
OpenGL을 쓰고 항시 API를 쓰고 다시 해제해주어야 하는 API들은 해제 해주는것을 잊지 마세요
예로들어 wglMakeCurrent(...)로 들자면
HDC hdc = getHDC();
HGLRC hglrc = getHGLRCRES_GL();
::wglMakeCurrent(hdc, hglrc); //사용
//-------------------------------------------
//{랜더링 코드들
..................................................................
//}
//---------------------------------------------
::wglMakeCurrent(NULL, NULL); //::wglMakeCurrent(hdc, NULL); //해제
위와같이 wglMakeCurrent(...) 랜더링 부분에 Api 사용과 해제 부분을 제대로 하지 않으면 다른
위치의 wglMakeCurrent(...) 를 사용시 문제가 생길수 있습니다.
출처: http://iskim3068.tistory.com/20
OpenGL에서 버퍼에 대해 이해하기 위해
정리해두어야 할 것 같아 정리해보았다.
버텍스 버퍼(Vertex Buffer Object)란?
버텍스란 정점을 이야기 한다. 쉽게 말해 정점의 정보를 저장해 두는 정점들의 집합 버퍼이다.
3D 공간상의 점을 이야기 한다. 이점은 x, y, z (즉 좌표) 이외에 다른 정보도 갖는다.
보통은 그래픽카드 비디오 메모리에 올린다. 이 점들에서 선을 연결하고 면을 만든후 텍스쳐를 입히고 모니터에 뿌려주는 것이다. 이것이 3D 카드가 하는 일이다.
이 버퍼는 어떻게 구성하는게 좋을까? 보통은 오브젝트 단위로 구성하는게 좋다. 예를 들면 하나의 그림은 하나의 버텍스 버퍼로 구현해도 되지만 독립되어있다면 나누는게 좋다. 또 카메라도 생각을 해야한다. 해당 오브젝트를 렌더링 할필요 없다면 해당 버텍스 버퍼를 렌더링 못하게 하면 된다. 카메라에 안보인다는것이 확실하다면 그런 방법도 있다.
하지만 Lock을 실행할때는 대단히 주의 해야한다. cpu가 이 작업에 할당되고 다른 일을 못하게 된다.
Vertex Buffer에 lock을 건다라고 하는 것은 Lock함수 호출을 통해서 리턴되는 포인터를 통해서 버텍스 버퍼의 메모리로의 직접적인 접근을 얻는 것이다. 중요한 점은 이때 리턴되는 포인터는 Lock이 걸려있는 동안에 한해서만 유효하다는 것이다.
DirectX의 모든 surface들에서 그러하듯, 마찬가지로 Vertex Buffer에 대한 Lock 역시 아주 느린 process에 해당한다. 따라서 Lock을 사용할 때엔 매우 신중해야 한다.

기본 VBO functions
다음 함수는 VBO 액세스 및 조작의 핵심을 형성한다.
In OpenGL 1.4:GenBuffersARB(sizei n, uint *buffers)Generates a new VBO and returns its ID number as an unsigned integer. Id 0 is reserved.(새로운 VBO를 생성하고, 부호없는 정수로 그 ID 번호를 반환한다. ID 0은 예약되어 있다.) BindBufferARB(enum target, uint buffer)Use a previously created buffer as the active VBO. (활성 VBO로 이전에 생성 된 버퍼를 사용한다.) BufferDataARB(enum target, sizeiptrARB size, const void *data, enum usage)Upload data to the active VBO. (활성 VBO에 데이터를 업로드 할 수 있다.) DeleteBuffersARB(sizei n, const uint *buffers)Deletes the specified number of VBOs from the supplied array or VBO id. (제공된 배열 또는 VBO ID 번호를 반환합니다. ID 0은 예약되어 있다.) In OpenGL 2.1,[3] OpenGL 3.x[4] and OpenGL 4.x:[5] GenBuffers(sizei n, uint *buffers)Generates a new VBO and returns its ID number as an unsigned integer. Id 0 is reserved. (새로운 VBO를 생성하고, 부호없는 정수로 그 ID 번호를 반환합니다. ID 0은 예약되어 있습니다.) BindBuffer(enum target, uint buffer)Use a previously created buffer as the active VBO. (활성 VBO로 이전에 생성 된 버퍼를 사용합니다.) BufferData(enum target, sizeiptrARB size, const void *data, enum usage)Upload data to the active VBO. (활성 VBO에 데이터를 업로드 할 수 있습니다.) DeleteBuffers(sizei n, const uint *buffers)Deletes the specified number of VBOs from the supplied array or VBO id. (제공된 배열 또는 VBO ID와 VBOs의 지정된 번호를 삭제합니다.
