T *p = new T; 위의 코드를 다음으로 바꿉니다. std::tr1::shared_ptr<T> p( new T );
자원을 획득하자마자 자원관리객체의 초기화 코드로 넘기는데 이를 자원획득즉초기화(RAII) 라 합니다.
2. delete[] 와 shared_ptr
shared_ptr 의 생성자는 타입T 의 포인터, 즉 T* 만을 받는 생성자가 있고 T* 와 삭제자(deleter) 를 받는 생성자도 있습니다. 삭제자를 넘겨주지 않는 첫 번째의 생성자같은 경우 shared_ptr 는 자신이 소멸할 때 자원에 delete 를 적용해줍니다. 근데 만약 아래처럼
std::tr1::shared_ptr<T> p( new T[10] );
동적 배열 자원을 넘겨주게 되면 new[] 로 할당된 자원을 delete[] 가 아닌 delete 로 반납을 행하는데 이런 경우오작동 또는 메모리 누수가 발생하게 됩니다. 이를 막기위해 두 가지 방식을 취할 수 있습니다.
첫 번째는 vector 와 같은 컨테이너로 여러 shared_ptr 객체를 이용하는 방법입니다.
std::vector< std::tr1::shared_ptr<T> > v( 10 ); v[0] = std::tr1::shared_ptr<T>( new T ); ...
두 번째는 delete[] 를 이용하는 삭제자를 정의( 일종의 함수객체 ) 하고 shared_ptr 의 생성자로 넘겨주는 방법입니다.
struct arrayDeleter { template< typename T > void operator()( T *p ) { delete[] p; } };
std::tr1::shared_ptr<T> p( new T[10], arrayDeleter() );
이렇게 하면 정상적으로 자원의 할당 / 반납이 행해집니다.
세 번째는 shared_array 사용 3. 삭제자의 다양한 활용
int a = 0; std::tr1::shared_ptr<int> p( &a );
어떤 변수를 포인터로 가리키는 경우는 자주 볼 수 있습니다. 그와 비슷하게 shared_ptr 로 지역변수 a 를 가리키도록 한 것이 위 의 코드입니다. 그러나, 객체 p가 소멸할 때 &a 에 delete 를 적용하기 때문에 결과적으로 delete &a; 동작이 소멸 과정에서 행해집니다. 여기서 a 는 동적 자원이 아닌 지역변수이기 때문에 에러가 발생하게 됩니다. 이를 막기위해 소멸과정에서 어떠한 동작도 행하지 않도록 빈 삭제자( Empty deleter ) 를 지정할 수 있습니다.
struct emptyDeleter { template< typename T > void operator()( T *p ){} };
int a = 0; std::tr1::shared_ptr<int> p( &a, emptyDeleter() );
이 번에는 C버전 파일입출력 라이브러리에서 fclose() 함수 호출을 shared_ptr 를 이용하여 자동으로 처리되도록 하는 예입니다.
struct fileCloser { void operator( FILE *f ) { if( f ){ fclose( f ); } } };
가끔 shared_ptr 객체가 관리하는 자원을 얻어내야 하는 경우가 있는데 그 땐 shared_ptr<T>::get() 멤법함수를 이용합니다.
std::tr1::shared_ptr<T> p( new T ); T *ptr = p.get(); // p.get() 은 T* 를 반환합니다.
5. 자원의 교체
shared_ptr 객체가 관리하고 있는 자원을 다른 자원 또는 NULL 로 만들어야 하는 경우는 shared_ptr<T>::reset() 멤버함수를 이용합니다.
std::tr1::shared_ptr<T> p( new T ); p.reset(); // 이제 p는 자원을 관리하지 않습니다. 기존의 자원은 안전하게 delete 됩니다. p.reset( new T ); // p는 새로운 자원을 관리합니다. p = std::tr1::shared_ptr<T>(); // 빈 shared_ptr 객체를 대입합니다. p.reset(); 과 동일합니다.
6. 복사와 참조 카운팅
shared_ptr 객체는 복사될 때마다 자원을 복사하는게 아닌 자원의 참조개수를 증가시킵니다.
std::tr1::shared_ptr<int> p( new int ); // 자원은 p에 의해 1번 참조됩니다. std::tr1::shared_ptr<int> p2( p ); // 자원은 p, p2에 의해 2번 참조됩니다. p.reset(); // 자원은 p2에 의해 1번 참조됩니다. p = p2; // 자원은 p, p2에 의해 2번 참조됩니다. p2.reset(); // 자원은 p에 의해 1번 참조됩니다. p.reset(); // 자원은 더 이상 참조되지 않음으로 delete 됩니다.
7. 조건문과 shared_ptr
기존 포인터를 이용할 때 유효한 포인터인지 확인하기 위해
int *p = &a; ... if( p != NULL ) { ... }
위의 코드처럼 if 를 이용하여 NULL 과 비교하곤 했습니다. 이를 shared_ptr 에서는 다음처럼 작성합니다.
std::tr1::shared_ptr<int> p( new int ); ... if( !p ) { ... }
위에서 !p 처럼 이용하면 됩니다. 즉 shared_ptr 객체는 bool 식으로 변환될 수 있습니다.
8. const 자원과 shared_ptr
상수 자원을 관리하거나 자원을 상수화시키기 위해 const 를 이용할 수 있습니다.
std::tr1::shared_ptr<int> p( new int ); // p객체는 언제든지 자원을 변경할 수 있습니다. std::tr1::shared_ptr<int const> q( new int ); // q객체는 자원을 읽을수는 있으나 변경할 수는 없습니다.
p = q; // 자원을 변경하지 못하는 q객체를 자원이 변경가능한 p에 복사합니다. // 그러나 이 코드는 컴파일되지 않습니다.
q = p; // 자원이 변경가능한 p객체를 자원을 변경하지 못하는 q객체에 복사합니다. // 컴파일이 잘 됩니다.
기존 포인터에서 적용되던 상수성을 그대로 유지해줍니다.
9. 상속과 shared_ptr
Child 클래스가 Parent 클래스를 public 상속했다고 할 때 기존 포인터를 이용하여
Parent *p = new Child;
위와 같이 작성할 수 있습니다. 이를 shared_ptr 로 작성하면 다음과 같습니다.
std::tr1::shared_ptr<Parent> p( new Child );
다형성을 이용하는 곳에도 별다른 지장없이 shared_ptr 를 이용할 수 있습니다.
10. typedef 활용
shared_ptr 를 이용하면 타입이름이 너무 길어지게 되는데 여기에 typedef 를 활용합니다.
class CMyClass; typedef std::tr1::shared_ptr<CMyClass> CMyClass_ptr;
struct person { std::string name; std::tr1::shared_ptr<person> myFriend;
person( const std::string &_name ) : name( _name ) { std::cout << name << "태어나다." << std::endl; } ~person() { std::cout << name << "죽다." << std::endl; } }; 그리고 아래와 같은 블럭이 실행되면 생성자는 제대로 호출되지만 소멸자가 호출되지 않는 문제가 발생합니다.
{ std::tr1::shared_ptr<person> kim( new person( "kim" ) ); std::tr1::shared_ptr<person> lee( new person( "lee" ) );
kim->myFriend = lee; lee->myFriend = kim; }
원인을 알아보겠습니다. 블럭의 끝에서 lee 객체가 먼저 소멸하는데 참조개수가 둘( 자신과 kim의 친구로) 이므로 참조개수를 하나 줄이고 소멸은 끝납니다. 즉 lee 의 참조개수는 1이고 kim의 참조개수는 2입니다. 다음 kim 객체가 소멸하는데 마찬가지로 참조개수가 둘( 자신과 lee의 친구로 ) 이므로 참조개수를 하나 줄이고 소멸이 끝납니다. 결과적으로.. kim, lee 둘 다 참조개수가 1인 상태로 남아있게 되는 문제가 발생했습니다.
이렇게 다른 객체끼리 서로 참조를 갖는 형태를 순환참조라 하며 shared_ptr 는 순환참조시 제대로 자원해제를 하지 못합니다. 이런 경우는 친구를 shared_ptr<person> 타입이 아닌 person* 타입으로 바꾸거나 빈 삭제자를 이용하거나 또 다른 스마트포인터중 하나인 weak_ptr 를 이용하여 해결할 수 있습니다. person* 타입으로 바꾸는 것은 쉽기 때문에 생략하고
스마트 포인터는 <memory> 헤더 파일의 std 네임스페이스에 정의됩니다. RAII 또는 Resource Acquisition Is Initialialization 프로그래밍 언어에 중요합니다. 이 관용구의 주요 목표는 개체의 모든 자원 생성이 한 줄의 코드에서 만들어지고 준비되어 그 개체가 초기화되는 동시에 자원 수집이 발생하는 것을 확인하는 것입니다. 실제로 RAII의 기본 원칙은 힙 할당 리소스(예: 동적 할당 메모리 또는 시스템 개체 핸들)의 소유권을 해당 소멸자가 리소스를 삭제하거나 비우는 코드 및 모든 관련 정리 코드가 포함된 스택 할당 개체에 제공하는 것입니다.
대부분의 경우 실제 리소스를 가리키도록 기본 포인터 또는 리소스 핸들을 초기화할 때는 포인터를 스마트 포인터로 즉시 전달합니다. 현대적인 C++에서 기본 포인터는 성능이 중요하며, 소유권 관련 혼동 여지가 없는 제한된 범위, 루프 또는 지원 함수의 작은 코드 블록에서만 사용됩니다.
void UseRawPointer() { // Using a raw pointer -- not recommended. Song* pSong = new Song(L"Nothing on You", L"Bruno Mars"); // Use pSong...// Don't forget to delete!delete pSong; } void UseSmartPointer() { // Declare a smart pointer on stack and pass it the raw pointer. unique_ptr<Song> song2(new Song(L"Nothing on You", L"Bruno Mars")); // Use song2... wstring s = song2->duration_; //... } // song2 is deleted automatically here.
예제에서와 같이 스마트 포인터는 스택에서 선언되고 힙 할당 개체를 가리키는 원시 포인터를 사용하여 초기화하는 스마트 포인터입니다. 스마트 포인터가 초기화되면 원시 포인터를 소유합니다. 원시 포인터가 지정한 메모리를 스마트 포인터가 삭제해야 함을 의미합니다. 스마트 포인터 소멸자에는 삭제할 호출이 포함되며, 스마트 포인터는 스택에 선언되기 때문에 스마트 포인터가 범위를 벗어나면 스택의 다른 위치에서 예외가 throw되더라도 해당 소멸자가 호출됩니다.
스마트 포인터 클래스 오버로드가 캡슐화된 원시 포인터를 반환하는 익숙한 포인터 연산자인 -> 및 *를 사용하여 캡슐화된 포인터에 액세스합니다.
C++ 스마트 포인터 관용구는 C# 같은 언어에서의 개체 생성과 유사합니다. 즉 개체를 생성한 후 시스템이 정확한 시간에 그것을 지울 수 있도록 합니다. 백그라운드에서 실행된 별도 가비지 수집기는 런타임 환경을 빠르고 효율적이게 만드는 표준 C++ 범위 지정 규칙을 통해 관리되는 메모리라는 것이 차이점입니다.
중요
매개 변수 목록이 아닌 별도 코드 줄에서 스마트 포인터를 만들어야 특정 매개 변수 목록 할당 규칙으로 인해 아주 작은 리소스 누수도 발생하지 않습니다.
다음 예제에서는 표준 템플릿 라이브러리의 unique_ptr 스마트 포인터 형식이 큰 개체에 대한 포인터를 캡슐화하는 데 어떻게 사용될 수 있는지 보여줍니다.
class LargeObject { public: void DoSomething(){} }; void ProcessLargeObject(const LargeObject& lo){} void SmartPointerDemo() { // Create the object and pass it to a smart pointer std::unique_ptr<LargeObject> pLarge(new LargeObject()); //Call a method on the object pLarge->DoSomething(); // Pass a reference to a method. ProcessLargeObject(*pLarge); } //pLarge is deleted automatically when function block goes out of scope.
이 예제는 다음과 같이 스마트 포인터를 사용하는 필수 단계를 보여 줍니다.
스마트 포인터를 자동(지역) 변수로 선언합니다. (스마트 포인터 자체에 new 또는 malloc 식을 사용하지 마십시오.)
형식 매개 변수에서 캡슐화된 포인터가 가리키는 대상의 형식을 지정합니다.
원시 포인터를 스마트 포인터 생성자의 new-ed 개체에 전달합니다. (일부 유틸리티 기능 또는 스마트 포인터 생성자로 이 작업을 자동으로 수행할 수 있습니다.)
오버로드된 -> 및 * 연산자를 사용하여 개체에 액세스합니다.
스마트 포인터로 개체를 삭제할 수 있습니다.
스마트 포인터는 메모리 및 성능 관점에서 최대한 효율적으로 사용할 수 있도록 설계되었습니다. 예를 들어, unique_ptr의 유일한 데이터 멤버는 캡슐화된 포인터입니다. 즉, unique_ptr은 해당 포인터와 정확히 동일한 크기(4바이트 또는 8바이트)입니다. 스마트 포인터 오버로드된 * 및 -> 연산자를 사용하여 캡슐화된 포인터에 액세스하면 원시 포인터에 직접 액세스하는 것보다 크게 느려지지 않습니다.
스마트 포인터에는 "점" 표기법을 사용하여 액세스할 수 있는 고유한 멤버 함수가 있습니다. 예를 들어, 일부 STL 스마트 포인터에는 포인터 소유권을 릴리스하는 멤버 다시 설정 기능이 있습니다. 다음 예에 표시된 것처럼 스마트 포인터가 범위를 벗어나기 전에 스마트 포인터에서 소유하는 메모리를 비우려는 경우에 유용합니다.
void SmartPointerDemo2() { // Create the object and pass it to a smart pointer std::unique_ptr<LargeObject> pLarge(new LargeObject()); //Call a method on the object pLarge->DoSomething(); // Free the memory before we exit function block. pLarge.reset(); // Do some other work... }
스마트 포인터는 일반적으로 원시 포인터를 직접 액세스하는 방법을 제공합니다. STL 스마트 포인터에는 이 목적의 get 멤버 함수가 포함되며, CComPtr에는 공용 p 클래스 멤버가 포함됩니다. 기본 포인터에 대한 직접 액세스를 제공하면 스마트 포인터를 사용하여 자체 코드에서 메모리를 관리하고 스마트 포인터를 지원하지 않는 코드에 원시 포인터를 전달할 수 있습니다.
void SmartPointerDemo4() { // Create the object and pass it to a smart pointer std::unique_ptr<LargeObject> pLarge(new LargeObject()); //Call a method on the object pLarge->DoSomething(); // Pass raw pointer to a legacy API LegacyLargeObjectFunction(pLarge.get()); }
다음 섹션에서는 다양한 종류의 Windows 프로그래밍 환경에서 사용할 수 있는 스마트 포인터에 대한 정보를 요약하고 사용하는 경우에 대해 설명합니다.
