TCHAR 자료형
TCHAR 자료형은 WinNT.h라는 헤더에 정의되어 있다고 합니다.
프로젝트의 문자 집합이 유니코드, 멀티 바이트 모두에서 사용이 가능하다고 합니다.
표현 할 때는 _T 매크로를 사용하고 _T( “문자” )처럼 사용하면 됩니다.
예시: afxMessageBox(_T(“안녕하세요”));
모든 문자열에는 _T 매크로를 사용하는 것이 좋을 듯 싶습니다.
출처: http://yeunhwa.tistory.com/entry/유니코드-멀티-바이트-문자-집합과-TCHAR-자료형 [Life Sytle of YeunHwa]
=======================
=======================
=======================
'프로그래밍 관련 > 언어들의 코딩들 C++ JAVA C# 등..' 카테고리의 다른 글
| c 그리고 자바 연동관련 dll 연동 관련 (0) | 2020.09.13 |
|---|---|
| 델파이 그리고C 혼합 dll 관련 이미 만들어진 델파이 DLL과 C++Builder와 Delphi 유닛을 혼합해서 쓸때 방법(보강) (0) | 2020.09.13 |
| C, C++ 멀티스레드에서 shared_ptr 사용시 주의사항 (0) | 2020.09.10 |
| C, C++ Thread, 스레드, 쓰레드 _beginthreadex(멀티스레드적합), _beginthread (0) | 2020.09.10 |
| C/C++ 파일I/O 파일 읽기 쓰기, 파일 입출력 관련 (0) | 2020.09.10 |





댓글 영역