출처: http://iskim3068.tistory.com/20 [LausdeoF]
출처: http://maytrees.tistory.com/116
일반적으로 OpenGL에서 원하는 오브젝트의 렌더링을 위해 사용하는
glBegin(GL_xxx);
-
glEnd();
방식은 그리고 싶은 객체가 많아지면 느려져서 프레임이 뚝뚝 끊기는 현상이 나타난다.
(꽤 좋은 컴퓨터에서 대략 100만개의 triangle을 그리면 초당 10fps 정도 나온다. 일반적으로 30fps 이상은 나와야 끊기지 않는다고 느낀다.)
위 방식이 느린 이유는 매 함수가 실행 될때마다 메모리를 할당하고 해지하는 작업으로 인해 오버헤드가 크기 때문이다.
이를 해결하기 위한 방법으로 glDrawElements() 함수가 있다.
이 함수는 렌더링할 데이터를 미리 메모리 상에 쭉 정렬시켜 놓고 차례대로 데이터에 접근하여 렌더링하는 방식이기 때문에
glBegin(), glEnd() 를 이용하는 방법에서 100만개의 triangle을 렌더링하기 위해 300만번의 glVertex3d() 을 호출한다고 했을 때
glDrawElements()는 이 함수 하나만으로 렌더링을 할 수 있다.
glEnableClientState(GL_VERTEX_ARRAY); // 필수
glEnableClientState(GL_NORMAL_ARRAY); // 선택사항
glEnableClientState(GL_COLOR_ARRAY); // 선택사항
// glEnableClientState() 에 맞춰서
glVertexPointer(3, GL_DOUBLE, 0, _vp); // 각 인자별로 (dimension, 데이터 타입, 각 데이터간의 offset byte, vertex 데이터 포인터)
glNormalPointer(GL_DOUBLE, 0, _np); // glVertexPointer와 비슷. dimension만 빠짐
glColorPointer(3, GL_UNSIGNED_BYTE, 0, _cp); // glVertexPointer와 같음. 가능한 데이터 타입이 다름.
glDrawElements(GL_TRIANGLES, indices.size(), GL_UNSIGNED_INT, &indices[0]);
// 각 인자별로 (오브젝트 타입, index 개수, index 타입, index 포인터)
// glEnableClientState() 에 맞춰서
glDisableClientState(GL_VERTEX_ARRAY);
glDisableClientState(GL_NORMAL_ARRAY);
glDisableClientState(GL_COLOR_ARRAY);
index는 미리 만들어 둬야한다.
index의 구조는 예를들어 triangle을 vertex 데이터로부터 vertex 순서 {3, 4, 7, 6, 2, 1, 8, 9, 5} 대로 그린다고 치면
unsigned int indices[9] = {3, 4, 7, 6, 2, 1, 8, 9, 5};
와 같이 만들면 된다.
index 타입을 다르게 하려면 다른 타입으로 만들어도 상관없다.
pointer 뿐만이 아니라 std::vector<>로 만들어도 되고 기타 등등 데이터 타입만 맞으면 무엇이든 괜찮다.
VBO는 Vertex Buffer Object 의 약자로 그래픽카드의 메모리를 이용하는 방식이다.
일반적인 방법을 이용해 렌더링 할 때는 매 프레임마다 CPU가 RAM으로부터 데이터를 읽어 그래픽카드의 메모리로 전송하고 이것을 그래픽 카드에서 그린다.
VBO는 미리 데이터를 그래픽카드의 메모리에 옮겨놓고 GPU가 바로바로 그래픽카드의 메모리로부터 데이터를 읽어 렌더링 할 수 있게 하는 방식이다.
이렇게 하는 경우 RAM -> 그래픽카드 메모리로의 전송시간이 사라지고, GPU가 그래픽카드 메모리를 읽는데 드는 시간은 매우 짧기 때문에 수 나노초 수준의 렌더링 속도를 볼 수 있다.