C++ 표준 라이브러리 스마트 포인터 POCO(Plain Old C++ 개체)에 대한 포인터를 캡슐화하는 데 가장 먼저 스마트 포인터를 사용합니다.
unique_ptr 기본 포인터로 한 명의 소유자만 허용합니다. shared_ptr이 필요하다는 점을 확실히 알 경우 POCO의 기본 선택으로 사용합니다. 새 소유자로 이동할 수 있지만 복사하거나 공유할 수 없습니다. 사용하지 않는 auto_ptr을 대체합니다. boost::scoped_ptr과 비교합니다. unique_ptr은 작고 효율적이며, 크기는 1 포인터이고 STL 컬렉션에서 빠른 삽입 및 검색을 위해 rvalue 참조를 지원합니다. 헤더 파일: <memory>. 자세한 내용은 방법: unique_ptr 인스턴스 만들기 및 사용 및 unique_ptr 클래스를 참조하십시오.
shared_ptr 참조 횟수가 계산되는 스마트 포인터입니다. 원시 포인터 하나를 여러 소유자에게 할당하려고 할 경우 사용합니다(예: 컨테이너에서 포인터 복사본을 반환할 때 원본을 유지하고 싶을 경우). 원시 포인터는 모든 shared_ptr 소유자가 범위를 벗어나거나 소유권을 포기할 때까지 삭제되지 않습니다. 크기는 2개의 포인터입니다. 하나는 개체용이고, 다른 하나는 참조 횟수가 포함된 공유 제어 블록용입니다. 헤더 파일: <memory>. 자세한 내용은 방법: shared_ptr 인스턴스 만들기 및 사용 및 shared_ptr 클래스를 참조하십시오.
weak_ptr shared_ptr과 함께 사용할 수 있는 특별한 경우의 스마트 포인터입니다. weak_ptr은 하나 이상의 shared_ptr 인스턴스가 소유하는 개체에 대한 액세스를 제공하지만, 참조 수 계산에 참가하지 않습니다. 개체를 관찰하는 동시에 해당 개체를 활성 상태로 유지하지 않으려는 경우 사용합니다. shared_ptr 인스턴스 사이의 순환 참조를 차단하기 위해 필요한 경우도 있습니다. 헤더 파일: <memory>. 자세한 내용은 방법: weak_ptr 인스턴스 만들기 및 사용 및 weak_ptr 클래스를 참조하십시오.
COM 개체의 스마트 포인터(Windows 기본 프로그래밍) COM 개체를 사용하는 경우 인터페이스 포인터를 적절한 스마트 포인터 형식으로 래핑합니다. ATL(Active Template Library)은 다양한 목적을 위해 여러 스마트 포인터를 정의합니다. .tlb 파일에서 래퍼 클래스를 만들 때 컴파일러가 사용하는 _com_ptr_t 스마트 포인터 형식을 사용할 수도 있습니다. ATL 헤더 파일을 포함하지 않으려는 경우에 가장 좋습니다.
_com_ptr_t 클래스 기능 면에서 CComQIPtr과 유사하지만 ATL 헤더에 의존하지 않습니다.
POCO 개체에 대한 ATL 스마트 포인터 ATL은 COM 개체에 대한 스마트 포인터뿐만 아니라 이전 일반 C++ 개체에 대한 스마트 포인터 및 스마트 포인터 컬렉션을 정의합니다. 클래식 Windows 프로그래밍에서 이러한 형식은 특히 코드 이식이 필요하지 않거나 STL 및 ATL 프로그래밍 모델을 혼합하지 않으려는 경우에 STL 컬렉션에 대한 유용한 대안이 될 수 있습니다.
CAutoPtr Class 복사 소유권을 전송하여 고유 소유권을 적용하는 스마트 포인터입니다. 사용되지 않는 std::auto_ptr 클래스에 비교할 수 있습니다.
std::unique_ptr은 사용권을 양도하는 식으로 자원을 관리했다. 하지만 실제로 우리가 할당된 자원(포인터)을 사용할 때 unique한 방식보다는 여러 곳에서 그 자원을 공유하는 방식으로 사용하게 된다. 하지만 처음 할당한 자원을 여기저기에서 참조하고 있으면 dangling 포인터와 같은 자원관리 문제가 발생하기 쉽다. Java에는 Garbage Collection이라는 자동 자원관리 방식을 지원해서 공유된 자원에 유저가 신경쓸 필요없이 편하게 프로그래밍이 가능하다. 대신 유저가 자원이 해제되는 시점에 대해서 알기 어렵다는 단점이 있다. C++ 11부터는 shared_ptr을 사용하여 두가지 목표(자동 자원관리, 예측 가능한 해제시점)를 모두 달성할 수 있게 해준다.
shared_ptr의 동작 방식
shared_ptr은 이름처럼 할당된 자원을 소유하지 않고 그저 가리키고 있는 포인터이다. 대신 자원이 더 이상 필요하지 않은 적절한 시점을 파악하고 알아서 자원을 해제해주는 방식으로 자원을 관리한다. garbage collection의 경우 내부적인 복잡한 규칙에 따라서 이 시점을 찾아 해제하지만, share_ptr은 참조횟수를 추적하여 참조횟수가 0이 되면 삭제하는 단순한 룰로 동작한다.(대신 여러 민감한 이슈들(순환 참조등)은 유저가 알아서 처리해야하겠지만...)
shared_ptr이 참조 횟수를 관리하는 방법은 다음과 같다. shared_ptr의 생성자(default or 복사)가 호출되면 가리키는 object의 참조 횟수를 증가시킨다. 소멸자가 호출되면 가리키는 object의 참조횟수를 감소시킨다. 복사 할당자가 호출되면, sp1 = sp2; 이 상황에서 sp1가 가리키던 object의 참조 횟수는 감소되고 sp2가 가리키는 object의 참조 횟수는 증가한다. move 생성/할당에 대해서는 기존의 포인터를 제거하고 그대로 이전하는 것이므로 참조횟수를 변경시키지 않는다. 참조 횟수 증가 감소는 atomic한 연산으로 동작해야한다. 참조횟수가 0이 되는 순간 자원을 해제해야하는데 참조횟수를 증가하고 감소시키는 연산이 경쟁상태에 돌입하게 된다면, shared_ptr이 가리키는 객체의 상태가 undefine될 것이기 때문이다.
앞에서 말한것처럼 shared_ptr은 일반 raw pointer와 달리 참조 횟수를 관리해야한다. 참조 횟수는 같은 객체를 가르키는 shared_ptr끼리 공유하는 자원이기 때문에 참조 횟수를 관리하는 객체는 하나의 shared_ptr에 있을 수는 없다. 그래서 shared_ptr이 다루는 참조 횟수는 별개로 할당된 객체에게 관리되어야한다. 참조 횟수를 관리하는 객체의 자원도 참조횟수가 0이 되면 share_ptr이 가리키는 객체의 자원과 함께 해제될 것이므로 자원관리의 문제는 없다. 어쨌든 shared_ptr은 가리키는 대상의 주소 뿐만아니라 참조 횟수를 관리하는 객체의 주소도 가지고 있어야한다. 그래서 가리키는 객체의 포인터 + 참조횟수 관리 객체 포인터 해서 2배의 크기를 갖는다. (그래봤자 8바이트 in 32bit 지만)
정확히 말하면 참조 횟수'도' 관리하는 객체로 표현해야하겠다. 이 객체는 일반 참조 횟수뿐 아니라, weak 참조 횟수(item 21에서 설명), unique_ptr에서 봤던 custom deleter(item 18참조) 및 allocator 그리고 기타등등에 해당하는 정보를 가지고 있다. 그래서 shared_ptr은 unique_ptr 처럼 custom deleter에 따라서 새로운 타입을 만들어낼 필요가 없다.
auto loggingDel = [](Widget* pw) //Custom Deleter { makeLogEntry(pw); delete pw; } std::unique_ptr<Widget, delctype(loggingDel)> //deleter가 ptr 타입의 부분이된다.upw( new Widget, loggingDel); std::shared_ptr<Widget> spw( new Widget, loggingDel); //deleter랑 상관없는 ptr 타입
deleter가 달라도 타입이 같다는 것은 매우 큰 강점이다. 우선은 쓰기가 쉽고(^^), 같은 컨테이너(벡터, 리스트)에 같이 담을 수도 있고, 하나의 패러미터 타입에 전달할 수도 있다.
auto customDeleter1 = [](Widget* pw){...} //서로 다른 deleter 생성auto customDeleter2 = [](Widget* pw){...} std::shared_ptr<Widget> pw1(new Widget, customDeleter1); std::shared_ptr<Widget> pw2(new Widget, customDeleter2); std::vector<std::shared_ptr<Widget>> vpw{pw1, pw2}; //같은 벡터에 담을수도 있고voidfunc(std::shared_ptr<Widget> arg); func(pw1); //함수의 인자로 똑같이 전달할 수 있다.func(pw2);
item18에서 말한것 처럼 만약 람다로 이루어진 deleter가 엄청나게 많은 state을 갖게 된 경우를 생각해보면, unique_ptr은 점점 무거워 질 것이다. 하지만 shared_ptr은 이런 deleter들을 따로 갖고 있는것이 아니라 control block에 저장해 두기 때문에, 용량이 늘어나지도 않는다.
참조 횟수를 관리하는 객체 Control Block
control block 덕분에 share_ptr은 쉽고 간단하게 사용할 수가 있었다. 실제로 control block은 share_ptr이 가리키는 객체의 자원관리에 있어서도 많은 역할을 한다. 사실상 shared_ptr이 아니라 이 객체가 할당한 자원을 관리한다고 봐도 무방할 것이다. 그렇다면 자원할당된 하나의 객체에 하나의 control block만 있는 것이 이상적이다. 이제 이 객체를 언제 생성하느냐에 대한 문제로 넘어가게 된다. 원칙적으로 shared_ptr에 의해 특정 객체가 처음 referencing 되었을 때 이 객체를 생성해야할 것이다. shared_ptr은 다음의 룰에 따라서 control block을 생성한다.
std::make_shared (item 21에서 자세히다룸)으로 shared_ptr을 생성할 때마다 control block이 생성된다. 이 함수는 아직 공유되지 않은 특정 자원(객체)을 공유하겠다고 선언하는 것과 같다. shared_ptr이 이 함수의 생성만으로 만들어지면 좋겠지만 현실은 그렇지 않기에 다음의 룰들이 추가된다.
unique한 소유권이 보장된 포인터(ex: unique_ptr, auto_ptr)로 부터 shared_ptr이 생성된 경우 control block이 생성된다. 위의 내용과 다르지 않다. 아직 공유되지 않았다는것이 확실하므로, 이제부터 공유 자원으로 등록하는 의미에서 control block을 새로 만들어 낸다.
raw pointer로 shared_ptr이 만들어졌을 때 control block을 생성한다. 이 조건에는 해당 raw pointer가 다른 shared_ptr 또는 weak_ptr(item 20에서 설명)에 의해서 따로 공유된 적이 없다는 전제가 깔려있다. 이미 공유된 raw pointer를 다시 새로운 control block으로 공유한다면, 같은 포인터에 대해서 여러개의 control block이 생기는 불상사가 발생할 것이다. 그러므로 이미 공유된 자원은 raw pointer가 아니라 반드시 shared_ptr 또는 weak_ptr로 다루어야 할 것이다.
중복된 Control Block을 피하는 방법
세 번째 룰은 매우 위태위태해 보인다. 이 룰에 의해서 같은 자원(raw 포인터)에 대해 다수의 control block이 생성된다면 같은 자원에대해 레퍼런스 카운터가 별도로 동작하고, 그래서 각각 0이 된 시점이 달라 별도로 해제하고, 그러면 댕글링 포인터문제가 발생할 수밖에 없다. 쉬운 예시를 통해 문제가 발생하는 경우를 알아보자.
//자원할당된 raw pointerauto pw = new Widget; ... //raw로 만드니 control block도 같이 할당 std::shared_ptr<Widget> spw1(pw, loggingDel); ... //raw로 만드니 control block도 같이 할당2 std::shared_ptr<Widget> spw2(pw, loggingDel);
위 예제만 보면 문제가 바로 보이지만, 중간에 코드가 길다면 누구나 쉽게 할 수 있는 실수이다. 그러니까 shared_ptr을 생성할때 가능하면 raw pointer를 쓰지 않는게 좋다. 가장 좋은 방법은 std::make_shared를 명시적으로 사용하는 것이다. 하지만 make_shared는 custom deleter를 지정할 수 없다는 문제가 있다. 위 예제에서 std::make_shared를 쓸 수 없는 이유가 이것이다. 그러면 같은 raw pointer를 다시 사용할 수 없게 만들어 버리는 방법도 있다.
//생성자를 사용해서 바로 shared_ptr을 만들자! std::shared_ptr<Widget> spw1(new Widget(), loggingDel); ... //raw pointer대신 shared_ptr로 생성 (컨트롤 블록 만들어지지 않는다.) std::shared_ptr<Widget> spw2(spw1);
shared_ptr에서 자원을 중복해서 공유하는 많은 케이스는 this 포인터를 shared_ptr로 만드는 경우에서 발생한다. this도 분명한 raw Pointer이므로 this로 shared_ptr을 만들면 새로운 control block이 생겨난다. 하지만 외부에서 해당 객체를 shared_ptr로 만드는 코드가 있다면 여기서 문제가 발생한다. 이것은 한눈에 알아보기 쉽지 않기때문에, 찾기 어려운 버그가 될 수 있다. 다음의 예제를 보면서 더 이야기를 해보겠다.
//작업 완료된 위젯들을 저장하는 벡터 std::vector<std::shared_ptr<Widget>> processedWidget; classWidget{ public: ... voidprocess(){ ... //작업 끝나고 벡터에 this를 집어넣는다.//이러면 this가 shared_ptr<Widget>으로 변환되어 저장. //raw pointer로 shared_ptr을 생성하므로 control block이 할당//이 함수 호출될 때마다 새로운 블럭이 생성되는 미친 코드//한번만 호출되는 것이 보장된다고 해도 외부에서 이 객체를 shared_ptr로 만들면 문제발생 processedWidgets.emplace_back(this); } }
std::shared_ptr을 만든 사람들은 이런 문제에대한 예방책을 미리 마련해 두었다. 이름이 좀 길긴하지만, std::enable_shared_from_this를 사용하면 이 문제를 미연에 방지할 수 있다. std::enable_shared_from_this를 상속받은 클래스는, 그 이름처럼 this를 가지고 shared_ptr을 안전하게 만들 수 있는 멤버함수를 상속받는다. shared_from_this()를 호출하게 되면 this를 가지고 shared_ptr를 생성할때, 컨트롤 블록을 새로 생성하지 않고, 기존의 컨트롤 블록을 가진 새로운 shared_ptr을 생성하여 반환한다.
이 해결방안에는 숨겨진 전제가 있다. this로 shared_ptr을 한번은 만들어서 컨트롤 블록을 생성해놔야 된다는 것이다. 만약 this에 대한 컨트롤 블록이 없다면 shared_from_this()함수는 예외를 throw하거나 정의되지 않은 동작을 수행할 것이다. 이런 이유에서 enable_shared_from_this를 상속받는 클래스는 보통 생성자 대신 생성자 역할을 하는 함수를 만들고 생성자를 호출한뒤에 shared_ptr로 만들어 컨트롤 블록등 미리 등록하는 방법을 사용한다.
classWidget : publicstd::enable_shared_from_this<Widget> { public://생성자에게 perfect-forwarding을 하는 팩토리 함수//그리고 this의 shared_ptr을 리턴하여 //인스턴스가 각각 반드시 하나의 컨트롤 블럭을 갖을 수 있도록template<typename ... Ts> static std::share_ptr<Widgetr> create(Ts&& ... params); ... voidprocess() { ... //완전 문제없이 this의 shared_ptr을 받아서 사용가능! processedWidgets.emplace_back(shared_from_this()); } private:Widget(); //생성자를 private로 만들어서 외부에서 접근불가능하게 만든다. }
shared_ptr은 비싸다?
지금까지 shared_ptr에 대한 여러 내용을 알아보았는데, shared_ptr을 운영하는데 필요한 자원이 적지 않아보인다. 우선 control block에 들어가는 수많은 정보를 저장하려면 많은 메모리가 사용될 것같다. 그리고 control block이 하는 일들을 구현하기 위한 atomic 연산들과 제대로 해제하기 위해서 가상함수들의 비용이 만만치 않아보인다. 하지만 scott meyers가 말하길 shared_ptr은 모든 자원관리에 대한 해답은 아니지만, 그것이 제공하는 편의에 대해서 매우 정직한, 이유있는 비용을 사용한다고 한다.
우선 default 소멸자나 할당자를 사용하는 shared_ptr을 make_shared로 할당하는 경우(대부분의 경우), control block은 3 word의 크기면 충분하고, 컨트롤 블럭을 할당하는데 드는 비용은 거의 공짜다.(이후 item 21에서 자세하게 설명한다). 그릐고 shared_ptr을 역참조하는데 드는 비용도 기존의 raw pointer와 동일하다. 참조 횟수를 관리하는 두개의 atomic 연산의 경우 분명 non-atomic한 연산보다는 비싸겠지만, 각각의 동작이 하나의 CPU 명령어(instruction)에 매핑되어서 매우 빠르게 동작할 수 있다. 가상함수의 경우 오직 소멸자 호출에서 한번씩만 사용되므로, shared_ptr 한개당 한번씩만 호출된다고 생각하면 그렇게 큰 비용이 든다고 할 수 없다.
이런 비용을 지불해서 자동적으로 관리되는 자원 체계를 얻는 것은 분명한 이득일 것이다. 대부분의 경우 shared_ptr을 사용하는 것이 직접 자원을 관리하는 것보다 훨씬 선호된다. 그렇다고 마냥 shared_ptr을 사용하라는 말은 아니다. 만약 공유되는 자원이 필요없는 경우라면 unique_ptr을 사용하는 것이 더 좋은 선택이 된다. unique_ptr의 비용은 거의 raw pointer와 다를 바 없기 때문이다. 그리고 unique_ptr은 shared_ptr로 변환가능하지만, 그 반대는 불가능하다.
unique_ptr과는 달리 shared_ptr은 배열을 다룰 수 없다. std::shared_ptr<T[]> 는 없는 타입이다. 물론 배열의 첫번째 포인터를 shared_ptr로 만들고 deleter를 delete[]로 설정하는 방법으로 사용할수도 있겠다. 하지만 shared_ptr은 []연산자를 지원하지 않기 때문에, 이런 배열을 사용하는 것은 이상한 문법이 될것이다. 대신 c++ 11에서 지원하는 배열타입들을 shared_ptr로 관리하는 것이 더욱 현명한 방법이 될 것이다.
- 정상적인 함수 종료에 의한 함수 종료든 Exception이 발생하였든 소멸자는 항상 호출된다.
가비지 컬렉션
- 일부 언어들은 자동 가비지 컬렉션 기능을 제공하지만 C++은 그렇지 못하다.
스마트 포인터는 가비지 컬렉션 용도로 사용할 수 있다.
효율성
- 스마트 포인터는 가용한 메모리를 좀 더 효율적으로 사용할 수 있게 하며 할당, 해제 시간을 단축 시킬 수 있다.
COW( Copry On Write ) : 1개의 객체가 수정되지 않는 동안 여러 COW 포인터가 해당 객체를 가리킬 수 있도록 하되, 해당 객체가 수정되는 경우 COW 포인터가 객체를 복사 한 후 복사 본을 수정하는 방법
객체가 할당되거나 운용되는 환경에 대해 일부 가정을 세울 수 있는 경우 최적화된 할당 계획이 가능하다.(운영 체제나 응용 프로그램이 변경된다 하더라도 클래스의 코드를 최적화된 할당 계획을 만들 수 있다.)
스마트 포인터의 단점
스마트 포인터가 NULL 인지 체크 불가
상속 기반의 변환 제한
상수 객체에 대한 포인터 지원 제한
구현하기 까다롭다.
이해하기 쉽지 않아 유지보수도 어렵다.
디버깅이 어렵다.
스마트 포인터의 종류
STL 라이브러리에 공식직원하는 스마트 포인터는
auto_ptr, shared_ptr, unique_ptr, weak_ptr이 있다.
그리고 부스터 라이브러리에서 제공하는 scoped_ptr, shared_array 등이 있다.
auto_ptr
정의
포인터 변수와 비슷하게 동작하는 객체로써, 가리키고 있는 대상(동적 할당 된 대상)에 대해 auto_ptr 클래스의 소멸자가 자동으로 delete를 호출하는 클래스이다.
특징
복사 시 소멸식 복사를 하기 때문에 소유권을 이전한다. 그러므로 컨테이너에 절대 넣으면 안 된다.
내재된 포인터에 대해 오직 하나만의 소유만을 허용한다.
C++11에 이르러 표준에서 제외되었으며 유사한 기능성에, 보다 안정적인 unique_ptr로 대체되었다.어떠한 자원을 가리키는 auto_ptr의 개수가 둘 이상이면 절대로 안되기 때문에, auto_ptr 객체를 복사하면(복사 생성자 혹은 복사 대입 연산자를 통해) 원본 객체가 가리키는 값을 null로 만든다.즉, 복사된(copying) 객체만이 그 자원 의 유일한 소유권(ownership)을 갖는다.
C++11이 등장하기 전에도 이미 std::auto_prt 이라는 스마트 포인트를 사용했었다. 그러나 auto_ptr이 포인터에는 소유권의 문제가 있다. 내부 구현에서 auto_ptr의 복사 생성자와 할당 연산자 구현이 멤버 데이터에 대한 깊은 복사(전체 내용의 복사) 대신 얕은 복사(포인터만 복사)를 하도록 되어 있기 때문이다. 그래서 함수 안으로 온전한 auto_prt객체를 전달하기 힘들다는 문제가 있다.
함수 인자로 auto_ptr을 전달하면 복사 생성자가 호출되고 그 결과 얕은 복사가 발생하기 때문이다. 얕은 복사를 하는 특성 덕분에 특정 순간 객체의 소유권이 유일하게 하나의 auto_ptr 객체에만 존재한다는 장점도 있다. 말 그대로 복사를 허용하지 않는 것이다. 하지만 이러한 장점을 전부 덮어버릴 만한 단점이 있었으니, auto_ptr 객체는 복사가 필요한 곳에서는 사용될 수 없다는 점이다.
새로운 C++11 표준에서는 복사 시맨틱에 추가로 새로운 개념인 이동 시맨틱이 등장했다. 이동 시맨틱은 복사 시맨틱처럼 두 객체 사이에 복사를 수행하는 대신, 객체의 데이터 필드 하나하나를 이동시키는 역할을 수행한다. 두 객체간의 데이터 이동이 발생한 후에는 해당 데이터에 대한 소유권은 데이터를 받는 쪽이 갖는다. 이동 시맨틱이 필요한 이유는 무엇일까? STL의 벡터나 리트스와 같은 컨테이너의 경우, 일동의 동적 배열이기 때문에 그 크기가 상황에 따라 두배씩 늘어난다. 이때 메모리 내부에서는 대량의 복사가 발생한다. 그리고서 원본은 파괴하고 사본만 사용을 한다.
단지 배열의 크기를 늘리기 위해서 불필요한 복사 동작을 하는점, 그리고 이로 인해 쓸데없는 객체를 생성하거나 사용하지 않는 원본 객체를 파괴한다는 점등 일련의 불필요한 동작은 C++성능 저하의 주범이라는 눈총을 받았다. 이런 경우 복사보다는 이동이 낫겠다고 판단하여 이동시맨틱을 도입했고, 이를 위해 이동 생성자라는 개념을 도입했다.
C++에서는 std::unique_ptr이라는 이름의 새로운 단일 포인터 타입을 도입하여, std::auto_ptr과 하위호환을 이룬다. std::unique_ptr 내부에서는 복사 생성자와 할당 연산자가 아예 구현되어 있지 않다. unique_ptr객체는 복사가 원천 봉쇄되어 있고 단지 이동만 가능하다. 반드시 std::move()라는 함수를 이용해야만 이동할 수 있다.
#include<memory> // for unique_ptrintmain(int argc, char** argv){ std::unique_ptr<int> p1(newint(5)); // std::unique_ptr<int> p2 = p1; // compile Error (복사를 허용하지 않음)std::unique_ptr<int> p3 = std::move(p1); // move p3, p1은 존재하지 않음. p3.reset(); // 메모리 영역 초기화 p1.reset(); // 이미 없으므로 효과없음. } #include<memory>usingnamespacestd; intmain(int argc, char** argv){ unique_ptr<int> p1(newint(5)); // create p1 unique_ptr<int> p3 = move(p1); // move to p3cout<<p1.get()<<endl; cout<<p3.get()<<endl; // 주소 반환cout<<*p3<< endl; // (5)라는 값을 얻음auto a = *p3; cout<<a<< endl; // (5)auto& a2 = p3; cout<<*a2<< endl; // (5)// auto b = *p1; // 런타임 에러(p3로 이전됨)// cout<<b<< endl; // 런타임 에러 p3.reset(); // 메모리 삭제 p1.reset(); // 아무것도 하지 않음return0; } #include<memory> // unique_ptr#include<iostream> // cout, endl#include<string>usingnamespacestd; class Person { public: Person() {}; Person(int age, std::string name) : age(age), name(name) {} ~Person() {}; public: intGetAge(){ return age; } stringGetName(){ return name; } private: int age; string name; }; intmain(int argc, char** argv){ unique_ptr<Person> p(new Person(1, "Baby")); cout<<"Name: "<<p->GetName()<<endl; cout<<"Age: "<<p->GetAge()<<endl; getchar(); return0; }
shared_prt
shared_ptr은 이름이 의미하듯 포인터가 가리키는 객체의 소유권을 이곳 저곳에서 공유할 수 있도록 디자인된 포인터이다. 바로 이 점이 unique_ptr과 shared_ptr을 구별하는 가장 큰 성질이라고 할 수 있다. 복사를 허용하지 않았던 uinique_ptr과는 달리 shared_ptr에서는 특정 보인터 객체를 여러 개의 shared_ptr 객체가 가리키도록 할 수 있다.
이런 shared_ptr을 컴파일어에서 구현하려면 레퍼런스 카운팅 이라는 방법을 사용합니다. 레퍼런스 카운팅은 여기저기로 복사되는 shared_ptr객체를 추적하려고 컴파일러가 몇 번이나 복사되는지 횟수를 기억하는 방식이다. shared_ptr 객체가 새롭게 복사될 때마다 카운터는 하나씩 증가되고, shared_ptr 객체가 삭제될 때는 그만큼 카운터의 횟수를 줄인다 이러한 메커니즘을 이용하여 객체의 저장 메모리 공간은 한 곳만 사용하고, 몇번 복사됐는지 횟수만 기억함으로써 메모리 공간도 절약할 수 있고, 처리속도도 향상시킬 수 있다. 해당 메모리 공간이 해제 되는 시점은 Shared_ptr 객체의 레퍼런스 카운트가 0이 되는 때 이다.
class Car {...}; // Resource Acquisition Is Initializing : RAIIstd::shared_ptr<Car> Avante( new Car() ); // 즉, std::shared_ptr<_Ty> Object( new _Ty(construct) );의 형식을 띈다.
Reference Count의 증가와 감소
증가 : shared_ptr 객체의 복사나 대입이 발생하여 참조 shared_ptr 객체 수 증가.
감소 : shared_ptr이 가리키고 있는 객체를 참조하는 shared_ptr 객체 수의 감소.
소멸시 주의 사항
기본적으로, shared_ptr은 소멸시 참조 카운트가 0 이 되면, 참조하는 객체에 대해 delete 연산자를 사용한다. delete만 사용한다는 소리다. 즉, delete [] 따윈 사용해 주지 않는단 말이다.
따라서, 아래와 같이 하면 new-delete, new [] - delete []를 지키지 않았을 때의 문제가 그대로 나타나는 것이다.
template<class _Ux> explicitshared_ptr(_Ux *_Px){ // construct shared_ptr object that owns _Px _Resetp(_Px); } template<class _Ux, class _Dx> shared_ptr(_Ux *_Px, _Dx _Dt) { // construct with _Px, deleter _Resetp(_Px, _Dt); } template<class _Ux, class _Dx, class _Alloc> shared_ptr(_Ux *_Px, _Dx _Dt, _Alloc _Ax) { // construct with _Px, deleter, allocator _Resetp(_Px, _Dt, _Ax); }
두 번째 생성자의 정의부터 보이는 class _Dx를 우리가 정의한 클래스로 지정시, 이는 shared_ptr의 참조 카운트가 0 이 될 때의 deleter 클래스가 된다.