단점으로는 데이터가 변경될 때 새로 RAM -> 그래픽카드 메모리로의 전송 시간인데, 아직 공부해보지 못했지만 그래픽카드 메모리 상에 접근해서 데이터를 변경하는 방법도 있다고 하니 이는 충분히 해결 가능한 문제인 것 같다.
VBO에 대한 설명은 복잡해서 소스코드를 첨부한다.


'readme_vbo.txt' 파일을 참조해서 필요한 라이브러리를 설치하고 설명에 따라 소스코드를 함께 보며 적용해보면 된다.
InitGLCustom() 은 InitGL() 함수에 추가하는 부분이라고 보면 되고 RegisterMesh()가 RAM -> 그래픽카드 메모리 부분이다.
(궁금하신 점 있으면 댓글로 달아주세요. 자세히 답변해드립니다~)
출처: http://maytrees.tistory.com/116 [오월나무이야기]
- VBO
- VBO를 쉽게 이해하기 위해서는 OpenGL ES가 Client-Server model로 되어있다는 걸 알아야 한다.
- 정확히 구분하면 복잡하기 때문에 간단히 처리 위치를 기준으로 정리하면 Client는 App, Driver까지 CPU에서 처리되는 부분을 말하고 Server는 GPU라고 생각하면 된다.
- VBO를 사용하지 않은 경우
- Vertex info를 client (client memory)에 저장하고 매 frame 마다 vertex info를 client에서 server (GPU memory)로 전송한다.
- VBO를 사용하는 경우
- Vertex info를 server (GPU memory)에 올려놓고 사용한다.
- 즉, position, texture coordinate, color, normal과 같은 vertex info.를 GPU에 저장한다는 것이다.
- VBO를 사용하지 않은 경우

- 위와 같이 기존 방식대로 처리시, position, texture coordinate, normal data는 client (client memroy)에 저장되고 매 프레임마다 data를 client에서 server로 전송하게 된다.
- VBO를 사용하는 경우
- 사용법
- Buffer 생성
- Vertex info를 Server에 저장
- Buffer binding
- Rendering
- 초기화 (1, 2번)
- 1번만 수행
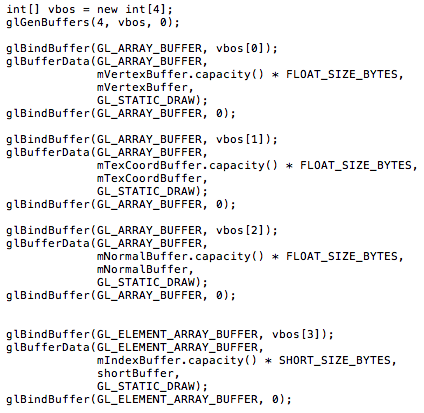
- glBindBuffer(...)를 통해서 vertex info를 server로 전송
- size
- 전송하고자 하는
data의 byte size - usage
- Application에서 data를 어떻게 사용할지를 나타내는 hint
- 두 종류의 buffer object가 지원
- Array buffer object
- GL_ARRAY_BUFFER
- Vertex data 전송시 사용
- position, texture coordinate, normal, color
- Element array buffer object
- GL_ELEMENT_ARRAY_BUFFER
- Index 전송시 사용용
- 렌더링 (3. 4번)
- 매 frame 수행
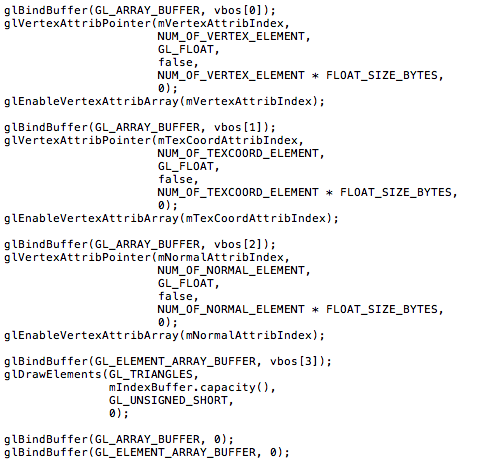
- glVertexAttribPointer(...)의 마지막 인자에 vertex data를 넘기는 것이 아닌 byte offset을 넘긴다.