// deleter 클래스 정의template<typename T> struct ArrayDeleter { voidoperator()(T* p){ delete [] p; } }; // shared_ptr 생성시 두 번째 인자로 deleter class를 넘기면...// 아무런 문제없이 객체 배열도 제대로 delete [] 처리가 된다.std::shared_ptr<int> spi( newint[1024], ArrayDeleter<int>() );
참조 객체 형변환 shared_ptr 비멤버 함수를 통해 shared_ptr이 참조하고 있는 객체의 형변환을 수행할 수 있다.
template<class _Ty1, class _Ty2> shared_ptr<_Ty1> static_pointer_cast(constshared_ptr<_Ty2>& _Other) { // return shared_ptr object holding static_cast<_Ty1 *>(_Other.get())return (shared_ptr<_Ty1>(_Other, _Static_tag())); } template<class _Ty1, class _Ty2> shared_ptr<_Ty1> const_pointer_cast(constshared_ptr<_Ty2>& _Other) { // return shared_ptr object holding const_cast<_Ty1 *>(_Other.get())return (shared_ptr<_Ty1>(_Other, _Const_tag())); } template<class _Ty1, class _Ty2> shared_ptr<_Ty1> dynamic_pointer_cast(constshared_ptr<_Ty2>& _Other) { // return shared_ptr object holding dynamic_cast<_Ty1 *>(_Other.get())return (shared_ptr<_Ty1>(_Other, _Dynamic_tag())); } class Car {...}; class Truck : public Car {...}; // Truck 타입의 객체를 Car 타입의 객체를 참조하는 shared_ptr에 초기화shared_ptr<Car> pCar( new Truck() ); // shared_ptr<Car>가 참조하고 있던 객체를 Truck 타입으로 static_cast하여 대입.// 대입 하였기에 참조 카운트는 '2'shared_ptr<Truck> pTruck = static_pointer_cast<Truck>(pCar); // 위처럼 대입하지 않고 스스로 형변환만 하여도 상관없음.// 참조 카운트는 당연히 변화가 없다. static_pointer_cast<Car>(pCar);
참조 객체 접근
명시적 방법
* shared_ptr::get() : 참조하고 있는 객체의 주소를 반환한다.
암시적 방법
* shared_ptr::operator* : 참조하고 있는 객체 자체를 반환한다. : 즉, *(get())의 의미 * shared_ptr::operator-> : get()->의 의미와 같다. shared_ptr<Car> spCar( new Truck() ); // spCar가 참조하는 객체의 주소를 반환 Car* pCar = spCar.get(); // spCar가 참조하는 객체의 메써드에 접근 #1 spCar.get()->MemberFunc(); // spCar가 참조하는 객체의 메써드에 접근 #2 *(spCar).MemberFunc(); // spCar가 참조하는 객체의 메써드에 접근 #3 spCar->MemberFunc();
순환참조
대부분 그룹객체 - 소속 객체간 상호참조에서 발생하며 소속객체가 그룹객체를 weak_ptr로 들고 있으면 해결된다. (아래 weak_ptr 참고)
멀티쓰레드 안정성
안전하지 않다. thread_safety는 동시에 읽을 경우에만 안전하고, 쓰기를 할 경우에는 안전하지 않다.
weak_ptr
앞에서 shared_ptr은 포인터가 가리키는 실제 메모리가 몇 번이나 복사되어 사용되는지 내부적으로 추적하기 위해 레퍼런스 카운팅 방식을 이용한다. 하지만, 이 레퍼런스 카운팅 방식의 잠재적인 위험 가운데 하나로 서로를 참조하는 순환참조 문제가 있다. A는 B를 가리키고, B는 다시 A를 가리키는 상황이 바로 순환참조 상황이다. 이런 상황에서는 순환참조에 참여하는 모든 인스턴스가 삭제될 수 없으며, 이는 곧장 메모리 누수로 이어진다. 이런 문제를 해결하는 포인터 타입이 weak_ptr 이다.
shared_ptr에서는 메모리를 참조하는 shared_ptr이 자신을 제외하고 하나라도 남아 있으면, 아무리 삭제 명령을 내려도 해당 메모리가 삭제되지 않는다. 그러나 해당 메모리를 가리키는 포인터 타입이 shared_ptr이 아닌, weak_ptr 이라면 해당 메모리는 삭제될수 있다. weak_ptr이 가리키는 메모리 공간은 shared_ptr이 메모리를 관리하려고 사용하는 레퍼런스 카운트에 포함되지 않기 때문디다. 즉, 순환참조가 일어날 수 없다.
사실 weak_ptr이 shared_ptr을 참조할 때 shared_ptr의 weak reference count는 증가시킨다. 객체의 생명 주기에 관여하는 strong reference count를 올리지 않는 것 뿐이다. (shared_ptr, weak_ptr 객체를 디버거로 살펴보면 strong/weak refCount가 따로 표시된다)
weak_ptr은 특정 메모리 번지를 참조하는 shared_ptr이 아직 존재하는지 여부를 확인해볼 때 사용 할 수 있다. weak_ptr이 shared_ptr을 가리키고 있을 때 shared_ptr이 해제되면 weak_ptr도 해제된다.
weak_ptr은 shared_ptr의 참조자라고 표현하는 것이 맞을 듯 하다. 같은 weak_ptr 또는 shared_ptr로부터만 복사 생성/대입 연산이 가능하며, shared_ptr로만 convert가 가능하다.
따라서, weak_ptr<_Ty>는 _Ty 포인터에 대해 직접 access가 불가능하며, (shared_ptr의 get() 메쏘드 같은 녀석이 아예 없다) _Ty 포인터에 엑세스를 원하면 lock 메써드를 통해 shared_ptr로 convert 한 뒤, shared_ptr의 get 메쏘드를 사용해야 한다.
그리고 expired 함수를 통해 자신이 참조하고 있는 shared_ptr의 상태(즉, weak_ptr의 상태)를 체크할 수 있다.
shared_ptr<_Ty> lock() const { // convert to shared_ptrreturn (shared_ptr<_Elem>(*this, false)); } boolexpired()const{ // return true if resource no longer existsreturn (this->_Expired()); }
순환참조 예제
순환참조의 대부분은 그룹객체 - 소속객체간 상호참조에서 발생한다.
#include<memory> // for shared_ptr#include<vector>usingnamespacestd; class User; typedefshared_ptr<User> UserPtr; class Party { public: Party() {} ~Party() { m_MemberList.clear(); } public: voidAddMember(const UserPtr& member){ m_MemberList.push_back(member); } voidRemoveMember(){ // 제거 코드 } private: typedefvector<UserPtr> MemberList; MemberList m_MemberList; }; typedefshared_ptr<Party> PartyPtr; typedef weak_ptr<Party> PartyWeakPtr; class User { public: voidSetParty(const PartyPtr& party){ m_Party = party; } voidLeaveParty(){ if (m_Party) { // shared_ptr로 convert 한 뒤, 파티에서 제거// 만약, Party 클래스의 RemoveMember가 이 User에 대해 먼저 수행되었으면,// m_Party는 expired 상태 PartyPtr partyPtr = m_Party.lock(); if (partyPtr) { partyPtr->RemoveMember(); } } } private: // PartyPtr m_Party; PartyWeakPtr m_Party; // weak_ptr을 사용함으로써, 상호 참조 회피 }; int _tmain(int argc, _TCHAR* argv[]) { // strong refCount = 1;PartyPtr party(new Party); for (int i = 0; i < 5; i++) { // 이 UserPtr user는 이 스코프 안에서 소멸되지만,// 아래 party->AddMember로 인해 이 스코프가 종료되어도 user의 refCount = 1UserPtr user(new User); party->AddMember(user); // weak_ptr로 참조하기에 party의 strong refCount = 1 user->SetParty(party); } // for 루프 이후 strong refCount = 1, weak refCount = 5// 여기에서 party.reset을 수행하면, strong refCount = 0// 즉, 파티가 소멸되고 그 과정에서 m_MemberList가 clear -> user들의 strong RefCount = 0 -> user 소멸// party와 5개의 user 모두 정상적으로 소멸 party.reset(); return0; }
C++11에선 (스마트 포인터)shared_ptr이 표준에 추가되었다. 이는 참조 카운팅을 추가하여 스마트 포인터간의 매끄러운 대입을 가능하게 하였다. 스마트포인터의 종류에 대한 설명은 다음 포스팅으로 미루고 여기에선 스마트포인터의 원리에 관해서 원론적인 이야기를 할까 한다.
내용에 들어가기 앞서 스마트 포인터에 관한 이해를 위해서는 다음과 같은 주제에 대한 이해가 필히 요구된다.
c++을 모른다면 생성자와 소멸자(파괴자)에 대해 생소하게 생각할 수 있다. 이 글은 c++에 관한 글이므로 c언어를 공부중이라면 그냥 이런게 있구나 하고 이해 정도는 해주자.
c언어에서 동적할당과 메모리 해제를 malloc/free 로 한다면 c++은 new/delete 가 있다. c++에서 모든 타입의 동적할당은 다음과 같은 표현으로 가능하다.
Type* A = new Type();
(c++에서는 구조체, 클래스도 하나의 타입으로 인정하고 위와 같이 동적할당을 할 수 있다.)
int형 포인터 변수 a는 메모리의 스택영역에 생성되었고 4의값을 가지는 int 타입의 데이타가 힙 영역에 할당된다. a포인터는 이 값을 가리킨다.
point클래스형 포인터 A도 스택영역에 할당되었고, 힙영역에는 실질적인 point객체가 생성되었다.
이 값들은 main 함수 영역내에서 생성된 것이며 프로그램이 종료될 때 메모리에서 해제가 되어야 한다. 위 예처럼 delete 구문을 주석처리를 해놓으면 main함수 종료 시 스택영역에 할당된 a,A 포인터만 메모리 해제가 되고 힙영역 데이타는 해제되지 않는다. 이렇게 힙영역에 할당된 메모리를 해제하지 않으면, 시스템에서는 아직 사용중으로 인식하여 이 부분의 메모리를 사용을 하지 않는다. 메모리누수(memory leak)의 원인인 것이다. 포인터와 동적할당 객체는 단지 주소값으로만 연결되어 있는 위태로운 상황이다. 포인터가 없어지면 실질적인 값만 남게 된다. 더 이상 사용되어지지 않는 실질적인 값을 가비지(garbage)라 불린다. 이 값은 하나의 사용 가능한 정보 데이타지만, 프로그램 입장에선 더 이상 의미없는 정보이고, 메모리 누수(memory leak)을 일으킨다.
자바의 유명한 가비지 컬렉션(garbage collection)은 이렇게 더 이상 사용되어지지 않는 메모리를 주기적으로 정리하는 기능입니다. 우리의 c++은 그딴 거 없습니다. 무조건 프로그래머의 몫입니다. 그런데,
힙영역에 동적할당된 메모리를 해제하기 위해선 delete만 쓰면 간단히 해결된다.
이렇게 간단하게 해결할 수 있는 문제에 굳이 스마트 포인터라는 것까지 등장하게 된 이유는 무엇일까?
첫째, 이런 메모리 누수는 프로그램에 치명적이지 않다. 물론 에러발생도 하지 않는다. 이런 이유로 이런 메모리 해제 작업을 소홀히 할 수 있다.
둘째, 예기치 않은 에러 등으로 프로그램이 종료될 경우 힙영역에 아직 가동중인 데이타의 해제가 제대로 일어나지 않을 수 있다. 또한 장기간 실행되어야 하는 서버 프로그램의 경우 작은 메모리 누수도 메모리 관리에 치명적으로 작용할 수 있다.
이런 문제점들을 개선하기 위해 스마트 포인터를 도입한 듯 하다.(이건 제 주관적인 견해입니다.)
스마트 포인터의 원리
다음은 이 원리를 이해하기 위한 내용이다.
1.함수내의 지역변수는 그 함수의 반환 시 같이 스택 내에서 해제된다.
2.객체의 경우 메모리에서 해제가 일어나면 파괴자(소멸자)를 호출하는데 파괴자(소멸자)의 기본 역할은 생성자가 생성한 메모리를 해제하는 역할을 한다. 생성자의 역할은 객체의 생성 시 멤버변수의 초기화를 담당한다.
다음은 스마트 포인터를 흉내낸 템플릿 클래스다.
모든 타입에 가능한 사용을 위해 템플릿으로 만들었고, 단순히 할당과 해제만 가능하도록 만들었다. int형 값 3이 동적 할당되어 smpt 클래스 객체인 test의 멤버 변수가 이 값을 가리키도록 초기화 되었다.(smpt 생성자가 동적할당된 객체의 포인터를 인수로 받아들인다.) 프로그램이 종료되고 main 함수 반환시 test 객체는 스택에서 해제된다. 객체가 메모리에서 해제될 때 파괴자(소멸자)는 자동으로 호출되므로 파괴자 내부에 delete p;가 작동하여 자동으로 동적 할당된 객체가 해제된다. 잘보면 test는 포인터가 아니다. 요점은 smpt 클래스의 객체 test변수는 스택에 할당된 값이므로 함수 리턴 시 자동으로 해제되고, 포인터가 아닌 객체 자체이므로 해제될 때 파괴자를 호출하여 delete p;를 언제나 호출한다는 것이다.
auto_ptr 의 정의(memory 헤더파일)
template <typename T> auto_ptr class {...}
auto_ptr의 사용
auto_ptr<T> test(new T(.,.))
그냥 사용법만 외우고 사용만 해도 상관은 없겠다. 그래도 이왕 살펴 봤으니 좀 더 깊게 살펴보려고 한다.
말은 스마트 포인터지만, 실제로 포인터는 아니다. 구체적으로 말하면, 포인터를 래핑한 포인터의 래퍼클래스라고 말 할 수 있다.
실제 포인터가 아닌 스택에 저장되는 객체 변수이므로 이를 이용하여 파괴자 호출을 통한 delete의 안정적인 호출을 할 수 있지만, 객체변수라서 생기는 문제점을 보완해야 한다.
다음 코드를 분석하여 문제점을 보완해 나가겠다.
x,y좌표값을 멤버변수로 갖는 point 클래스를 선언하고 포인터 클래스로 객체를 생성하여 좌표값을 출력하려 하였다. 다음과 같은 컴파일 에러가 발생한다.
스마트 포인터의 목적은 달성하였지만, 주석처리된 코드처럼 사용하려면 연산자에 대한 오버로딩이 필요하다. 실제로 a는 point클래스의 포인터가 아닌 래퍼 클래스 객체변수이기 때문이다.
TR1라이브러리에는 STL의 auto_ptr과 비슷한 스마트 포인터가 있다 바로 shared_ptr다. 이것은 템플릿 클래스 형태로 특정한 자료형 형식을 지정해 줄 경우 그 자료형을 가리킬수 있는 포인터를 말한다. 예를 들어 int형를 가리키는 포인터를 만들기 위해 보통 다음과 같이 " int * "을 쓸 것이다. 하지만 이런 보통 포인터에 메모리를 힙 영역에 할당 하는 경우 반드시 delete하지 않으면 프로그램상에서 메모리 릭이 발생하게 된다.
int *p = new int(3) 사용후 반드시 delete p;
경험이 있는 프로그래머라면 이런 위험 요소들을 잘 처리하는 것에대한 중요성을 잘 알고 있을 것이다. 아무리 조심을 한다고는 하지만 프로그래머 또한 인간이기에 가끔 이런 실수를 할 수도 있다. 이런 메모리 릭은 에러가 아니기때문에 컴파일러에서 걸를수도 없고 발견하기도 어렵다.
이런것들을 막기위해 TR1라이브러리에서는 shared_ptr이라는 것이 존재한다. 이 포인터는 스마트 포인터의 일종으로서 메모리 해제하는 작업을 포인터 자체가 알아서 해주는 기능이 숨어 있다. 이외에 reference counter(참조횟수)도 관리하고 있어서 shared_ptr객체를 복사하면 참조횟수가 증가하고, shared_ptr객체를 파괴하면 참조횟수는 감소 한다. 이렇게 해서 reference counter가 0 이되는 순가 shared_ptr가 소유하고 있는 자료형의 자원(메모리)는 자동 해제 되게된다. 사용 예는 다음과 같다
shared_ptr<int> sp(new int());
위는 힙 영역에 int형 만큼 할당된 메모리공간을 가리키고 있는 int형의 shared_ptr객체의 선언이다. shared_ptr의 객체인 sp는 'int*'와 같이 '->'연산자나 '*'연산자를 통해 메모리 공간에 접근이 가능하고 따로 메모리해제를 할 필요 없이 shared_ptr 객체가 소멸되는 순간 메모리는 자동 해제하게 된다.
shared_ptr의 사용예
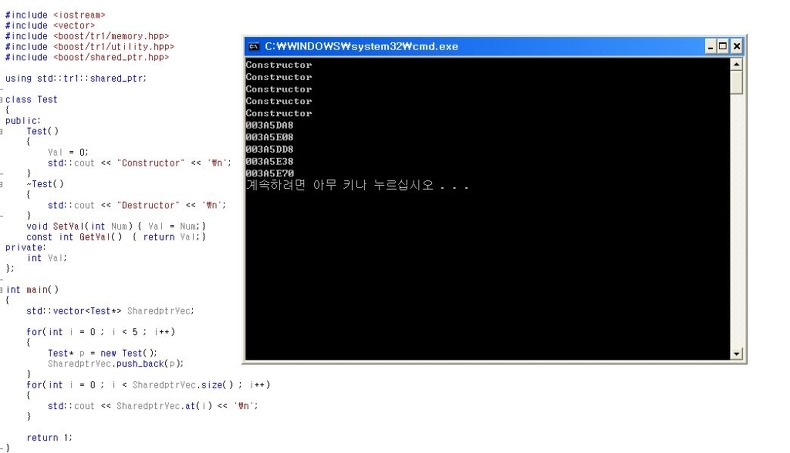
흔히 망각하기 쉬운 예로 shared_ptr의 강점을 알아보도록 하겠다. 흔히 STL의 vector컨테이너에 특정 자료형에 대한 포인터를 넣어서 사용하는 경우가 있다. 이런 경우 shared_ptr를 vector와 함께 사용할 경우 꽤 편리 할 수 있다. 다음의 예를 보자.
위의 경우 흔히 하기 쉬운 실수중에 하나로 vector에 pushback할때 하나의 Test의 객체를 생성해서 그 객체의 포인터를 벡터에 넣고 있다. 하지만 이는 프로그램이 끝나는 시점에서 각 컨테이너 요소의 포인터들을 직접 메모리 해제 하지 않는 경우 위의 실행 창과 같이 생성자만 불리고 소멸자는 불리지 않게 되는 문제점이 있다.
그렇다면 vector가 포인터를 가지고 있는것이 아니라 객체를 가지고 있다면 어떻게 될까?
위의 보기는 생성자와 소멸자가 정신없게 불린 상황이다. 객체의 생성은 이 전의 예와 같이 동적으로 메모리를 할당해 생성하였지만 객체의 포인터가 아닌 포인터가 가리키고 있는 객체자체를 벡터에 넣고 있다. pushback하는 동안 STL자체는 call by value에 의해 복사가 되므로 클래스 내에 복사생성자가 잘 구현되어야 있어야 복사가 깊은 복사로 잘 이뤄지며 pushback을 하는 동안 벡터내의 insert과정에서 소멸자가 불리게 되어 각 루프를 돌때마가 소멸자가 그 숫자에 맞게 불리게 된다. 그리고 마지막으로 벡터 객체가 소멸하는 순간 객체에 대한 소멸자를 자동으로 불러 다시 한번 소멸자가 불리게 되어 위와 같이 어지럽게 생성과 소멸이 반복되고 있다.
그렇다면 shared_ptr를 사용한 벡터는 어떤 모습일까?
shared_ptr를 객체로 가지고 있는 벡터 컨테이너의 객체의 경우는 메모리 해제작업을 shared_ptr자체가 하기 때문에 프로그램이 끝나는 부분에서 메모리 해제 작업을 깜박하고 하지 않는다 하더라도 자동적으로 메모리가 해제되게 된다. 그로인해 위와 같이 깔끔하게 생성자 5번 소멸자 5번 씩 짝을 이루며 메모리 릭이 방지되는 것이다. 이처럼 포인터를 벡터에 담는 경우는 가급적 shared_ptr을 사용한다면 메모리릭 방지에 많은 도움이 될 것이다.
그래서 스마트 포인터를 사용을 아에 안하거나 boost 라이브러리의 스마트 포인터를 사용했었다. (shared_ptr)
auto_ptr에서 소유권 문제가 발생하는 이유는
복사 생성자와 할당 연산자 구현이 멤버 데이터에 대한 깊은 복사 대신 얕은 복사를 하도록 되어 있기 때문이다.
그래서 함수안으로 온전한 auto_ptr이 전달되지 않으며 auto_ptr을 전달하면 복사 생성자가 호출되고 그 결과 얕은 복사가 발생하기 때문이다. (얕은 복사와 깊은 복사의 개념을 잘 모르면 공부를 해야 한다.)
하지만 이런 auto_ptr도 문제점 투성이인 것 만은 아니고 얕은 복사를 하는 특성 덕택에 특정 순간 객체의 소유권이 유일하게 하나의 auto_ptr 객체에만 존재하게 되었다.
하지만 auto_ptr 객체 자체는 복사가 필요한 곳에 사용을 할 수 없다는 모든 장점을 다 가리는 단점이 존재해서 새로운 스마트 포인터가 대두되기 시작했다.
기존의 C++ 표준은 복사 생성자나 할당 연산자를 통해 Copy Semantics 를 지원했다. (Copy Semantics, Move Semantics를 모르는 먼저 Copy Semantics를 공부하길 .. Move Semantics는 앞으로 계속 알아갈 예정)
이는 사용자가 클래스안에 복사 생성자나 할당 연산자를 별도로 구현하지 않아도 언어 차원에서 시본으로 지원해주는 객체 복사의 개념이다. 해당 객체가 클래스 멤버로 포인터 타입의 데이터를 갖는 경우라면, 컴파일러가 만들어내는 복사 생성자와 할당 연산자에 의지하는 대신, 프로그래머가 직접 구현하여 컴파일러에 의해 생성되는 복사 생성자와 할당 연산자를 오버로딩 해야한다고 알고 있을텐데, 그 이유는 앞에서도 언급한 바와 같이 얕은 복사의 문제를 극복하려는 방법이다.
새로운 C++ 11 표준에서는 Copy Semantics에 추가로 새로운 개념인 Move Semantics가 등장하였다.
Move Semantics는 Copy Semantics 처럼 두 객체 사이에 복사를 수행하는 대신 객체의 데이터 필드 하나 하나를 이전 시키는 역할을 수행 했음. (Move Semantics를 자세히 언급안하는 이유는 언급하게되면 끝이 없기 때문에 위에도 말했다시피 천천히 알아 갈 것임)
어떤 객체를 생성해야 할 때는 일반적으로 클래스의 생성자를 호출해 만드는데, 때로는 이미 만들어진 객체의 복사는 할당을 통해서 새로운 객체를 만들기도 한다. 다른 예로 STL의 백터나 리스트와 같은 컨테이너의 경우 이들은 일종의 동적 배열이기 때문에 그 크기가 상황에 따라 두 배씩 늘어나게 된다.
이때 메모리 내부에서는 대량의 복사가 발생한다. 그런데 STL 컨테이너에서의 문제는 복사후 원본과 사본 모두를 사용하는게 아니라 원본 파괴하고 사본만 사용함.
단지 배열의 크기를 늘리기 위해 불필요한 복사 동작을 하여 오버헤드를 내게되는데, 이로인해 쓸데없는 객체를 생성하거나 사용하지 않는 원본 객체를 파괴한다는 점 등 이런 일련의 불필요한 동작은 C++ 성능저하의 주범이라는 고질적인 문제점이 있었음.
그래서 이를 위해서 복사보다는 이동이 낫겠다고 판단하여 Move Semantics를 도입하게 됨.
이를 위해 이동 생성자 라는 개념을 도입함.
그래도 문제가 남아 있었는데, Move Semantics 라는 개념을 스마트 포인터에도 적용하려니 auto_ptr의 내부 구현이 이동 시맨틱을 지원할 수 있도록 업그레이드 하기엔 기술적 제약이 걸려있고 이미 사용되던 기존 auto_ptr에 대한 호환성을 해칠수도 없었기 때문에 unique_ptr이라는 이름의 새로운 단일 포인터 타입을 구현하게 됨.
C++ 11 에서는 auto_ptr은 deprecated 됨
unique_ptr 내부에는 복사 생성자와 할당 연산자가 아에 구현되어 있지 않는다.
따라서 우리가 기존에 알던 복사 생성자나 할당 연산자를 작성하지 않아도 컴파일러가 이를 기본적으로 제공 안해준다.
Shared_ptr은 Reference Counting 기법으로 인해 실제 메모리가 몇번이나 복사되어 사용되는지 내부적으로 추적하기위해 레퍼런스 카운팅 방식을 이용했다. 하지만 이 레퍼런스 카운팅의 잠재적인 위험 가운데 하나로 서로를 참조하는 순환참조 (Circular Reference -> A는 B를 가리키고 B는 A를 가리키는 상황) 가 될 위험이 있기 때문에 이런 상황에서 순환 참조에 참여하는 모든 인스턴스가 삭제될 수 있으며, 이는 곧장 메모리 누수로 이어지는 괴랄한 상황이 발생하게 된다.
바로 이런 Shared_ptr의 문제를 해결하는 것이 Weak_ptr 이다.
Shared_ptr 에서는 메모리를 참조하는 Shared_ptr이 자신을 제외하고 하나라도 남아 있으면, 아무리 삭제 명령을 내려도 해당 메모리가 삭제되지 않는다. 해당 메모리를 가리키는 포인터 타입이 Shared_ptr이 아닌 weak_ptr이면 해당 메모리 삭제가 가능하다.
weak_ptr이 가리키는 메모리 공간은 shared_ptr이 메모리를 관리하려고 사용하는 레퍼런스 카운트에 포함되어있지 않기때문에 순환 참조가 일어날 수 없다.
std::weak_ptr<int> wp1 = sp1; // Weak_ptr 포인터 변수 생성해 sp1을 참조한다. (wp1도 sp1과 같이 18번지 가리키지만 18번지 소유권은 sp1에게 있음)
{
std::shared_ptr<int> sp2 = wp1.lock(); // SP1은 SP1으로 SP2를 복사한다. 약한 포인터의 멤버 함수 lock()을 이용해 wp1이 가리키던 공유 포인터를 반환하도록 하고, 이를 새로운 공유 포인터인 sp2가 받는다.
// 이제 18은 sp1과 sp2의 공동 소유이며 레퍼런스 카운트는 2가 된다.
if(sp2)
{
std::cout << "sp2 has copy of sp1" << std::endl; // sp2가 있으므로 출력 구문 실행
}
} // sp2는 범위 연산자({}) 를 만나는 순간 sp2는 생성된 범위를 벗어나게 된다. 스마트 포인터이므로 명시적으로 delete를 호출해 줄 필요가 없다. 이제 sp2가 파괴됨으로써 레퍼런스 카운트는 -1이 되어 1이 되었다.
sp1.reset(); // sp1은 이곳에서 파괴한다. 여기서 Reference Count가 2면 -1을 시키고, 1이면 -1을 하여 0이된다. 0이 되면 메모리를 해제하게 되고 18번지는 이제 아무도 소유하지 않는다.
std::shared_ptr<int> sp3 = wp1.lock(); // wp1이 가리키던 공유 포인터를 반환하여 sp3에 복사한다. 하지만 약한 포인터의 특징상 자신이 가리키던 공유 포인터의 리소스가 파괴되면 자신도 자동으로 파괴되는 특징이 있으므로 lock 멤버 함수를 호출하면 빈 shared_ptr이 반환된다.
if (sp3)
{
std::cout << "sp3 has copy of sp1" << std::endl; // sp3는 위에서 sp1을 reset 해줌으로써 레퍼런스 카운트가 0 이므로 자동해제되어 있기 때문에 출력이 되지 않는다.
}
return 0;
}
이제 멀티 쓰레드를 생각하는 사람이라면 동시성 문제를 생각을 하게 될 것이다.
하지만 shared_ptr과 Weak_ptr는 레퍼런스 카운팅 방식이므로 안전하게 사용할 수 있다.
단 안전하게 사용할 수 있는 경우는 각 쓰레드가 내부적으로 각각 공유 포인터가 있고 공유포인터가 동일한 리소스에 접근하는 경우이다.
하지만 각 쓰레드가 쓰레드 외부에 있는 하나의 shared_ptr 객체에 접근한다면 C++11이 제공하는 다른 원자 함수들을 사용해야한다.
이 책에서는 자원을 동적으로 할당된 객체에 대해서만 한정해 설명을 하고 있는데, 예를 들어 Widget* p = new Widget(); 와 같은 코드에서 p 자체를 자원이라고 부르고 있습니다. C++은 delete로 자원을 반납하는 특성을 가집니다. 동적으로 할당된 자원을 delete로 반납하지 않으면 메모리 누수가 일어나죠. 애초에 작성할 때 new로 할당을 하고 이어서 delete를 해주고 그 사이에 코드를 작성하게 되는데, 이 사이에 들어가는 코드가 return 문을 가지고 있는 경우에 delete문을 호출해 주지 않기 때문에 마지막에서 delete를 해준다고 해도 중간에 함수가 끝나서 메모리 누수가 발생합니다. 만약 이런 코드가 루프 문에 들어가 있다고 해봅시다.