- 매 frame 마다 vertex data를 전송하지 않고 server에 저장된 vertex data를 읽어들일 byte offset만 지정한다.
- 위에서 언급한 것과 같이 vertex info를 Server (GPU)에 저장하기 때문에 최초에 한번만 GPU에 올려놓으면 매 프레임마다 vertex info를 client에서 server로 전송할 필요가 없다.
[출처] VBO (Vertex Buffer Object)|작성자 gomdev
출처: http://gpgstudy.com/forum/viewtopic.php?t=4157
openGL의 정점버퍼는 따로 메모리 할당할 필요가 없나요?
운영자: 류광
16 개의 게시글 • 1개 중 1 페이지
비회원
openGL의 정점버퍼는 따로 메모리 할당할 필요가 없나요?
전체글 글쓴이: 비회원 » 2004-09-22 00:45
openGL에서 정점버퍼를 사용할려고 메모리 할당을 하고 정점버퍼를 설정했는데 에러가 나더군요..
그래서 다른 소스를 찾아보았더니 메모리 할당하는 부분이 없었습니다.
정점버퍼를 설정하면 자동으로 메모리 할당이 되는건가요?
supercms전체글: 32가입일: 2004-08-17 16:53연락처:
전체글 글쓴이: supercms » 2004-09-22 09:50
단순히 glDrawArray()나 glDrawElement()를 이용하는 것은 가속이 아닙니다
glBindBuffer()를 이용한 후 위 2개 함수중 하나를 사용해야 가속이 됩니다.
그리고..이것은 메모리 할당이 필요합니다.
1년내내 운동해서 살뺄려고 결심하는 1人..실천無
비회원
supercms님 glBindBuffer()에 대해 좀더 자세한 설명 부탁드립니
전체글 글쓴이: 비회원 » 2004-09-23 01:20
supercms님 glBindBuffer()에 대한 내용을 openGL프로그래밍 가이드와 openGL 게임
프로그래밍에서 찾아보았지만 안나와 있네요.. 좀더 자세한 설명 부탁드립니다.
행인전체글: 62가입일: 2004-05-25 22:30
re
전체글 글쓴이: 행인 » 2004-09-23 12:07
glBindBufferARB 는 ARB확장이라서 레드북에는 없습니다.
http://oss.sgi.com/projects/ogl-sample/ ... object.txt
뒷부분을 참고하세요. 검색을 생활화 합시다.
yegam400전체글: 67가입일: 2003-08-12 16:28
supercms님 glDrawElement도 가속이 됩니다.
전체글 글쓴이: yegam400 » 2004-09-23 15:57
VBO를 써도 glDrawElement나 glDrawArrays 함수를 써서 가속해서 렌더링 합니다.
VAR, VAO도 마찬가지구요.
비회원
VBO, VAR, VAO가 뭔가요?
전체글 글쓴이: 비회원 » 2004-09-23 20:46
VBO, VAR, VAO가 뭐의 약자인가요?
macwin전체글: 127가입일: 2001-08-04 09:00연락처:
전체글 글쓴이: macwin » 2004-09-23 21:46
VBO, VAR, VAO은
Vertex Buffer Object, Vertex Array Range, Vertex Array Object
입니다.
확장은 다양하지만.... VBO가 가장 편할겁니다. ARB니까요..
확장을 뒤져보니. VAR은 NVidia가 VAO는 ATI에서 지원하는 확장이네요.
별다른 확장없이도. glDrawElement나 glDrawArrays등을 사용하여 TnL가속이 된다고 들은적이 있습니다.
하지만, 그다지 가속한거 같진 않습니다.(물론 안한는 거보단 낫습니다만..) 아마 메모리 복사 오버헤드로 인해
그런거 같습니다. 일종의 D3D에서 매프레임 마다 락하는 거랑 비슷한 거겠죠.
EMAIL : macwin at hitel.net
http://blog.naver.com/macwin
비회원
네!!! 답변 감사합니다.^^
전체글 글쓴이: 비회원 » 2004-09-23 22:43
^^
yegam400전체글: 67가입일: 2003-08-12 16:28
VBO와 매프레임 Lock.
전체글 글쓴이: yegam400 » 2004-09-29 21:12
VBO를 사용한것에 glDrawArrays를 쓰는것과
사용안한 것에 glDrawArrays를 쓰는 것은
제가 아는 한도내에선 D3D의 예를 들자면
위의것은 DrawPrimitive,
아래의 것은 DrawPrimitiveUP(User Pointer)
에 대응 하는 함수 콜 방식인것 같습니다.
(glDrawElements는 DrawIndexedPrimitive, DrawIndexedPrimitiveUP이 되겠죠.)
VBO를 사용하지 않고 glDrawArrays를 쓰는 것은 매프레임 마다 락을 해서 DrawPrimitive를 하는게 아니라
Lock이 없이 User Pointer로 렌더링을 하는 DrawPrimitiveUP에 더 가깝다고 생각되어 집니다..
Lock을 하려면 glBufferData 에다가 옵션을 GL_DYNAMIC_BUFFER_ARB인가?? 옵션을 주고
glMapBuffer를 하면 상대적인 맵핑된 포인터를 넘겨줍니다.. 이게 Lock이죠..
(VBO는 그 오브젝트 아이디에 할당된 엔트리 포인트가 NULL 이죠.)
그럼 ^^ 이만 물러갈게요..
macwin전체글: 127가입일: 2001-08-04 09:00연락처:
개념적인 그 부분이 아주 궁금한데..
전체글 글쓴이: macwin » 2004-09-30 00:33
예전에 외국의 모사이트에서 엔비디아 관련 개발자 셨는데,
'openGL의 경우 별다른 확장 없이 버텍스포인터만으로도 TnL가속이 가능하다.' 라는 말을 했습니다.
그걸 뒷받침 하듯.. TnL시대를 연 지포스 1이 제대로 나오기 전에 만들어진 Quake3가 TnL가속 게임 목록에
올라와 있었고요.
하지만 실제 개발해보면 위의 부분이 참 의심이 갑니다. 단순히 버텍스포인터의 경우 포인터를 한번만
지정 하고 그 안의 내용을 바꾸어서 렌더링 해도.. 바뀐 내용이 잘 적용되어 렌더링 됩니다..
락같은 것도 안걸고, 그냥 시스템 메모리에 올라와 있는 걸 그냥 바꿔도 잘 적용이 되는데, TnL가속이
된답니다;; 그래서 가속이 되려면, 비디오 메모리에 올라와 있어야 하고, 그럴려면 시스템 메모리에 있는걸
렌더링 바로 직전에 비디오 메모리에다 옮기는게 아닌가라고 생각하고 있었죠.
물론 위의 문제의 진실은 드라이버 개발자만이 알 거 같네요. 혹시 이에 대해 정확히 알고 계시는 분이
계시다면 글을 적어주시면 감사하겠습니다.
EMAIL : macwin at hitel.net
http://blog.naver.com/macwin
Xine전체글: 253가입일: 2002-08-12 00:37
전체글 글쓴이: Xine » 2004-09-30 01:19
macwin 작성:TnL시대를 연 지포스 1이 제대로 나오기 전에 만들어진 Quake3가 TnL가속 게임 목록에
올라와 있었고요.
Quake 3의 힘은 아마도 glTranslate, glRotate 같은 OpenGL native 변환함수들의 적극활용과
화려한 이펙트때문에 격게되는 멀티패스렌더링에 대한 GL_EXT_compiled_vertex_array의 적극활용에서
오는것이 아닌가 싶습니다. 대부분의 데이터들이 정적인 상태라 효율도 아주 높을 것이구요.
이 두가지만 가지고도 흔히 말하는 "TnL" 가속게임이다라고 말하기에 충분한 것같습니다.

이덕희
jufoot전체글: 21가입일: 2002-05-10 09:00연락처:
soulhi 님의 말에 동감합니다.
전체글 글쓴이: jufoot » 2004-09-30 09:42
하지만 실제 개발해보면 위의 부분이 참 의심이 갑니다. 단순히 버텍스포인터의 경우 포인터를 한번만
지정 하고 그 안의 내용을 바꾸어서 렌더링 해도.. 바뀐 내용이 잘 적용되어 렌더링 됩니다..