루프문은 break이나 continue를 이용해서 루프를 제어하게 되는데 이런 제어 코드 때문에 위 경우와 마찬가지로 delete가 실행이 되지 않고 메모리 누수가 일어 날 수 있습니다. 만약 이런 상황을 막기 위해서는 제어 코드 이전에 delete를 해주면 되지만, 이런 코드 들이 여러개 존재하고 이런 일들을 일일이 해준다고 한다면 번거롭기도 하고, 자원관리에 어려움이 있습니다. 이런 자원을 사용자가 직접 할당 받고 반납하는 과정을 다 염두에 두고 코딩을 해야 하는 것이 프로그래머에게 부담이 되고 문제가 됩니다. 그래서 이펙티브 C++에서는 자원을 사용자가 직접 해제 하지 말고, 자원 관리 객체를 이용해 그 자원관리 객체가 소멸할때 소멸자에서 자원을 소멸하도록 이용하라고 되어 있습니다.
auto_ptr
자원관리 객체는 주로 스마트 포인터를 이용하는데, 스마트 포인터 중에 첫번째로는 Auto Pointer가 있습니다. 이것은 memory 헤더 안에 선언이 되어 있어 사용할때는 헤더를 선언해주고 사용해줘야 합니다.
위와 같이 auto_ptr을 사용하면 예전처럼 동적 할당후 자원 반납을 해주지 않아도 자기 객체가 사라질때 소멸자에서 자원의 delete를 적용해줘서 결과적으로 delete를 안써줘도 되게 만들어져 있습니다. 여기 코드에서는 할당받은 자원을 자원 관리 객체 p에다가 넘기고 있는데, 자원관리 객체의 초기화 코드에 할당받은 자원을 넘기는 것을 "자원획득 초기화(RAII)" 라고 합니다.즉, 자원관리 객체 p가 있고 p의 초기화로 자원을 넘겨서 그 p가 소멸이 될때 그때 delete를 해주게 되는 방식이죠.
이제 return과 같은 제어코드나 다른 상황에서도 이 p는 지역변수 와 똑같이 동작을 해서 루프를 빠져나와 함수를 빠져나갈때 delete를 호출해 주기 때문에 자원누수를 막을 수 있습니다. 그러니까 자원해제를 사용자가 하는게 아니라 자원 관리 객체 라는 객체가 관리를 해주니까 누수에 대한 걱정을 하지 않아도 되는 것입니다.
그런데 auto_ptr에는 아래와 같은 문제가 일어날 수 있을 것이라고 생각할 수 있을것입니다.
위와 같이 auto_ptr을 복사를 하게 되면 똑같은 자원에 대해 두 자원관리 객체가 생기게 되는 꼴이 되는데, 이놈의 소멸자가 자원에 대한 delete를 해주게 되니까 같은 자원을 두번 해제하게 되는 일이 발생할 수도 있을 거라 예상이 될 것입니다. 그래서 auto_ptr은 그런것을 막기 위해서 소유권을 넘긴다는 방식을 취하고 있다.
소유권을 넘긴다? 소유권을 넘긴다는 의미는 기존의 자원은 null로 바꿔 버리고 새로 복사된 객체(이전에 있던 자원을) 유지하는 방식으로 동작을 합니다.
C++에서도 'delete NULL' 해도 정상적으로 작동을 하므로 표준에 어긋난 것은 아닙니다. 여기에서 p2가 먼저 소멸 되는데, 그때 자원이 반납되고, p는 null이기 때문에 어떤 동작도 안하게 되므로, 자원 관리 객체의 복사 문제 해결하고 있습니다. 물론 복사대입 연산자도 이런 처리가 되어 있습니다. 하지만 문제가 있습니다.
위 소스 코드를 실행해보면, p2는 지금 자원을 가지고 있기 때문에 정상적으로 호출되는데 p는 p2의 자원을 넘겨주고 자신은 null로 바뀌었기 때문에 null에 대해서 멤버 함수를 호출하는 동작을 취하면 프로그램이 이 부분에서 뻗게 되는 것입니다. 기존 동작의 포인터와 다른 복사 동작을 가지고 있는것이 오토 포인터의 특징이라고 할 수 있습니다.
하지만 이런 auto_ptr은 특성 때문에 STL의 컨테이너나 같은 곳에 같이 사용하면 문제가 발생하는 경우가 생길 수 있습니다. 그래서 우리가 일반적인 포인터를 사용할때처럼, 복사는 자유로우면서, 소멸 또한 관리가 되는 또 다른 자원관리 객체의 필요성이 대두 됩니다. 그래서 나타난것이 shared_ptr입니다.
shared_ptr
: shared_ptr은 참조 카운팅 방식 스마트 포인터(reference-counting smart pointer) 중의 하나로서, 원래는 Boost Library에 있다가 C++의 새로운 표준인 tr1이라는 이름공간에 추가되었습니다.
shared_ptr은 내부적으로 카운팅을 유지 해서(참조 갯수를 유지 해서) 자원의 참조 갯수를 셉니다. 처음 생성했을 때는 한개가 되고, 그 다음에는 두개가 되는 식으로 말이죠. shared_ptr는 참조 갯수만 관리 하기 때문에 위 소스코드가 무리없이 동작 되는 것을 알 수 있습니다. 그리고 shared_ptr도 마찬가지로 소멸시 delete를 호출해주는데 이 점때문에, 복사동작이 많이 요구되고 동시에 자원이 관리 되어야 하는 상황에서는 auto_ptr 보다 shared_ptr이 더 적합합니다. 그런데 문제는 자원이 동적으로 하나만 생성된것이 아니라, 아래와 같이 동적 배열로 생성된 경우는 shared_ptr은 스스로 판단을 할 수 없다는 것이 문제점 입니다.
auto_ptr과 마찬가지로 shared_ptr도 delete 를 호출합니다. 하지만 위와 같이 동적 배열로 생성된 경우에는 delete[]로 호출해서 소멸시켜야 하는데, 그냥 delete만 호출 하는 할당과 반납의 형태가 다르다는 문제가 생기는 것입니다. 그래서 이런 경우는 STL의 벡터(vector) 같은 컨테이너와 같이 조합을 해서 이용하는 것을 추천합니다.
지금과 같은 상황에서 빈삭제자를 쓴다면 메모리 누수가 생길텐데, 이 빈삭제자의 활용법은 자기 자신의 객체를 외부로 반환하는 함수가 있다고 할때, std::tr1::shared_ptr<Widget> getThis() {return std::tr1::shared_ptr<Widget>(this);}
위와 같이 작성하면, this가 자원관리 객체로 넘어가면서 반환하게 되는데 shared_ptr의 기본 동작이 delete를 호출해주기 때문에, 지금같은 경우 this를 delete하면 문제가 생길것입니다. 그래서 여기서 빈삭제자를 넣어 이런 삭제를 막는 것입니다.
끝으로 shared_ptr 같이 타입이름이 너무 기니까 typedef를 쓰게 되는데 실제로 많이 쓰는 방법은 어떤 타입에 대한 shared_ptr 포인터 타입을 만들기 위해 위에서 전방 선언만 해주고 (컴파일러에게 이름을 알려준다.) 그 이름을 shared_ptr 포인터에 넘겨 새로운 타입을 만들어서 사용하면 이런 선언에 대한 이름길이의 부담을 줄일 수 있습니다.
지금까지 자원관리에 대해 auto_ptr과 shared_ptr에 대해서 알아봤는데요, 사용자는 자원을 언제든지 놓칠 수 있기 때문에, delete를 언제나 챙길 수 없습니다. 그래서 이것을 자원관리 객체라는 또 다른 객체에 넘겨서 관리를 하자는게 이번 항목의 목적이라고 할 수 있습니다.
* 자원 누출을 막기 위해, 생성자 안에서 자원을 획득하고 소멸자에서 그것을 해제하는 RAII 객체를 사용합시다.
* 일반적으로 널리 쓰이는 RAII 클래스는 tr1::shared_ptr 그리고 auto_ptr입니다. 이 둘 가운데 tr1::shared_ptr이 복사 시의 동작이 직관적이기 때문에 대개 더 좋습니다. 반면, auto_ptr은 복사되는 객체(원본 객체)를 null로 만들어 버립니다.
make 함수중 std::make_shared와 std::make_unique를 살펴보겠습니다.
세번째 make 함수는 std::allocate_shared 입니다.
이 make 함수는 std::make_shared처럼 작동 하는데 함수의 첫 번째 매개변수
가 동적으로 할당 될 객체의 Allocator가 된다는 점만 다릅니다.
make 함수를 사용해서 스마트 포인터를 만드는 것이
더 좋은 이유
autoupw1(std::make_unique<Widget>()); // make 함수 사용 std::unique_ptr<Widget> upw2(new Widget); // make 함수 비사용autospw1(std::make_shared<Widget>()); // make 함수 사용 std::shared_ptr<Widget> spw2(new Widget); // make 함수 비사용
make 함수를 사용하는 첫 번째 이점은 make 함수가 new를 사용하지 않
는다는 점입니다.
make 함수를 사용하지 않을 때 Widget이라는 type이 2번 등장하고 있습
니다. 이는 중복되는 코드를 피하자는 소프트웨어 엔지니어링의 중요 견해
와 충돌하게 되는 지점입니다. 중복 코드가 나타났을 때 생기는 컴파일 타임
의 증가, 코드량의 증가, 일치하지 않는 코드가 나타나 생길 수 있는 버그등
의 문제 때문에 make 함수는 선호 됩니다.
두 번째 차이는 make 함수가 exception safety 하게 작업이 이루어진다는
것입니다.
다음의 예를 통해서 위 내용을 살펴보도록 하겠습니다.
우선순위를 가지고 Widget 객체를 처리하는 함수가 입니다.
voidprocessWidget(std::shared_ptr<Widget> spw, int priority);
std::make_shared 함수가 Widget 포인터를 가지고 있는 shared_ptr을
반환하므로 위에서 1-2번이 한꺼번에 처리됩니다. 따라서 처리 순서로 인한
문제가 발생하지 않습니다.
std::make_shared는 컴파일러에 의해 더 작고 빠른 코드로 만들어집니다.
이 때 더 날씬한 구조체를 사용하기 때문입니다.
new를 사용하는 다음과 같은 코드가 있습니다.
std::shared_ptr<Widget> spw(new Widget);
여기서는 총 2번의 메모리 할당이 일어납니다. 눈에 보이는 new로 인한
Widget의 할당과 눈에 보이지 않는 control Block의 할당이 그것입니다.
std::make_shared를 사용하는 예를 보겠습니다.
auto spw = std::make_shared<Widget>();
여기서는 1번의 메모리 할당이 일어납니다. std::make_shared를 사용하면
Widget에 대한 할당과 control Block의 할당을 한 번에 처리합니다.
따라서 실행 코드의 속도를 높입니다.
make 함수를 사용하지 말아야 할 때
1. 삭제자를 지정하려고 할 때
make 함수는 삭제자를 지정할 방법이 없습니다.
2. std::initializer_list를 매개변수로 갖는 생성자가 오버로드 되어 있는 클래스
auto upv = std::make_unique<std::vector<int>>(10, 20); auto spv = std::make_shared<std::vector<int>>(10, 20); // std::make_shared<std::vector<int>>{10,20}; 은 애당초 컴파일이 안됨// make_shared는 중괄호를 지원하지 않음
위의 예에서 upv와 spv는 값이 20인 원소 10개짜리 벡터를 갖는 스마트 포인
터가 된다. 따라서 중괄호 초기화한 값을 가지고 작업을 하고 싶다면 new를 사
용해야 합니다. make함수를 사용할 수 없는 것입니다.
하지만 auto 타입을 사용하면 이를 극복할 수 있습니다.
auto initList = { 10, 20 }; // auto를 통해 std::initializer_list 생성자를 사용하기// make 함수와 중괄호 초기화를 같이 사용할 수 있게 되었다auto spv = std::make_shared<std::vector<int>>(initList);
3. std::make_shared를 사용하지 말아야 할 때
이 부분은 std::make_shared만 연관이 있습니다.
사용자가 어떤 클래스에서 new와 delete를 새롭게 정의 했을 때
사용자는 종종 new가 정확히 클래스 사이즈 만큼의 크기만큼만 메모리 할당을
하게 합니다. 이는 만약 Widget 클래스에 대한 new를 새롭게 정의했을 때
`sizeof(Widget)만큼의 크기`만 new를 통해 할당되는 상황을 말합니다.
이 때 std::make_shared 함수를 사용하면 문제가 발생할 수 있습니다.
왜냐면 실제로 control blcok의 크기만큼의 메모리 공간이 더 필요하기 때문입
니다. std::make_shared 함수 내부에서는 전달된 타입의 객체으로 만들 수 있
는 객체와 control block을 동시에 메모리 할당 합니다. 따라서 custom 메모리
할당자는 이 작업에 영향을 미칠 수 있습니다. 원하는 크기보다 control block
만큼 크기가 빠진 채로 할당 될 수 있습니다.
4. std::make_shared가 가리키는 오브젝트의 메모리 해제 시기
shared_ptr와 관련된 정보를 담는 control block에 대해서 이전 Item에서 다루었
습니다. control block에는 몇 개의 std::shared_ptr이 해당 객체를 가리키는지
알려주는 참조 카운트와 몇 개의 std::weak_ptr이 해당 객체를 가리키는지 알려
주는 참조 카운트에 대한 정보가 있습니다. 전자를 참조 카운트 후자를 weak
카운트라 하겠습니다. 참조 카운트가 0 이 되면 연관되어 있는 weak_ptr의
expired 함수를 통해서 확인할 수 있습니다.
여기까지 앞 item에서 다룬 내용이었습니다. 이번에 이야기 할 것은 make 함수
를 통해 가리키고 있는 객체와 shared_ptr을 통해 가리키고 있는 객체의 메모리
해제 시기가 다르다는 점입니다.
std::shared_ptr에 new로 만들어진 객체를 참조할 때 control block을 만듭니다.
그러면 new로 만들어진 객체에 할당된 메모리와 control block에 할당된
메모리는 따로 관리 됩니다. std::shared_ptr의 참조 카운트가 0이 될 때
new로 만들어진 객체는 소멸자가 불리고 -> 메모리가 해제 됩니다. 후에
weak_ptr이 0이 되면 control block에 대한 메모리도 해제 됩니다.
하지만
std::make_ptr<T>는 내부에서 new T를 하고 control block과 메모리를 함께
관리 합니다. 즉 참조 카운트가 0이 되어도 T에 대한 메모리가 해제 되지 않
습니다. weak 카운트가 0이 되면 control block의 메모리와 T에 대한 메모리가
함께 해제 됩니다.
이를 다음의 예제를 통해 다시 알아보겠습니다.
// 매우 큰 타입, 메모리를 많이 차지한다고 하자classReallyBigType { … }; // new를 통해 객체를 할당하고 이를 가리키는 스마트 포인터 생성 std::shared_ptr<ReallyBigType> pBigObj(new ReallyBigType); ... // std::shared_ptr을 여러 개 사용, std::weak_ptr을 여러 개 사용 ... // 마지막 std::shared_ptr이 파괴됨, 아직 std::weak_ptr을 남아 있음// 이 시점에 new로 할당한 객체는 소멸자가 불리고 메모리 해제 ... // 이 기간동안 control block만 할당된 상태 ... // 마지막 std::weak_ptr도 더 이상 객체를 가리키지 않으면 control block 메모리 해제//
// std::make_shared 함수 통해 스마트 포인터 만듦// 내부적으로 타입 인자로 넘어온 객체를 할당함auto pBigObj = std::make_shared<ReallyBigType>(); ... // std::shared_ptr을 여러 개 사용, std::weak_ptr을 여러 개 사용 ... // 마지막 std::shared_ptr이 파괴됨, 아직 std::weak_ptr을 남아 있음// 할당된 객체의 소멸자 호출 하지만 메모리는 해제하지 않음// 이 시점에 아무것도 메모리 해제 되지 않음 ... // 이 기간동안 참조하고 있는 std::shared_ptr이 없는데도 // 매우 큰 메모리가 할당되어 있음 ... // 마지막 std::weak_ptr이 파괴되면 control block과 할당된 객체 동시에 메모리 해제
이렇게 std::make_shared의 단점 때문에 std::make_shraed를 사용할 수 없는
상황이라면 Scott Meyers가 추천하는 스마트 포인터 사용방식은 아래와 같습
니다.
// shared_ptr이 먼저 객체를 가리키고 있게 한다// new와 함수를 한 인자로 넘기면서 생기는 예외상황을 피할 수 있다 std::shared_ptr<Widget> spw(new Widget, cusDel); processWidget(std::move(spw), computePriority()); // std::move를 통해서 스마트 포인터를 전달한다// std::move가 아닌 값에 의한 전달이었다면// 참조 카운트를 증가시킨다. // 하지만 std::move는 참조카운트를 증가시키지 않고// 복사하는데 드는 비용도 생기지 않는다.
기억할 점
make 함수는 코드의 중복을 막고, 예외에도 안전하며, 빠릅니다
make 함수가 어울리지 않는 상황도 있습니다
std::make_shared와 std::shared_ptr의 메모리 관리 정책을 알아야 합니다
#if 0 int main() { Car *p = new Car; delete p; } #endif
int main() { // shared_ptr<Car> p = new Car; // ERROR. explicit 생성자는 =로 할당 불가능 shared_ptr<Car> p(new Car); // OK. 생성자가 explicit 생성자 이기 때문이다. // shared_ptr<Car>는 객체다. 포인터는 아니다. p->Go(); // 그럼에도 p에 ->를 붙여 포인터처럼 쓰는 것은 -> operator를 재정의 한것이다. // 스콥이 나가면 Car는 destroy 된다. 때문에 delete 불필요. 게임 업체에서는 진짜 포인터 안씀. return 0; }
#include "show.h" #include <memory> /* 스마트 포인터 C/C++에서는 new는 한곳이지만, delete는 여러 곳에 존재. 아이디어 : 포인터는 블럭 벗어나도 사라지지 않지만, [객체]는 블럭 벗어날 때 자동 delete된다.
int main() { // 아래 코드가 실행되면 메모리 할당이 몇번 일어 날까요 ? shared_ptr<Car> p1(new Car);
1. HEAP : new Car에 의해서 한번 발생 (new 1회) 2. STACK : p1은 stack에 생김. 3. HEAP : [참조 개수] + 알파를 관리하기 위한 관리 객체가 따로 만들어짐. (new 1회) > 1과 3 각각 1회씩 2회의 new가 발생함. > 3때매 파편화 문제 발생. > 대응 방법으로, 1에 붙여서 3을 할당 받는 방법 생각 가능.
} */
int main() { shared_ptr<Car> p1(new Car); // new : 4 원본객체 // new : 16 참조개수관리객체
// sizeof(Car) + sizeof(참조개수관리객체) 크기를 한번에 메모리 할당. // shared_ptr 쓴다면 반드시 make_shared 써야 한다 ! shared_ptr<Car> p2 = make_shared<Car>(10); // 이번에는 new가 전체 1회만 발생 함. // new : 16 원본객체+참조개수관리객체
/* make_shared<>로 (1) 원본객체(4바이트)와 (2) 참조개수관리객체(16바이트)를 합쳤음에도 20바이트가 아닌 16바이트인 것은 원래 참조개수관리객체가 별도로 존재할 때 크기 16바이트 중 4바이트는 원본객체에 대한 포인터임. 그런데 참조개수관리객체가 원본객체 끝에 달라붙으면서 그 4바이트가 필요 없게 됨. 그래서 참조개수관리의 크기는 12바이트가 되고, 원본객체의 크기(int color 4바이트)를 더해서 16바이트가 됨. */ }
shared_ptr<FILE> p5(fopen("a.txt", "wt"), fclose); // 삭제자를 fclose로 제공. 인자가 1개 이상이면, bind를 사용할 수 있다.
//shared_ptr<포인터 뺀타입> p(포인터 타입); 이어야 하는데, // 아래와 같이 HANDLE도 포인터 타입일 때 처리 방법. HANDLE h = CreateEvent(0, 0, 0, 0); CloseHandle(h); shared_ptr<remove_pointer<HANDLE>::type> h2(CreateEvent(0, 0, 0, 0), CloseHandle);
// 현재는 삭제자를 쓸 때는 make_shared<>를 못 씀 ! // make_shared<> 사용시 삭제자 변경 불가능. 이후 표준에서 논의 중. 표준 위원회에 요구 사항 많음. #if 0 int *p1 = new int; delete p1;
int *p2 = new int[10]; delete p2; // C++ 표준에는 new -> delete, new [] -> delete[]만 써 있음. 그외에는 정의 안되어 있음. 그것은 컴파일러 따라 다름. "undefined" 항목. // 때문에 new [] -> delete는 쓰면 안됨. #endif
}
#include "show.h" #include <memory>
// 중요 예제... // 참조계수 스마트 포인터가 상호 참조가 발생하면 메모리 누수 발생 함. struct Node { int data; // Node* next; // 스마트 포인터를 쓰기로 했으면, 일반 포인터와 스마트를 섞는것보다, 모두 스마트로 하는게 좋다. shared_ptr<Node> next;
~Node() { cout << "Node파괴" << endl; } };
/* 스마트 포인터를 쓰기로 했으면, 일반 포인터와 스마트를 섞는것보다, 모두 스마트로 하는게 좋다.
// 스마트 포인터를 써도, 아래 경우 Node가 파괴가 안됨. // [상호 참조]가 일어나면 메모리 해지가 안되어 [메모리 누수] 발생 함. p1->next = p2; p2->next = p1; } #endif
struct Node2 { int data; // Node* next; // 스마트 포인터를 쓰기로 했으면, 일반 포인터와 스마트를 섞는것보다, 모두 스마트로 하는게 좋다. weak_ptr<Node2> next;
~Node2() { cout << "Node2파괴" << endl; } };
// 해결책으로, 참조개수가 증가되지 않는 스마트 포인터가 필요. weak_ptr<> // s로 시작 하는 스마트 포인터는 모두 참조 계수 개체 // w로 시작 하는 스마트 포인터는 weak 참조 int main() { shared_ptr<Node2> p1(new Node2); shared_ptr<Node2> p2(new Node2);
p1->next = p2; p2->next = p1; }
일반 포인터가 아닌 weak_ptr<>을 써야 하는 이유 #include "show.h" #include <memory>
int main() { int *p = 0;
weak_ptr<int> wp; { shared_ptr<int> sp(new int);
cout << sp.use_count() << endl; // 1
p = sp.get(); wp = sp;
cout << sp.use_count() << endl; // 1 } // shared_ptr<int> sp(new int); 자원 파괴 됨.
cout << p << endl; // 이 경우 [자원]은 파괴 되었지만, 일반포인터 p가 [주소]는 계속 가지고 있음. // p는 [자원]이 진짜 살아 있는지 아닌지 알 수 있는 방법이 없음.
// 해결책: // wp는 자원뿐만 아니라, 참조개수관리객체도 가리키게 됨. // wp가 하나라도 살아 있으면 [자원 객체]는 파괴되더라도 [참조개수관리객체]는 살아 있게 됨. // weak_ptr<>를 사용시 자원이 파괴 되었는지 알 수 있다.
cout << wp.use_count() << endl; // 0 : [자원]이 파괴 되었음을 알 수 있음. // make_shared여도 역시 가능.
// 진짜 중요한 것은 아래와 같이 쓸 수 있느냐? 절대 안됨. 멀티 쓰레드 환경에서는 문제가 됨. #if 0 if (wp.use_count() > 0) { // 여기가 true이다가 다른 쓰레드에 의해서 파괴되는 경우. // 자원이 살아 있다고 판단하고 사용 하는 경우 wp->멤버 호출(); // 이 시점에는 false 일 수 있다. } #endif // 때문에 wp는 ->연산자를 지원하지 않는다. // 즉, 자원 접근을 허용하지 않는다 !!!
// weak_ptr<>로 shared_ptr<>을 다시 [생성]해야 합니다 !! shared_ptr<int> sp2 = wp.lock(); // 여기 실행되기 전에 죽으면 상관 없으나, [자원]이 있었으면 다른 thread에 의해서 파괴될 수 없다. // 기 자원이 파괴된 경우는 sp2는 0; // lock이 참조개수의 thread safe을 보장 한다. wp.lock()은 shared_ptr<>을 하나 생성해서 넘겨 준다.
// Android는 wp.promote(); if (sp2 == 0) cout << "자원 파괴 됨" << endl; else cout << "자원 사용 가능" << endl;
}
쓰레드와 스마트 포인터가 섞여 있을 때 문제 점 #include "show.h" #include <memory> #include <windows.h>
// cafe.naver.com/cppmaster 예전 수업 자료실에서 "키캣" 검색해서 받아 보기 // core/core/libutils/thread.cpp
class MyThread : public Thread { int data; public: virtual void threadMain() { data = 10; cout << "my thread" << endl; } };
int main() { { shared_ptr<MyThread> p(new MyThread); p->run(); } // 이 블럭을 벗어나는 순가 p는 destory 됨. 반면 thread는 동작 중. // 쓰레드 객체의 수명을 쓰레드가 죽을 때까지 이어야 한다. // 그 방법?
// 참조 계수를 줄여 준다. mHoldSelf은 더이상 [자원] 참조하지 않는다. 참조계수를 무조건 0으로 만드는 것은 아님 self->mHoldSelf.reset(); return 0; }
virtual void threadMain() {} };
class MyThread : public Thread { int data; public: virtual void threadMain() { data = 10; cout << "my thread" << endl; } ~MyThread() { cout << "~MyThread" << endl; } };
int main() { { shared_ptr<MyThread> p(new MyThread); p->run(p); } // 이 블럭을 벗어나는 순가 p는 destory 됨. 반면 thread는 동작 중. // 쓰레드 객체의 수명을 쓰레드가 죽을 때까지 이어야 한다. // 그 방법?
// 삭제자 전달 방법 int main() { // 삭제자 전달 : 템플릿 인자로 전다 // 장점 : 삭제자를 별도로 보관할 필요가 없고, 인라인 치환된다. // 단점 : 삭제자가 다르면 다른 타입이 된다. 같은 컨테이너에 보관이 안된다. unique_ptr<int> p1(new int); unique_ptr<int, Freer> p2((int*)malloc(100)); // unique_ptr은 관리 객체가 없음. 삭제자 지정 방법 필요 ==> template인자로 전달. // 탬플릿 인자가 다르면 다른 타입이다.
// shared_ptr<int> p3((int*)malloc(100), foo); // 관리 객체에는 삭제자 정보도 보관. // shared_ptr은 왜 다르게 쓰나 ? 삭제자가 다르면 다른 타입이 되기 때문에 함께 vector같은 자료 구조로 묶을 수 없다. // shared_ptr<int> p3((int*)malloc(100), foo);
unique_ptr<int[]> p3(new int[10]); // new T[] 형태면 템플릿 파라미터에 T[]를 넘겨 준다. }
#include "show.h" #include <memory>
int main() { shared_ptr<int> sp1(new int); unique_ptr<int> up1(new int);
// 다음 중 에러를 모두 골라 보세요 shared_ptr<int> sp2 = up1; // ERROR unique_ptr 자원을 공유 하게 되기 때문에 안됨. unique_ptr<int> up2 = sp1; // ERROR 나 말고도 다른 놈도 있기 때문에 안됨.
shared_ptr<int> sp3 = move(up1); // OK : move로 독점권을 포기하는 것이기 때문에 안됨. unique_ptr<int> up2 = move(sp1); // ERROR 나 뿐만 아니라, 다른 놈도 가르키고 있을 수 있기 때문에 안됨. }
쓰레드
#include "show.h" #include <chrono> using namespace chrono;
int main() { //thread t(bind(&foo, 1, 3.4)); // 스레드 바로 실행 됨. //thread t(&foo, 1, 3.4); // 스레드 바로 실행 됨. c++11 가변인자 템플릿으로 인해 가능 함.
// thread t(FOO()); // ERROR 임시 객체 못 받음.