락같은 것도 안걸고, 그냥 시스템 메모리에 올라와 있는 걸 그냥 바꿔도 잘 적용이 되는데, TnL가속이
된답니다;; 그래서 가속이 되려면, 비디오 메모리에 올라와 있어야 하고, 그럴려면 시스템 메모리에 있는걸
렌더링 바로 직전에 비디오 메모리에다 옮기는게 아닌가라고 생각하고 있었죠.
버텍스 배열 관련 확장은 T&L 과 연관이 없는 부분입니다...
이부분은 NVDIA 드라이버 개발자인 Cass 가 했던말이고요..
제가 알기로도 T&L 과 Vertex Transfering 와는 다른 개념입니다.
T&L 은 이미 메모리에 올라와있는 버텍스 데이터(Primitives)의 변환을 가속기에서 해준다는 말이고요..
VBO, VAR, VAO 등의 확장은 미리 데이터를 (STATIC 버퍼의 경우) AGP 메모리든 로컬메모리든..
올려놓아서 버텍스 포인터지정시에 오프셋값만을 세팅해서 가속기에 Vertex Transfering 을
없애준다는 개념입니다.
CVA 의 경우에는 이미 올려진 버텍스 배열을 재사용하는 의미이므로..
멀티패스 렌더링이 아니라면 큰 이점이 없습니다.
PS. 이미 T&L은 버텍스 쉐이더의 등장으로 구세대의 산물이 되어버렸습니다.
macwin전체글: 127가입일: 2001-08-04 09:00연락처:
T&L가속이 되려면,.,
전체글 글쓴이: macwin » 2004-09-30 12:01
T&L 은 이미 메모리에 올라와있는 버텍스 데이터(Primitives)의 변환을 가속기에서 해준다는 말이고요..
VBO, VAR, VAO 등의 확장은 미리 데이터를 (STATIC 버퍼의 경우) AGP 메모리든 로컬메모리든..
올려놓아서 버텍스 포인터지정시에 오프셋값만을 세팅해서 가속기에 Vertex Transfering 을
없애준다는 개념입니다.
텍스춰가 입혀진 폴리곤을 그리기 위해 텍스춰 매핑 소스를 비디오 메모리에 올리듯, 하드웨어 적으로
T&L가속을 받으려면, 반드시 비디오 메모리에 그 데이타가 올려져야 합니다.
즉, 시스템 메모리에 올려진 메쉬 데이터는 T&L가속이 될 수가 없습니다. 가속이 되려면 반드시 비디오
메모리로 그 데이타가 올려져야 합니다. 즉 VBO등의 확장으로 미리 올려두던가.. 아니면 렌더링 직전에
비디오 메모리에 복사가 이루어져야 되는거지요. 그렇게 때문에, 실제로 확장을 쓰지 않을 경우 T&L이 가속이
안되는건지, 비디오 메모리에 복사된 후 가속이 되는 건지 궁금해 했던 것입니다.
EMAIL : macwin at hitel.net
http://blog.naver.com/macwin

soaringhs전체글: 230가입일: 2001-07-30 09:00
전체글 글쓴이: soaringhs » 2004-09-30 12:25
그당시(?) Voodoo 1-3(4-5는 모르겠음) 시리즈는 지오메트리 연산을 CPU에서 하고 최종적으로
변환된 삼각형만 화면에 뿌려주는 기능만 있었습니다. Glide API를 보면 그냥 삼각형 그리는 함수만 있죠.
하지만 TNT는 GPU에서 지오메트리 연산을 지원하기 시작했고 이걸 가지고 하드웨어 TnL 지원이라고
광고하기 시작한것이죠. '지원' 과 '가속'은 조금 다른 예기죠.

aka makefile
jufoot전체글: 21가입일: 2002-05-10 09:00연락처:
전체글 글쓴이: jufoot » 2004-09-30 13:03
실제로 확장을 쓰지 않을 경우 T&L이 가속이
안되는건지, 비디오 메모리에 복사된 후 가속이 되는 건지 궁금해 했던 것입니다.
버텍스 데이터들은 실제로 GPU 쪽으로 복사되어진 후에 T&L 가속을 받습니다.
그러니까 macwin 님이 말씀하신데로 draw call 이 일어날때마다 시스템메모리에서
비디오 메모리로 매번 복사가 일어납니다.
아래는 OpenGL.org 포럼에서 찾아본 관련 내용입니다.
http://www.opengl.org/discussion_boards ... 3;t=000915
zupet전체글: 2764가입일: 2003-05-13 03:34사는 곳: NCSOFT LE팀
주제에서 좀 벗어나지만 H/W TnL 여부는..
전체글 글쓴이: zupet » 2004-09-30 13:23
안녕하세요. 매크로 없는 메비~랍니다.
조금 오해가 있는 것 같은데 H/W TnL 은 시스템 메모리가 아닌 로컬 메모리(비디오 카드 위의 메모리)
또는 AGP 메모리(비디오 카드와 공유된 AGP 메모리) 양쪽에서 모두 지원이 가능합니다. 아니..
꺼꾸로 로컬 메모리나 AGP 메모리에서만 가속이 지원이 되고 시스템 메모리에서는 H/W TnL 이 지원이 될 수 없습니다.
다른 여러가지를 떠나서 간단한 이유를 설명하자면 H/W TnL 이란 비디오 카드에서
직접 메모리에 접근해서 필요에 따라서 Vertex 정보를 '읽어가는' 작업을 하게 됩니다.
CPU와 통신을 하지 않고 그래픽 카드가 직접 움직이기 때문에 그래픽 카드에서
직접 접근할 수 있는 로컬 메모리나 AGP 메모리에 올라간 그래픽 데이터를 이용해서
TnL 작업을 해주게 됩니다. 그래픽 카드가 직접 움직이기 때문이 이때부터 nVidia 에서
GPU란 용어를 쓰기 시작했고 그 시초가 GeForce 256 이었죠. (GPU가 혼자 움직이기
위해서는 어떠한 명령들이 큐에 쌓일텐데 이것이 추후 발전해서 Batch란 용어가 되었으리라 생각하고 있습니다.)
그리고 그러한 작업 공간을 정의하기 위해서 주어진 것이 바로 DirectX 의 Vertex Buffer 라는
녀석이었고 이것을 통해서 로컬 메모리나 AGP 메모리를 '명시적으로 가르키 것'을 말하고 있습니다.
흠.. 말이 길어졌는데 어쨌거나 짚고 넘어갈 것은 H/W TnL 사용 어부는 굳이 로컬 메모리에 올라갈
필요 뿐만 아니라 AGP 메모리에서도 얼마던지 가능하다는 점입니다. GeForce 256/2 시절에
나온 몇몇 문서에서 이 부분을 정정하는 내용들이 있었고 아직 nVidia 개발자 사이트에서 찾을 수 있습니다.
뭐 간단한 테스트로 Optimized Mesh 등을 통해서 Device 변경, 로컬<->AGP 메모리 사용등을
번갈아가면서 테스트를 해볼 수 있으니까요.
그리고 D3D 에서 UP 관련 명령들도 Device가 H/W TnL을 지원하거나 특정 쉐이더를 쓰고 있을 경우
CPU를 사용하지 않고 D3D 에서 내부적으로 관리하는 AGP 메모리를 사용하여 렌더링이 된다고 알고 있습니다.
유저가 직접 Vertex Buffer를 만들 필요가 없다 뿐이지 실제로 H/W 내부적으로는 그러한 작업이 이뤄지는 것이죠.
그래서 UP 명령을 쓰더라도 그래픽카드가 내부적으로 H/W TnL을 사용하고 있을 가능성이 크다고 알고 있습니다.
(이건 D3D 문제가 아니라 도리어 그래픽 드라이버의 지원에 따른 문제겠죠.)
p.s.그렇다고 UP의 패널티가 없어지는건 아니죠. ^__^
'프로그래밍 관련 > 3D,2D DRAW 관련' 카테고리의 다른 글
| OpenGL 이동,회전,확대축소 관련 (0) | 2020.09.10 |
|---|---|
| OpenGL Projective Texture Mapping with OpenGL GLSL (0) | 2020.09.10 |
| DirectX, OpenGL 텍스처 필터링 (Texture Filtering) 관련 (0) | 2020.09.10 |
| [3D프로그래밍] 클리핑 관련 (0) | 2018.06.25 |
| Z-order in top-down 2d games (0) | 2017.11.08 |