FOO f; //thread t(f); // ERROR 임시 객체 못 받음.
thread t(bind(&FOO::goo, &f)); // bind가 인자 고정뿐만 아니라, 객체 고정도 가능하다. t.join(); // 자식 스레드가 죽을 때까지 기다려 줌. 안기다리면 crash. }
#include "show.h" #include <chrono> using namespace chrono;
#include <thread> #include <mutex> mutex m; long x = 10;
void foo() { m.lock(); x = 100; // 여기서 exception이 난다면 ? C++에서는 mutex중 exception나면 deadlock m.unlock(); }
void foo2() { lock_guard<mutex> lg(m); // lock_guard 생성자에서 m.lock하고 소멸자에서 unlock. x = 100; } // C++에서는 코드 플로우 중 exception 발생하면, 로컬 변수는 destroy 한다. // 즉, try{ } 안에 선언된 lock_guard는 catch에 도달할 때 destroy 됨이 보장 된다. // Android Framework에서는 lock_guard에 상당하는 Autolock 클래스 지원.
int main() { thread t1(&foo2); thread t2(&foo2);
t1.join(); t2.join(); }
begin #include <iostream> #include <vector> #include <algorithm>
using namespace std;
#if 0 // 일반 함수 begin template<typename T> auto begin(T&c) { return c.begin(); } template<typename T> auto end(T&c) { return c.end(); }
template<typename T, int N> auto begin(T (&c)[N]) { return c; } // T (&c)[N] 배열 의미 template<typename T, int N> auto end(T (&c)[N]) { return c+N; } #endif
// c.begin() 대신 begin(c)를 쓰라. 그러면 포인터도 처리 가능. C++11부터 지원 template<typename T> void show(T& c) { auto p = begin(c); while (p != end(c)) { cout << *p << " "; ++p; } cout << endl; }
int main() { vector<int> v = { 1,2,3,4,5 }; show(v);
People(string name = "", int a = 0) : name(n), age(a) {}
};
int main() { set<People> s1; s1.insert(People("kim", 10)); // set은 크기 비교 tree다. 거기에 People을 추가하려면, 비교 방법이 필요 함. // 방법1. People에 < 연산자가 필요하다. // 방법2. set<People, PeopleComparee> 등으로 비교함수 객체가 있으면 된다. // 순위는 방법2번이 우선 순위가 높다. 2가 있으면 2로 대체 된다.
int main() { unordered_set<People, PeopleHash, PeopleEqual> s1; s1.insert(People("kim", 10)); // 되게 하려면 ?? s1.insert(People("m", 30)); s1.insert(People("park", 40));
// 만약에 unordered_set<People> s2; }
/* 중요 !!! 기본 개념. template<typename T> class stack{}; // 임의의 타입에 대해 클래스 찍어 냄. (1) primary template template<typename T> class stack<T*>{}; // 모든 타입은 1번. 포인터일때는 이것 사용. (2) 부분 전문화(특수화, 특화). partial specialization // 더블 포인터도 여기 탄다. template<> class stack<int>{}; // int일때는 이것 사용. (3) 전문화(특수화, 특화) 버전 specialization
stack<double> s1; stack<int*> s2; stack<int> s2;
*/
알고리즘
#include "show.h" // 100여개 알고리즘.
// 핵심 1: remove() 등의 알고리즘은 컨테이너 자체의 크기를 줄이지는 않음. 삭제가 아님. 리턴 값만 알려줌 !! int main() { vector<int> v = { 1, 2,3,4, 5, 3, 7, 8, 3, 10 }; vector<int>::iterator p = remove(v.begin(), v.end(), 3); // 주어진 범위에서 3을 찾아서 삭제. list, vector, deque, 배열도 됨. // 컨테이너를 줄이지는 않음. 나머지 요소를 앞으로 당겨 옴. // p는 유효한 값 [다음] 위치를 돌려 줌.
show(v); cout << *p << endl;
v.erase(p, v.end()); // 여기서 실제 지우는 동작 함 ! show(v); }
#include "show.h" // 총 4가지 변형이 존재 한다 : remove, remove_if, remove_copy, remove_copy_if
using namespace std::placeholders; int main() { vector<int> v = { 1, 2,3,4, 5, 3, 7, 8, 3, 10 }; vector<int> v2(10);
// 알고리즘의 4가지 변경. // vector<int>::iterator p = remove(v.begin(), v.end(), 3); // (1) 상수 버전 // vector<int>::iterator p = remove_if(v.begin(), v.end(), foo); // (2) 조건자 버전 (함수) // vector<int>::iterator p = remove_if(v.begin(), v.end(), bind(modulus<int>(), _1, 2)); // (2) 조건자 버전(함수 객체) // vector<int>::iterator p = remove_if(v.begin(), v.end(), [](int a) { return a % 2 == 0;}); // (2) 조건자 버전(람다) //v.erase(p, v.end());
// (3) 알고리즘의 복사 버전. vector<int>::iterator p = remove_copy(v.begin(), v.end(), v2.begin(), 3); // loop가 1회만 돈다. copy + remove 해도 되나 그보다 빠르다. // 여기서 p는 v2의 반복자 // 반면, sort + copy는 성능차이가 많이 나기 때문에 sort_copy가 없다. // show(v);
//show(v2); //v2.erase(p, v2.end()); //show(v2);
// (4) 조건자 복사 버전 vector<int>::iterator p = remove_copy_if(v.begin(), v.end(), v2.begin(), [](int a) { return a % 2 == 0;}); }
#include "show.h"
int main() { int x[5] = { 1, 2, 3,4, 5 }; int *p1 = find(x, x + 5, 3); // 상수 버전 int *p2 = find_if(x, x + 5, [](int a) {return a % 2 == 0;}); // 조건자 버전 cout << *p2 << endl;
sort(x, x + 5); // < 연산으로 비교 sort(x, x + 5, greater<int>()); // >로 비교 // sort냐 sort_if냐 ? 왜 sort냐? find는 find_if는 같은 인자개수. // 조건자 버전이라도 parameter overloading 가능 하면 그대로 쓴다. }
find(x, x + 5, 3); // 내부 구조 안바뀜. (1) 변경 불가 sequence 알고리즘. reverse(x, x + 5); // 내부 구조 바뀜. (2) 변경 가능 sequence 알고리즘. sort(x, x + 5); // (3) 정렬 알고리즘.
int n = accumulate(x, x + 5, 0); // (4) 범용 수치 알고리즘. cout << n << endl; }
#include "show.h" #include <numeric>
// 범용 수치 알고리즘은 연산자를 바꿀 수 있다. int main() { int x[5] = { 1,-2,3,4,5 }; int y[5] = { 0 }; int z[5] = { 0 };
int n = accumulate(x, x + 5, 0); // 기본 버전 : + 사용 int n2 = accumulate(x, x + 5, 1, multiplies<int>()); // * 사용 1~5까지의 곱 = 5! int n3 = accumulate(x, x + 5, 0, [](int a, int b) {return abs(a) + abs(b);}); // abs cout << n3 << endl;
//partial_sum(x, x + 5, y); partial_sum(x, x + 5, y, multiplies<int>()); for (int i = 0; i < 5; i++) cout << y[i] << " "; }
// www.boost.org : 표준과 별도의 라이브러리 만들어보자. // 아무도 이해할 수 없다 ㅠ;
#include "show.h" #include <numeric>
int main() { vector<int> v = { 1, 2, 3,4, 5 }; vector<int>::iterator p = copy(v.begin() + 1, v.end(), v.begin());
// 예전엔 전부 1일 나왔음. 현재는 뒤에서부터 옴김. // 때문에 예전엔 vector<int> v3 = { 1, 2, 3, 4, 5 }; copy_backward(v3.begin(), v3.end() - 1, v3.end()); show(v3);
string s = "ABCD"; do { cout << s << endl; } while (next_permutation(s.begin(), s.end())); }
WebKit이나 Chromium에 쓰이는 RefCounted는 아예 RefCount<>를 상속 받아서 쓴다. http://www.suninf.net/2013/11/refcounted-in-chrome.html template<classT>classRefCounted;classMyFoo:publicbase::RefCounted<MyFoo>{protected:~MyFoo(){}friendclassbase::RefCounted<MyFoo>;};
많은 개발자들은 순환 참조(Dependency Circles)가 해롭다는 것은 모두 다 알고 있다. 그런데 자신도 모르게, 일정에 쫓기고, 귀찮아서 등등의 핑계로 오늘도 순환 참조를 만들고 있다. 일단 순환 참조를 생성하는 이유는 접도록 하겠다.
이 이야기는 시작하면 끝이 없기 때문이다.그럼 주제에 맞게 순환 참조를 어떻게 하면 끊을 수 있을까? 순환 참조는 어떻게 생겼나? 한마디로 두개의 클래스가 서로 참조하고 있는 것을 말한다. 쉽게 설명하면 A 클래스는 B 클래스를 호출하고 B 클래스는 A 클래스를 호출한다.
실무에서 이런 경우는 정말 허다하다 못해 널렸다. 해결하는 방법은 아주 쉽다. 너무 쉽다.
1. B의 메소드를 선언한 C 인터페이스는 만든다. 2. B는 C의 구현체로 한다. 3. A는 C를 의존한다. 4. B가 참조하는 A의 메소드는 유지한다.
다시 그림으로 표현하면 아래의 그림과 같이 된다.
이렇게 디자인하면 순환 참조가 없어지게 된다. 야호!!
그런데 우리가 코딩을 하다보면 순환 참조가 필요할 때가 있다. A에서 실제적으로 B의 참조가 필요한 경우를 말한다. 이럴때는 또 하나의 D 클래스를 생성해서 A와 B를 참조하여 이슈를 해결할 수 있다.
완.전.해.결! 위 그림은 우리가 이미 잘 알고 있는 Dependency Injection 이다. 이런 형태는 프레임워크가 없어도 언어 레벨에서 해결이 가능하다. 좀더 넓은 영역에서 바라본다면 클래스간 참조한다고 모두 순환 참조는 아니다. 하나의 패키지안에서 클래스간 순환 참조는 허용한다. 하지만 패키지가 다른 클래스가 참조하는 것과 Jar간 참조도 마찬가지 완전 피해자.
TYPE* p = new TYPE; shared_ptr<type> a(p); shared_ptr<type> b(p); </type></type>
이렇게 하면 a와 b가 별개로 존재하게 되죠. a의 참조 카운트가 0이 되서 객체가 사라져도 b는 그것을 모르고 여전히 유효하다고 생각해서 객체에 접근하려고 하거나 이미 지워진 객체를 또다시 지우는 댕글링 포인터 문제가 발생합니다. 이 문제를 해결하는 것이 enable_shared_from_this를 상속받아서 사용하는 것입니다. 그러나 문제가 있습니다. c++ 빌더는 VCL에서 상속받은 클래스들은 다중상속을 허용하질 않습니다. 즉 enable_shared_from_this를 상속받는 것 그 자체가 불가능하게 됩니다. 저는 제가 만든 새로운 프로그램 패러다임인 관계지향 프로그래밍을 위해서 모든 클래스에 베이스로 TSocialObject를 깔고 있는데 이것이 TObject에서 온 것이기 때문에 모든 클래스가 다중상속이 불가능한 상태입니다. 그리고 제가 열심히 테스트해본 결과 enable_shared_from_this 자체에도 문제가 있습니다.
class TYPE: public enable_shared_from_this<type> { };
class TYPE2: public TYPE, public enable_shared_from_this<type2> { }; </type2></type>
이런 식으로 말입니다. 그런데 enable_shared_from_this는 가상 클래스가 아닙니다. 내부에 멤버변수 weak_this_가 있어서 8바이트를 잡아먹습니다. 즉 모든 클래스에 enable_shared_from_this를 상속시키면 상속이 누적될수록 인스턴스에 쓸데없는 쓰레기 메모리 8바이트가 계속 추가로 생긴다는 문제입니다. 이걸 피하기 위해서 베이스 클래스에서 한번만 멤버변수를 정의하면 상속받은 클래스에서도 계속 사용할 수 있어야만 한다고 생각했습니다.
즉 다중상속이 되지 않아도 쓸 수 있어야 하고 베이스 클래스에서 한번만 정의하면 쓸 수 있도록 한다.. 정말 어려운 조건이었습니다만 해냈습니다. ㅎㅎ... 물론 타입을 무시하고 억지로 스태틱 캐스팅을 하기 때문에 감히 권할만한 코드는 아닙니다. 그리고 enable_shared_from_this 처럼 자동으로 백그라운드에서 동작이 이뤄지질 않습니다. 제가 boost 코드를 함부로 고칠 수가 없기 때문입니다. 그러나 동작에는 아무런 문제가 없습니다. 버그도 없습니다.
구현방법은 2가지가 있습니다. 첫번째 방법은 자동으로 초기화가 이뤄집니다. 클래스 선언에다가 매크로만 추가해주면 그걸로 작업은 끝이고 개발자가 수동으로 초기화 함수같은걸 호출할 필요가 없습니다. 그러나 이 방법은 오직 shared_from_this() 함수를 사용할 수 있게만 합니다. shared_from_this()로 생성된 shared_ptr은 별개의 트리로 존재하기 때문에 제가 맨위에 설명했던 문제점은 그대로 존재하게 됩니다.
class test { BASE_ENABLE_SHARED_FROM_THIS(test) };
class test2 : public test { ENABLE_SHARED_FROM_THIS(test2) };
이렇게 하면 끝입니다. shared_from_this()를 자유롭게 사용할 수 있습니다. 그러나 이 방법보다 더 개선된 두번째 방법이 있습니다. 두번째 방법은 근본적으로 boost 라이브러리 안의 enable_shared_from_this가 사용하는 방법을 흉내낸 것입니다. 다만 shared_ptr 자체의 소스를 건드릴 수 없기 때문에 사용하는 방법에 제약이 가해집니다. 특정한 방법으로 사용해야만 됩니다.
BASE_ENABLE_SHARED_FROM_THIS과 ENABLE_SHARED_FROM_THIS 이 2개의 매크로를 사용하는 것은 똑같습니다. 그러나 이제 new를 사용하면 안됩니다. 대신 만든 NEW 매크로를 사용해서 인스턴스를 생성해야만 합니다. NEW매크로는 인스턴스 안의 weak_this_ 멤버변수 초기화도 함께 합니다. NEW매크로만 써주시면 enable_shared_from_this 를 사용하는 것과 똑같은 수준으로 shared_ptr 관리가 됩니다.
단 주의하실 것이 있습니다. 첫번째 구현방법은 초기화가 자동이기 때문에 new로 만들지 않은 객체에서도 shared_from_this()를 사용할 수 있었습니다. 그러나 두번째 구현방법은 new로 만든 객체만 shared_from_this()를 쓸 수 있습니다. 제가 만든 것뿐만 아니라 boost 라이브러리가 제공하는 enable_shared_from_this 역시 new로 만든 객체에서만 shared_from_this()를 사용할 수 있는건 마찬가지입니다. 제가 못해서 그런게 아니니까 이해해 주시길...
shared_ptr은 정말 좋은 클래스입니다. 이걸 본격적으로 쓰면 C++로도 자바처럼 메모리에 대해 신경 안쓰고 코딩하는게 완전히 가능하겠더군요. 여러분도 shared_ptr의 세계로 빠져들어보세요. 오랫만에 c++에 푹 빠져봤습니다. 맨날 c만 하다가 c++ 코딩 본격적으로 다시 해본게 7년? 8년만이군요.. 그럼 수고하세요.